为什么需要 CNI#
在 kubernetes 中,pod 的网络是使用 network namespace 隔离的,但是我们有时又需要互相访问网络,这就需要一个网络插件来实现 pod 之间的网络通信。CNI 就是为了解决这个问题而诞生的。CNI 是 container network interface 的缩写,它是一个规范,定义了容器运行时如何配置网络。CNI 插件是实现了 CNI 规范的二进制文件,它可以被容器运行时调用,来配置容器的网络。
Docker 网络#
基础#
计算机五层网络如下:

如果我们想把 pod 中的网络对外,首先想到的就是七层代理,比如nginx,但是我们并不知道 pod 里的网络一定是 http,甚至他可能不是tcp。所以我们像做一些网络操作,就不能在五层做了,只能在二三四层做。
Docker 实验#
当我们在物理机上启动 docker daemon 不需要启动任何容器的时候,使用 ip a 命令查看网卡,发现多了一个 docker0
4: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:9b:65:e1:01 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
docker0 是一个 linux Bridge 设备,这个可以理解成一个虚拟的交换机,用来做二层网络的转发。当我们启动一个容器的时候,docker 会为这个容器创建一个 veth pair 设备,一个端口挂载在容器的 network namespace 中,另一个端口挂载在 docker0 上。这样容器就可以和 docker0 上的其他容器通信了。
docker run -d --rm -it ubuntu:22.04 sleep 3000
在物理机上查看 ip a
8: veth6bc75d9@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether d6:87:ca:5c:54:51 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::d487:caff:fe5c:5451/64 scope link
valid_lft forever preferred_lft forever
docker 容器里面 ip a
7: eth0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
再启动一个 docker
docker run --name test -d --rm -it ubuntu:22.04 sleep 3000
# ip a
9: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
这样两个容器就可以通过 docker0 通信了。
root@b19a3dc4b32d:/# ping 172.17.0.2
PING 172.17.0.2 (172.17.0.2) 56(84) bytes of data.
64 bytes from 172.17.0.2: icmp_seq=1 ttl=64 time=0.055 ms
通信方式#

CNI 网络#
当两个 pod 在同一 node 上的时候,我们可以使用像上述 docker 的 bridge 的方式通信是没问题的。但是 kubernetes 是这个多节点的集群,当 pod 在不同的 node 上的时候,直接通信肯定不行了,这时候我们需要一些办法来解决这个问题。
UDP 封包#
当 pod 在不同节点上的时候,两个 pod 不可以直接通信,那最简单的方式就是通过 udp 封包,把整个网络包使用 udp 封包起来,然后第二个节点再解包,然后发给网桥。
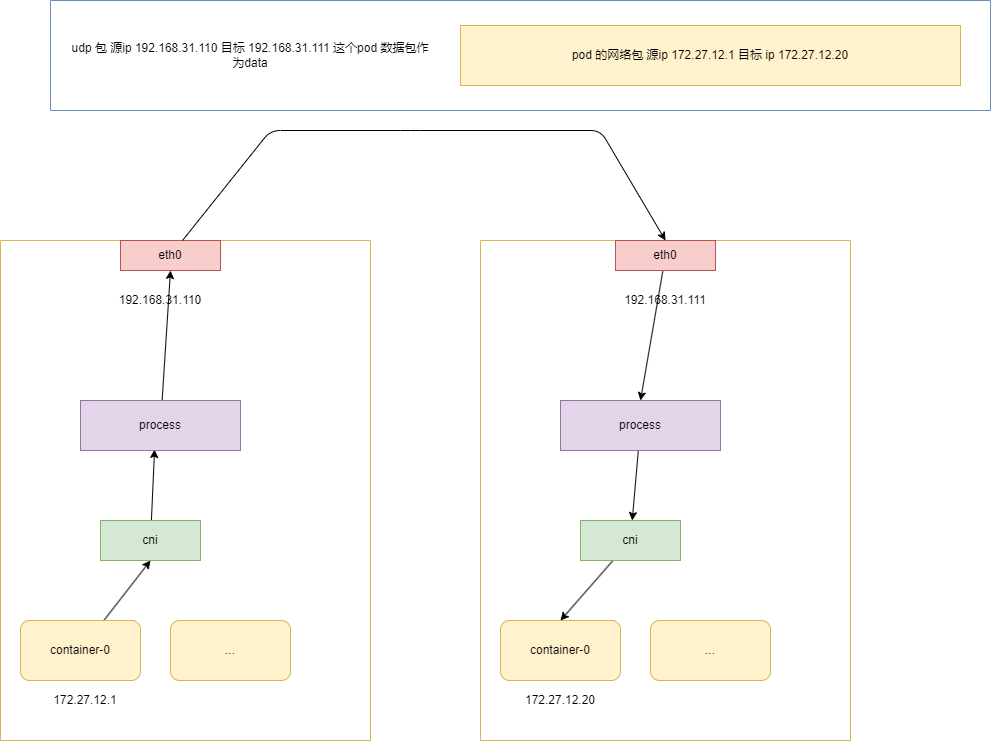
整个过程就是 node1 上的 pod 把网络包封装,然后由于 process 再封装发给 node2,node2 再解包,然后发给 pod2。
process 是 cni 实现的进程,很多 cni 都实现 udp 封包的方式,比如 flannel,cailco 等。
至于我们怎么知道目标 ip (pod 的 ip) 是在哪台主机上,这个就有很多中方式了,比如把每台机器发配 ip 分配不同的网段,甚至于把这些对应关系写到 etcd 中。
VXLAN#
上述的 udp 封包方式,是可以满足基本需求但是。cni 创建的 process 进程是一个用户态的进程,每个包要在 node1 上从内核态 copy 到用户态,然后再封包,再 copy 到内核态,再发给 node2,再从内核态 copy 到用户态,再解包,再 copy 到内核态,再发给 pod2。这样的方式效率很低。所以我们使用一种更加高效的方式,就是 vxlan。
VXLAN 是什么?
VXLAN(Virtual Extensible LAN)是一种网络虚拟化技术,用于解决大规模云计算环境中的网络隔离、扩展性和灵活性问题。VXLAN 允许网络工程师在现有的网络架构上创建一个逻辑网络层,这可以使得数据中心的网络设计变得更加灵活和可扩展。
为什么性能会高?
VXLAN 是在内核态实现的,原理和 udp 封包一样,只不过是在内核态实现的,数据包不会在内核态和用户态之间 copy,所以效率会高很多。
ip 路由#
就算是 vxlan,也是需要封包和解包的,这样的方式效率还是不够高,所以我们可以使用 ip 路由的方式。
ip 路由故名思意,就是使用路由表来实现 pod 之间的通信。这样的方式效率最高,但是配置比较复杂,需要配置路由表。
而且路由表跳转是二层网络实现的,所以又要要求所有 node 在同一个二层网络中。
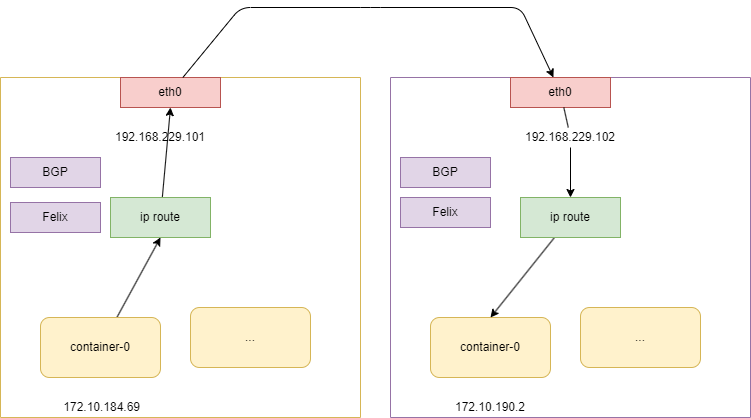
查看 node1 上的 container 的是设备
ip a
2: eth0@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 66:5e:d8:8d:86:ba brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.10.184.69/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::645e:d8ff:fe8d:86ba/64 scope link
valid_lft forever preferred_lft forever
这个和主机上是对应的是一个 veth pair 设备,一个端口挂载在容器的 network namespace 中,一边挂载在主机上。
# 主机
ip a
10: calia78b8700057@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-0da431c8-dd8b-ca68-55e6-40b04acf78d6
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
当 pod 中的数据包来到主机 查看 node1 上的路由表 会命中一下这条路由 这条的意思是跳到192.168.229.102节点使用 ens33 设备
ip r
172.10.190.0/26 via 192.168.229.102 dev ens33 proto bird
当 数据包来到 node2 上的时候 我们看下 node2 的路由表
ip r
172.10.190.2 dev calie28ee63d6b0 scope link
ip a
7: calie28ee63d6b0@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-dd892c92-1826-f648-2b8c-d22618311ca9
inet6 fe80::ecee:eeff:feee:eeee/64 scope link
valid_lft forever preferred_lft forever
这个设备是 veth pair 设备,对应的容器内的
ip a
2: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether fa:a6:2f:97:58:28 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.10.190.2/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::f8a6:2fff:fe97:5828/64 scope link
valid_lft forever preferred_lft forever
这样node2上的 172.10.190.2 pod 就可以收到数据包了。
路由跳转#
路由跳转是怎么实现的?
路由跳转是通过路由表来实现的,它作用在二层上,所以当跳转的时候,直接修改数据包的目标 mac 地址(如果知道的话是使用 ARP 协议获得)。
所以当我们访问百度的时候,获得百度的ip的时候,数据包会经过很多路由器,每个路由器都会修改数据包的目标 mac 地址,这样数据包就可以到达百度的服务器了。
Felix#
那么主机上的路由表是怎么来的呢?
这个就是 cni 的实现了,cni 会调用 felix 这个进程,felix 会根据 cni 的配置来配置路由表。
BGP#
那么 node1 怎么知道对应的 pod ip 在哪个 node 上呢?
这个就是 BGP 协议了,BGP 是一个路由协议,用来告诉 node1 对应的 pod ip 在哪个 node 上。
这个协议很重,之前都是用到互联网上,比如我们刚才距离的百度的时候,经过那么多路由器,每个路由器怎么知道要跳到哪,他们之间就是通过 BGP 协议来告诉对方自己的路由表,再经过一系列的学习优化。
ip in ip#
刚才也说过了,ip 路由是最高效的,是因为它作用在二层网络上,这就需要保证所有的 node 在同一个二层网络上。但是有时候我们的 node 不在同一个二层网络上,这时候我们可以使用 ip in ip。
简单来说就是如果 node 之间在一个二层网络上,那么就直接使用 ip 路由,如果不在,那么就使用 ip in ip,把数据包封装起来,然后再发给对应的 node。