在这篇文章中,我们来详细探讨知识图谱(KG)在RAG流程中的具体应用场景。
缘起#
关于知识图谱在现在的RAG中能发挥出什么样的作用,之前看了360 刘焕勇的一个分享,简单的提了使用知识图谱增强大模型的问答效果的几个方面:
- 在知识整理阶段,用知识图谱将文档内容进行语义化组织;
- 在意图识别阶段,用知识图谱进行实体别称补全和上下位推理【受控 改写】
- 在Prompt组装阶段,从知识图谱中查询背景知识放入上下文【精准召 回】;
- 在结果封装阶段,用知识图谱进行知识修正和知识溯源。【自我修正】
这个分享中,只是粗略的介绍了用知识图谱去语义化组织文档,缺乏深度,于是查阅相关资料,翻到WhyHow.AI 的联合创始人(Co-Founder)Chia Jeng Yang的一篇文 Injecting Knowledge Graphs in different RAG stages,这篇文章较为详细的介绍了KG在RAG各个阶段的可能得应用方式,在这里分享给大家。
RAG 阶段#
我们将RAG分为下面几个阶段:
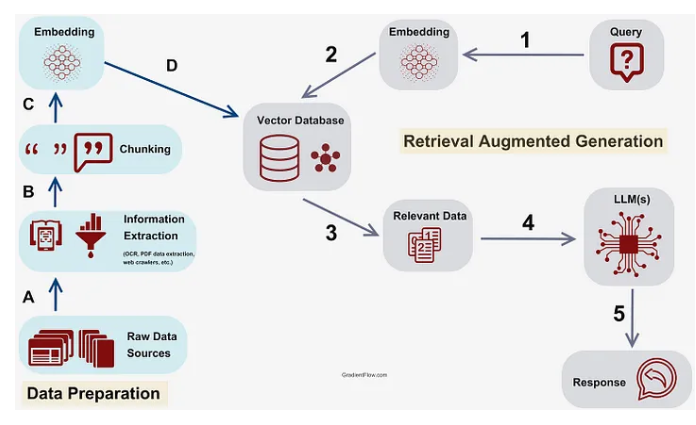
- 阶段1:预处理 ,通常是提取chunk分块之前的预处理。
- 阶段2/D:chunk提取
- 阶段3-5:后处理,用检索到的信息生成答案
查询增强(Query Augmentation)**#
预处理 阶段 ,这里主要 在执行检索之前,向查询添加上下文。
为什么:有的查询里可能包含一些缩写术语等,需要增加必要的上下文,去修正这些不好的queries
典型的就是,不同的行业有自己专有术语,这个LLM可能并不能准确的理解,从而导致理解错误。比如在英语里,‘beachfront’ homes and ‘near the beach’ homes 代表不同类型的房产(海滨”房屋和“靠近海滩”的房屋),不能互换使用。在预处理阶段注入这一上下文,有助于获得更精确的回答。
KG的一个常见应用场景,也是帮助企业构建缩略词词典,以便搜索引擎可以有效识别问题或文档中的缩略词。
另外,可以使用KG来帮助做多跳推理,也就是做一些query扩展,简单的做法就是在KG中存储实体的查询规则,通过信息化系统,可以让非技术用户也就是运营同学来构建和修改规则及关系,灵活的控制RAG规则。例如,某个规则可以看起来像这样:“当回答有关休假政策的问题时,首先参考办公室人力资源政策文件,然后在文件中查看有关假期的部分“。
再扩散一点,对于特定类型的概念,比如搜索企业家,那么用户可能了解他的个人资料 最新消息 职业生涯等信息,这个可以在kg中建立这种rule。
之前分析过秘塔搜索,应该是基于LLM对query做了一些改写和扩展,比如下图:
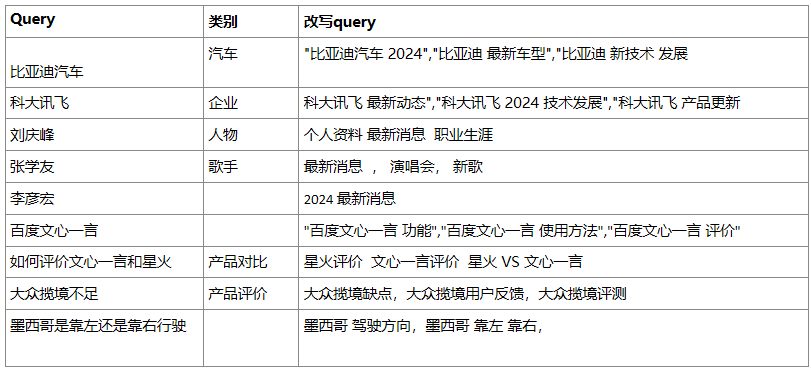
LLM 有成本和不可控的因素,用KG rule的方式来做的话,或者两者结合,会更可控,方便运营维护。
chunk 分块提取#
其实这里就是最早提到的,如何用知识图谱将文档内容进行语义化组织。这里刘的分享里提到:
ppt的图里给了一个示意:
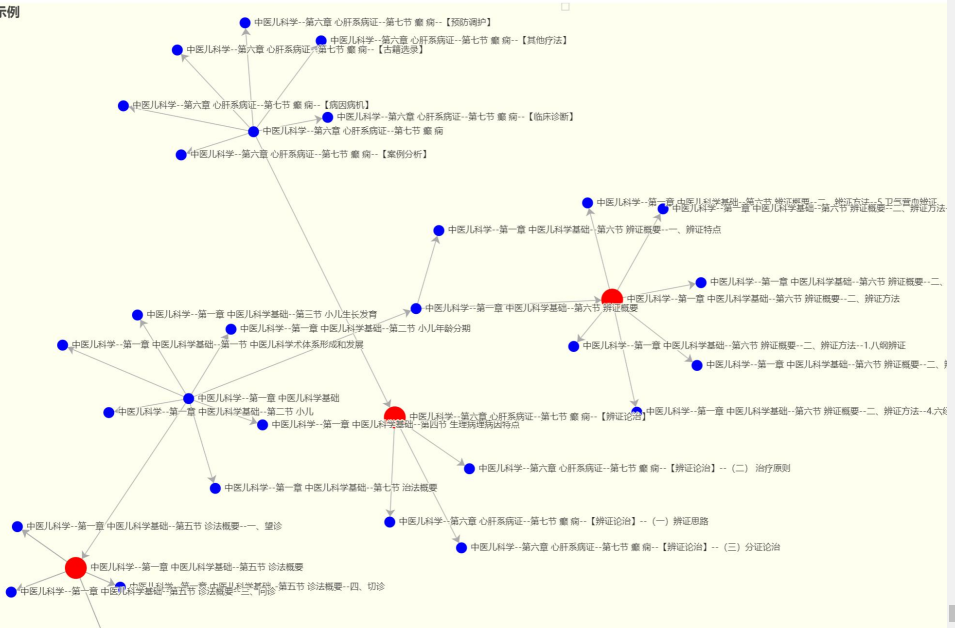
这里的问题是,这样组织了,如何有效的使用,分享里未有效提及。在Yang的文章中,也有提及建立层次化的文档结构。
相关原因:这用于快速识别文档层次结构中相关的chunks,并允许你使用自然语言来创建规则,规定在生成响应之前,查询必须参考哪些文档/块。
- KG 可以是文档描述的层次结构,引用存储在向量数据库中的chunk
- KG 也可以是文档层次结构的规则。例如,在一个风险投资基金的 RAG 系统中,可以编写一条自然语言规则,“要回答有关投资者义务的问题,首先检查投资者在投资者投资组合列表中投资了什么,然后检查所述投资组合的法律文件”
另外,还有一种 metadata kg(元数据知识图谱)的方案,也就是建立contextual dictionary,这对于理解重要主题包含在哪些文档块中很有用。这类似于书后的索引:

上面的图片中,给出了重要的概念所在的page,对于RAG系统,其实就是哪些重要的chunk id。比如,可以对于一个实体,定义需要检索的chunk,扩大一点可以是doc。
举个例子,你可以加入自然语言规则,“任何与幸福概念有关的问题,你都必须对定义的contextual dictionary相关块进行详尽搜索,在执行检索时,LLM会转换成一个Cypher 查询语句,从KG里查询关联的chunk,然后从这些chunk里去检索,可以提高速度和准确率。
后处理 递归知识图谱查询#
这里提到了一个递归知识图谱查询的概念,大概的意思就是将查询的信息,存储到KG中,如果上下文不足,再次检索,将提取的答案保存在同一KG中,并重复此过程,类似COT一样,用KG来存储检索到的结果,这个感觉demo的意味居多。
实际案例#
作者给了一个医疗领域的例子。
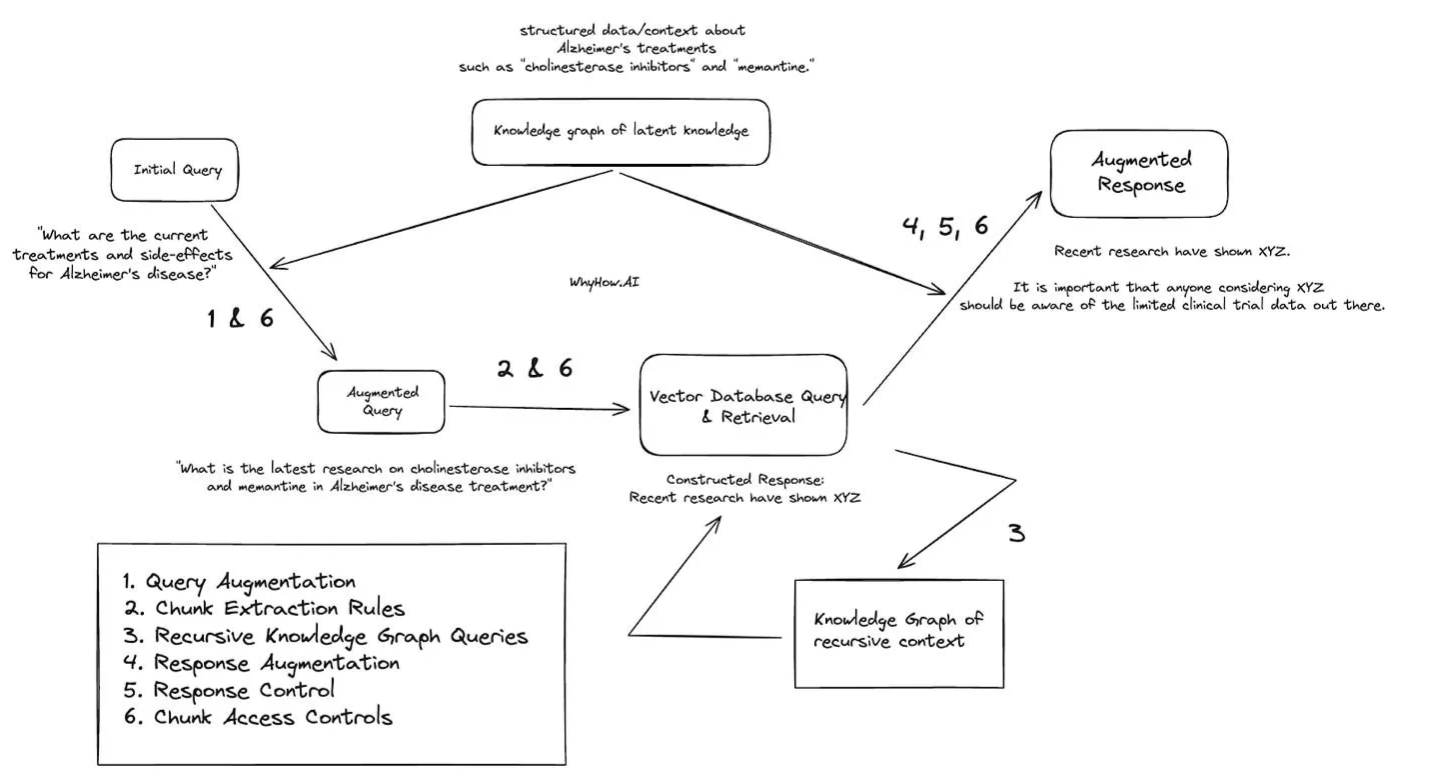
比如query:“阿尔茨海默病治疗的最新研究是什么?”利用上述策略来做RAG.
-
查询增强: 对于问题——“阿尔茨海默病治疗的最新研究是什么?”通过访问知识图谱,LLM代理可以持续检索有关最新阿尔茨海默病治疗的结构化数据,比如“胆碱酯酶抑制剂”和“美兰汀”。 然后RAG系统随后就可以将问题增强为更具体的问题:“关于胆碱酯酶抑制剂和美兰汀在阿尔茨海默病治疗中的最新研究是什么?”
-
文档层次结构和向量数据库检索:
- 使用文档层次结构,确定哪些文档和chunk块与“胆碱酯酶抑制剂”和“美兰汀”最相关,并返回相关答案。
- 关于“胆碱酯酶抑制剂”的相关信息块提取规则有助于指导查询引擎提取最有用的chunks。
- 文档层次结构帮助查询引擎快速识别与副作用相关的文档,并开始提取文档内的chunk。
- contextual dictionary字典帮助查询引擎快速识别与“胆碱酯酶抑制剂”相关的chunk,并开始提取与该主题相关的chunk。
- 关于“胆碱酯酶抑制剂”的已建立规则指出,关于胆碱酯酶抑制剂副作用的查询还应检查与酶X相关的chunk,这是因为酶X是一个不容忽视的已知副作用,相关的块相应地被包括在内。
-
递归知识图谱查询: 使用递归知识图谱查询,初始查询返回了“美兰汀”的一个副作用,称为“XYZ效应”。 “XYZ效应”被存储在一个单独的知识图谱中,用于递归上下文。 LLM被要求检查带有XYZ效应附加上下文的新增强查询。根据以往格式化的答案,它确定需要更多有关 XYZ 作用的信息才能得到满意的答案。然后,它在知识图谱中XYZ效应节点内进行更深入的搜索,从而执行多跳查询。 在XYZ效应节点内,它发现了可以包含在答案中的临床试验A和临床试验B的信息。
-
块控制访问 尽管临床试验A和B都包含有用的上下文,但与临床试验B节点相关的元数据标签指出,该节点的访问受用户限制。因此,一个常设的控制访问规则防止将临床试验B节点包含在对用户的响应中。 只有关于临床试验A的信息被返回给LLM,以帮助制定其返回的答案。
-
增强响应: 作为后处理步骤,您还可以选择使用特定于医疗行业的知识图谱增强后处理输出。例如,您可以包含针对美兰汀治疗的默认健康警告,或包含与临床试验A相关的任何额外信息。
-
块个性化: 存储了用户是研发部门的初级员工的额外上下文,并且用户被限制访问临床试验B的信息,答案是增强了一张提示信息,说明他们被禁止访问临床试验B的信息,并被告知向高级经理寻求更多信息。
总结#
知识图谱KG如何更好的利用在RAG里,是一个值得深入探讨的好话题,本文探讨了知识图谱在RAG不同阶段能产生的作用,不妨去试一试,后续我们会基于一些案例来实际探讨。
