-
机器学习-期末复习
本文的内容按照作者的课程考试要求书写,仅供复习参考。🌷🌷🌷欢迎大家指正!
机器学习是一种人工智能(AI)的分支领域,它致力于开发能够通过数据学习和改进的算法和模型。简而言之,机器学习系统利用数据来识别模式、进行预测或者做出决策,而无需明确地编程规则。这些系统通过从数据中学习并自动调整其行为来提高性能,从而实现了自我改进和适应。
机器学习:通过算法使得机器能从大量数据中学习规律从而对新的样本做决策。二分类线性模型的决策边界
在二分类问题中,由于输出目标 𝑦 是两个离散的标签,而 𝑓(𝒙; 𝒘, b) 的值域为实数,因此无法直接用 𝑓(𝒙; 𝒘) 来进行预测,需要引入一个非线性的激活函数(决策函数) 𝑔(⋅)来预测输出目标,决策函数(常用的是sigmoid函数)的作用是将模型的连续输出映射到两个离散标签中的一个。

证明:为什么决策平面与权重向量w正交
参考链接:csdn

Logistic Regression将二分类问题看作条件概率估计问题
Logistic函数

Logistic回归
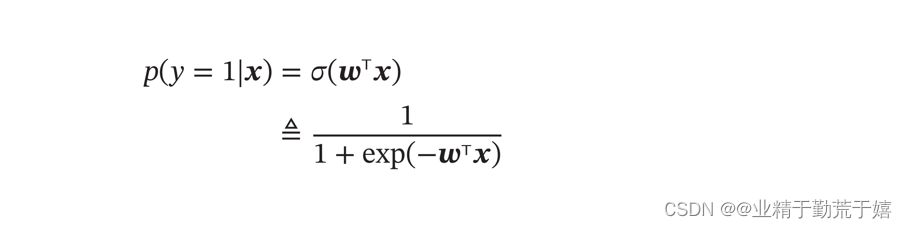
KL散度和交叉熵损失

KL散度(Kullback-Leibler Divergence)是衡量两个概率分布之间差异的一种方式。它表示的是两个概率分布P和Q之间的信息损失。当P和Q越接近时,KL散度越小;反之,当P和Q差异越大时,KL散度也越大。因此,KL散度可以用来量化模型预测的概率分布与实际概率分布之间的差异。

交叉熵损失(Cross-Entropy Loss)则是在机器学习和深度学习中常用的一个损失函数。它主要用来衡量模型预测的概率分布与真实标签之间的差异。在分类问题中,真实标签通常是一个one-hot编码的向量,而模型预测的是每个类别的概率。交叉熵损失通过计算预测概率与真实标签之间的差异,指导模型在训练过程中不断优化,以减小预测误差。

感知器
感知器学习算法也是一个经典的线性分类器的参数学习算法.感知器是一种二元分类器,它试图通过调整权重和阈值来根据给定的输入数据做出正确的分类决策。当感知器接收到一个错误样本,即其分类结果与预期不符时,它就知道当前的权重和阈值配置并不理想,因此需要进行调整。
这种调整的过程实际上是一种优化过程,感知器试图通过最小化分类错误来找到最佳的权重和阈值。具体来说,当感知器对某个样本的分类结果错误时,它会计算这个错误导致的损失(即交叉熵损失或其他类似的损失函数),然后根据这个损失来调整权重。这种调整通常是基于梯度下降或其变种算法进行的,目的是使损失函数最小化。
为什么要用错误样本来更新权重?
当感知器网络接收到一个错误分类的样本时,这意味着当前的网络权重未能正确地将该样本映射到其应属的类别。此时,网络就需要根据这个错误来调整其权重,以减小未来犯同样错误的可能性。具体来说,感知器网络会计算该错误样本的预测输出与实际输出之间的差异(即误差),然后根据这个误差来更新权重。这种更新通常是沿着误差的负梯度方向进行的,目的是使网络的输出更接近实际标签,从而提高分类的准确性。卷积神经网络
首先明确一个概念,卷积核就是滤波器。
卷积核(或滤波器)是一个小的矩阵,通常具有较小的维度(如3x3或5x5),它会在输入数据(如图像)上滑动,执行卷积操作以提取特征。每个卷积核都会学习捕捉输入数据中的某种特定模式或特征。
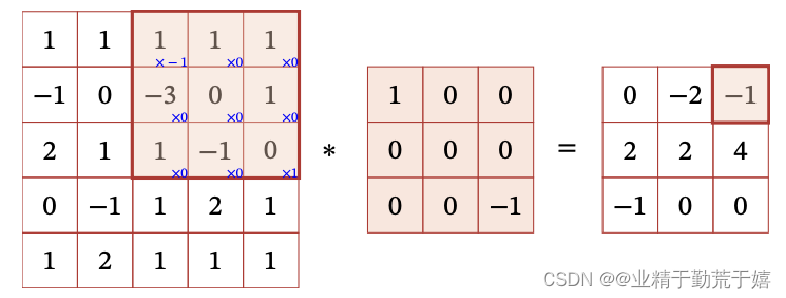
滑动步长和零填充
步长(Stride)是指卷积核在滑动时的时间间隔
零填充(Zero Padding)是在输入向量两端进行补零零填充的目的:
保持空间尺寸:当卷积核的大小大于输入图像的大小时,通过零填充可以避免卷积操作后图像尺寸的减小。这有助于确保卷积后的图像大小不变,方便后续的操作。
调整输出大小:零填充还可以用于调整输出的空间大小。通过补零,可以在保持输出空间大小不变的情况下将输出传入下一层。如果不进行零填充,每次卷积操作后输出的空间都可能缩小,当输出的大小变得过小(如大小为1)时,就无法再进行卷积操作了。
解决边界效应:在处理离散量时,卷积操作可能会产生边界效应,即相邻周期之间的干扰。这种干扰可以通过补零的方法来避免,确保空间和循环卷积给出相同的结果。卷积运算的参数量
输出尺寸 = (输入尺寸 - 卷积核尺寸 + 2 * 零填充) / 步长 + 1

Inception网络
1x1卷积核的作用

补充:1x1卷积核实现升维/降维的原理如果输入数据格式为MN10,MN为数据矩阵,10为通道数,如果希望输出数据格式为MN5,使用5个11*10的卷积核即可。
这个过程是先降维再升维,通道数都为10,可以理解为没办法在深度方向上进行滑动,所以卷积运算之后的通道数变为1。序列建模
从机器学习的角度来看:语言模型是对语句的概率分布的建模。
N-gram模型:减少历史基元的个数
当 n=1 时,即出现在第 i 位上的基元 wi 独立于历史。 一元文法也被写为 uni-gram 或 monogram;
当 n=2 时,即出现在第 i 位上的基元 wi 仅依赖于wi -1,2-gram (bi-gram) 被称为1阶马尔可夫链;
当 n=3 时,即出现在第 i 位上的基元 wi 依赖于{wi -1、 wi -2},3-gram(tri-gram)被称为2阶马尔可夫链,依次类推。
例如,给定训练预料:
“John read Moby Dick”
“Mary read a different book”
“She read a book by Cher”
根据 2-gram文法求句子的概率?
句子:John read a book
计算的概率类似于条件概率,要注意所求句子和预料里面的单词的前后关系
注意: < BOS >是第一个单词前面的位置 < EOS >是最后一个单词后面的位置
计算过程为:

注意力机制
注意力,对于我们人来说可以理解为“关注度”,对于计算机来说其实就是赋予多少权重(比如0-1之间的小数),越重要的地方或者越相关的地方就赋予越高的权重。
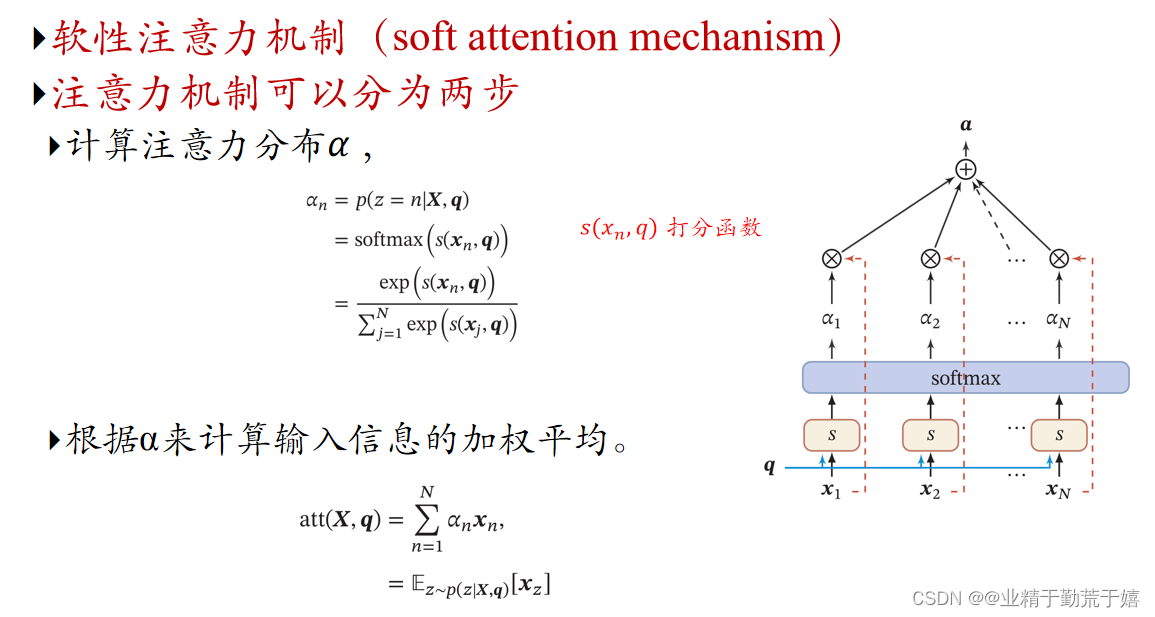
注意力模型的基本实现过程如下:
1.计算注意力权重:对于每个输入序列中的元素,模型会计算一个与之对应的注意力权重。这个权重通常基于输入元素和当前要生成的输出元素之间的相关性或匹配程度。
2.加权求和:使用计算出的注意力权重对输入序列进行加权求和,得到一个上下文向量(context vector)。这个上下文向量包含了模型在生成当前输出时需要关注的信息。
3.生成输出:最后,模型使用上下文向量和其他相关信息来生成输出。补充:softmax函数
softmax函数是一种将原始分数转换为归一化概率分布的方法。它通常用于多分类问题的输出层,以确保模型的输出是一个有效的概率分布。
softmax函数的实现过程如下:
1.计算原始分数:对于每个可能的类别,模型会计算一个原始分数(通常是模型最后一层的输出)。
2.应用Softmax函数:将每个原始分数转换为概率值。Softmax函数通过指数化原始分数并对其进行归一化来实现这一点。具体来说,对于每个原始分数xi,其对应的概率值pi是通过以下公式计算的:
pi = e^xi / Σj e^xj,其中,Σj e^xj是所有类别原始分数的指数和。
3.输出概率分布:最终,Softmax函数会输出一个概率分布,其中每个类别的概率值都在0和1之间,且所有类别的概率值之和为1。模型的优化和正则化
BN的主要思想是在网络的每一层的激活函数之前,对激活函数的输入进行归一化处理,使其分布在均值为0、方差为1的范围内,然后再进行平移和缩放。


BN带来的好处
1.减轻了对参数初始化的依赖,有利于调参。
2.训练更快,可以使用更大的学习率。
3.BN一定程度上增加了泛化能力BN存在的问题
BN依赖于批的大小,当批量很小时,估计的均值和方差不稳定。因此BN不适合如下场景:
批量非常小,比如训练资源有限无法设置较大的批量,也比如在线学习等使用单例进行模型参数更新的场景。
循环神经网络,因为它是一个动态的网络结构,同一个批中训练实例有长有短,导致每一个时间步长必须维持各自的统计量,这使得BN并不能正确的使用。 -
相关阅读:
设计模式详解(十七)——迭代子模式
MyBatisPlus-乐观锁概念及实现步骤
Python FastApi 解决跨域及OPTIONS预请求处理
Vue解决导出pdf文件图片展示不全问题
【JavaScript 进阶教程】非 extends 的组合继承
横向扩展统一存储备份解决方案的特点与优势
MongoDB系列之适用场景和不适用场景
产品创新设计:品牌价值提升的主要途径
C#获取一个固定范围内的随机数
C语言学习概览(二)
- 原文地址:https://blog.csdn.net/ZTBztb123456/article/details/138071154