-
多模态模型
转换器成功作为构建语言模型的一种方法,促使 AI 研究人员考虑同样的方法是否对图像数据也有效。 研究结果是开发多模态模型,其中模型使用大量带有描述文字的图像进行训练,没有固定的标签。 图像编码器基于像素值从图像中提取特征,并将其与语言编码器创建的文本嵌入相结合。 整体模型封装了自然语言标记嵌入和图像特征之间的关系,如下所示:

Microsoft Florence 模型就是这样的模型。 此模型使用来自互联网的大量带有描述文字的图像进行训练,包括语言编码器和图像编码器。 Florence 是基础模型的一个例子。 换句话说,它是一个预先训练的通用模型,你可以基于此模型为专业任务构建多个自适应模型。 例如,可以将 Florence 用作执行以下操作的自适应模型的基础模型:- 图像分类:标识图像所属的类别。
- 物体检测:查找图像中的单个物体。
- 字幕:生成图像的相应说明。
- 标记:编译图像的相关文本标记列表。
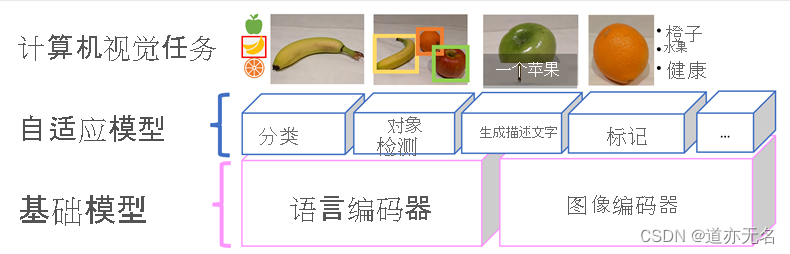
Florence 等多模态模型普遍处于计算机视觉和 AI 的前沿,并有望推动 AI 使各种解决方案成为可能。
-
相关阅读:
表单提交,页面滚动到必填项位置
JavaIO系列——常见字符编码,字符流抽象类,FileReader,FileWriter
NLP中的对抗训练(附PyTorch实现)
数字IC前端笔试常见面试问题整理
学生宿舍管理系统(前端java+后端Vue)实现-含前端与后端程序
蓝桥杯青少组(Python组)考核知识范围
AGI 之 【Hugging Face】 的【问答系统】的 [构建问答系统] / [ 构建基于评论的问答系统 ] 的简单整理
人文社科类夏校推荐合集
JVM高频知识点总结【3】
超声功率放大器在MEMS超声测试中的应用
- 原文地址:https://blog.csdn.net/u011046042/article/details/138137975