-
Vision Transformer (ViT)的原理讲解与后续革新【附上pytorch的代码!】
Vision Transformer (ViT)详解
一、背景介绍
Vision Transformer (ViT)是Google团队在2020年提出的一种新型图像分类模型,它成功地将Transformer架构应用于视觉领域。通过将图像分割成多个patch并送入Transformer编码器处理,ViT模型能够在大规模数据集上实现卓越的性能,超越了传统的CNN模型。本文将详细解析ViT模型的工作原理、关键组件以及代码实现。以新手的身份来谈谈自己的理解。
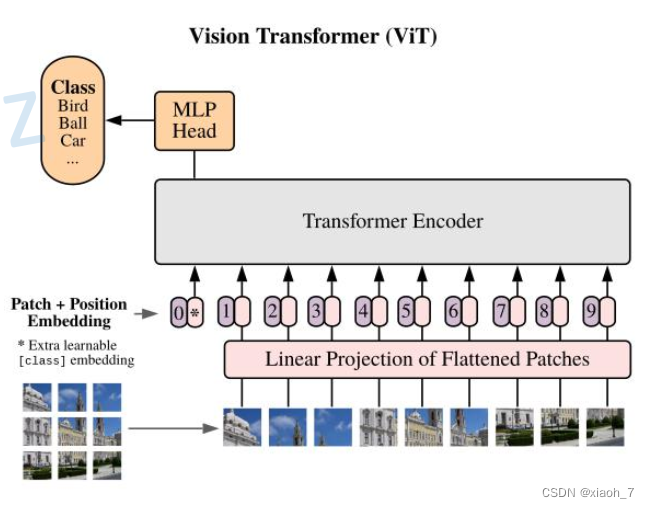
二、相关工作
Transformers最初由Vaswani等人提出,用于机器翻译任务,并随后在多个NLP任务中取得了显著成果。这些基于大型Transformers的模型通常首先在大型语料库上进行预训练,然后根据具体下游任务进行微调。ViT模型借鉴了这种预训练与微调的策略,将其应用于图像分类任务中。
三、方法
-
图像块嵌入 (Patch Embeddings)
ViT模型首先将输入图像分割成一系列固定大小的patch(例如16x16像素)。然后,每个patch通过线性层转换为固定长度的向量,这些向量将作为Transformer编码器的输入。 -
可学习的位置嵌入 (Learnable Position Embeddings)
由于Transformer模型本身不具有处理序列位置信息的能力,因此ViT引入了可学习的位置嵌入来弥补这一缺陷。位置嵌入是一个与patch嵌入维度相同的向量表,其中每一行代表一个位置向量。通过将位置嵌入与patch嵌入相加,模型能够捕捉到图像中不同位置的信息。

-
Transformer 编码器
ViT模型的核心组件是Transformer编码器,它负责处理经过嵌入的图像块序列。Transformer编码器由多个堆叠的编码器层组成,每个编码器层包含自注意力机制和前馈神经网络。通过多层堆叠,模型能够捕捉到图像中的多层次信息。

# MHA class Attention(nn.Module): def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.): super().__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = qk_scale or head_dim ** -0.5 self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) self.attn_drop = nn.Dropout(attn_drop) self.proj = nn.Linear(dim, dim) # 附带 dropout self.proj_drop = nn.Dropout(proj_drop) def forward(self, x): B, N, C = x.shape qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple) attn = (q @ k.transpose(-2, -1)) * self.scale attn = attn.softmax(dim=-1) attn = self.attn_drop(attn) x = (attn @ v).transpose(1, 2).reshape(B, N, C) x = self.proj(x) x = self.proj_drop(x) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
-
归纳偏置与混合架构
与CNN模型相比,ViT模型摒弃了卷积操作,完全依赖于自注意力机制来处理图像块序列。这种设计使得ViT能够捕捉到图像中的全局信息,并在大规模预训练后在多个图像识别任务中取得优异的结果。同时,一些研究也探索了将CNN与Transformer相结合的混合架构,以进一步提升模型性能。 -
微调及更高分辨率
在预训练阶段,ViT模型通常在大规模数据集上进行训练,以学习通用的视觉特征。然后,针对具体的下游任务(如图像分类、目标检测等),可以通过微调来使模型适应任务需求。此外,为了适应更高分辨率的输入图像,可以采用插值等方法对patch嵌入进行调整。 -
超参数调整
在训练ViT模型时,学习率是一个关键的超参数。适当的学习率可以加速模型的收敛速度并提升性能。因此,在训练过程中需要对学习率进行细致的调整和优化。
四、实验
为了验证ViT模型的有效性,原文在多个图像分类数据集上进行了实验。实验结果表明,ViT模型在大规模数据集上取得了显著的性能提升,并且在微调后能够很好地适应不同的下游任务。

五、后续相关工作
Vision Transformer(ViT)无疑是近年来计算机视觉领域的一项重大突破,其将Transformer架构成功引入图像识别任务,为处理大尺寸图像和长序列数据提供了一种全新的视角。自ViT模型问世以来,其在图像分类、目标检测等多个任务上均取得了卓越的性能,为计算机视觉领域的发展注入了新的活力。
在ViT的基础上,后续的研究工作主要围绕模型优化、性能提升以及跨领域应用展开。首先,针对ViT模型参数量和计算量较大的问题,研究者们通过改进模型架构,引入残差注意力模块等方法,有效地减少了模型的参数量和计算量,同时提升了模型的性能。这些改进不仅使得ViT模型在处理大规模数据集时更加高效,还增强了模型对平移不变性的鲁棒性。
其次,随着预训练技术的发展,研究者们开始探索ViT模型的预训练方法和微调技术。通过在大规模数据集上进行预训练,ViT模型能够学习到更加丰富的视觉特征,从而提高了其在下游任务中的性能。此外,跨模态应用也是ViT模型发展的重要方向之一。通过将图像和文本数据相结合,研究者们构建了一种基于ViT的跨模态模型,用于图像和文本的分类和生成等任务。这种跨模态应用不仅拓展了ViT的应用范围,也为计算机视觉和自然语言处理之间的交互提供了新的思路。ViT模型还在实时性应用和多任务学习等领域展现出巨大的潜力。通过将ViT与轻量级神经网络相结合,研究者们构建了一种高效的实时性目标检测系统,用于监控和安全等领域。同时,为了进一步提高ViT的性能和应用范围,研究者们还尝试了将ViT应用于多任务学习中,通过共享底层特征和信息交互,实现了多个任务的同时优化。参考资料
论文:Vision Transformer
博客:Vision Transformer详解版权声明
本博客内容仅供学习交流,转载请注明出处。
-
-
相关阅读:
三、python Django ORM 数据库[表单增删、多数据库、数据库内容保存转移]
链表之头指针、头结点、首元结点、空链表
Java之HikariCP数据库连接池浅入浅出
使用ffmpeg解码音频sdl(pull)播放
Pre-trained Language Models Can be Fully Zero-Shot Learners
Confluence OGNL注入漏洞复现(CVE-2022-26134)
简单讲讲RISC-V跳转指令基于具体场景的实现
docker搭建drone
互联网社交礼仪:我到底该怎么笑才对
WhatsApp群发系统-SendWS拓客系统功能后台介绍(五):WhatsApp筛号群发,群发超链
- 原文地址:https://blog.csdn.net/xiaoh_7/article/details/138168106
