-
ChatGPT数据集之谜

半个月以来,ChatGPT这把火越烧越旺。国内很多大厂相继声称要做中文版ChatGPT,还公布了上线时间表,不少科技圈已功成名就的大佬也按捺不住,携巨资下场,要创建“中国版OpenAI“。
不过,看看过去半个月在群众眼里稍显窘迫的Meta的Galactica,以及Google紧急发布的Bard,就知道在短期内打造一个比肩甚至超越ChatGPT效果的模型没那么简单。
让很多人不免感到诧异的是,ChatGPT的核心算法Transformer最初是由Google提出的,并且在大模型技术上的积累可以说不弱于OpenAI,当然他们也不缺算力和数据,但为什么依然会被ChatGPT打的措手不及?
Meta首席AI科学家Yann LeCun最近抨击ChatGPT的名言实际上解释了背后的门道。他说,ChatGPT“只是巧妙的组合而已”,这句话恰恰道出了一种无形的技术壁垒。
简单来说,即使其他团队的算法、数据、算力都准备的与OpenAI相差无几,但就是没想到以一种精巧的方式把这些元素组装起来,没有OpenAI,全行业不知道还需要去趟多少坑。
即使OpenAI给出了算法上的一条路径,后来者想复现ChatGPT,算力、工程、数据,每一个要素都需要非常深的积累。七龙珠之中,算力是自由流通的商品,花钱可以买到,工程上有OneFlow这样的开源项目和团队,因此,对互联网大厂之外的团队来说,剩下最大的挑战在于高质量训练数据集。
至今,OpenAI并没有公开训练ChatGPT的相关数据集来源和具体细节,一定程度上也暂时卡了追赶者的脖子,更何况,业界公认中文互联网数据质量堪忧。
好在,互联网上总有热心的牛人分析技术的细枝末节,从杂乱的资料中串联起蛛丝马迹,从而归纳出非常有价值的信息。
此前,OneFlow发布了《ChatGPT背后的经济账》,其作者从经济学视角推导了训练大型语言模型的成本。本文作者则整理分析了2018年到2022年初从GPT-1到Gopher的相关大型语言模型的所有数据集相关信息,希望帮助有志于开发“类ChatGPT”模型的团队少走一步弯路。
作者|Alan D. Thompson
OneFlow编译
翻译|杨婷、徐佳渝、贾川
一些研究人员的报告称,通用人工智能(AGI)可能是从我们当前的语言模型技术进行演进[1],预训练Transformer语言模型为AGI的发展铺平了道路。虽然模型训练数据集日渐增大,但缺乏基本指标文档,包括数据集大小、数据集token数量和具体的内容细节。
尽管业内提出了数据集组成和整理文档的标准[2],但几乎所有重点研究实验室在揭示模型训练数据集细节这方面都做得不够。这里整合的研究涵盖了2018年到2022年初从GPT-1到Gopher的精选语言模型的所有数据集(包括主要数据集:Wikipedia和Common Crawl)的综合视图。
1
概述
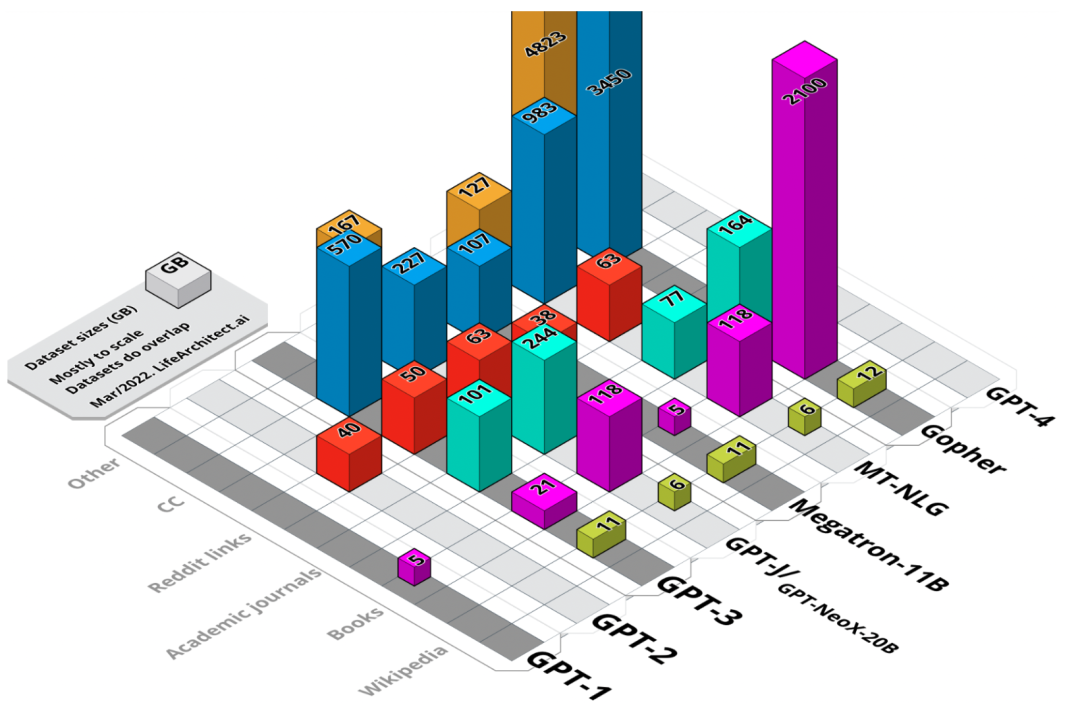
图 1. 主要数据集大小的可视化汇总。未加权大小,以GB为单位。
2018年以来,大语言模型的开发和生产使用呈现出爆炸式增长。一些重点研究实验室报告称,公众对大语言模型的使用率达到了惊人高度。2021年3月,OpenAI宣布[3]其GPT-3语言模型被“超过300个应用程序使用,平均每天能够生成45亿个词”,也就是说仅单个模型每分钟就能生成310万词的新内容。
值得注意的是,这些语言模型甚至还没有被完全理解,斯坦福大学的研究人员[4]最近坦言,“目前我们对这些模型还缺乏认知,还不太了解这些模型的运转模式、不知道模型何时会失效,更不知道这些模型的突现性(emergent properties)能产生什么效果”。
随着新型AI技术的快速发展,模型训练数据集的相关文档质量有所下降。模型内部到底有什么秘密?它们又是如何组建的?本文综合整理并分析了现代大型语言模型的训练数据集。
因为这方面的原始文献并不对外公开,所以本文搜集整合了二、三级研究资料,在必要的时候本文会采用假设的方式来推算最终结果。
在本文中,我们会将原始论文中已经明确的特定细节(例如token数量或数据集大小)归类为“公开的(disclosed)”数据,并作加粗处理。
多数情况下,适当地参考二、三级文献,并采用假设的方式来确定最终结果是很有必要的。在这些情况下,token数量和数据集大小等细节是“确定的(determined)”,并以斜体标记。
模型数据集可分为六类,分别是:维基百科、书籍、期刊、Reddit链接、Common Crawl和其他数据集。
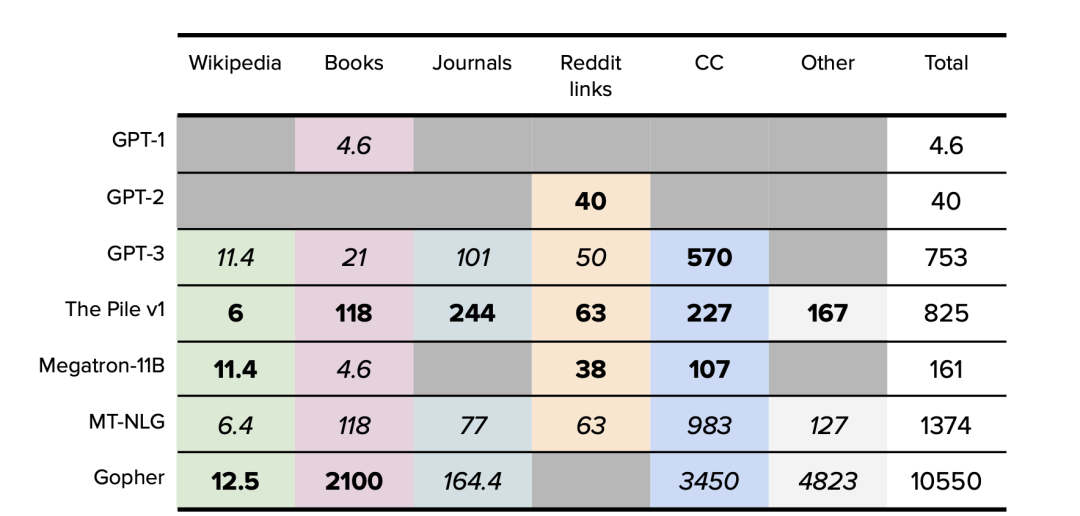
表1. 主要数据集大小汇总。以GB为单位。公开的数据以粗体表示。确定的数据以斜体表示。仅原始训练数据集大小。
1.1. 维基百科
维基百科是一个免费的多语言协作在线百科全书,由超过300,000名志愿者组成的社区编写和维护。截至2022年4月,英文版维基百科中有超过640万篇文章,包含超40亿个词[5]。维基百科中的文本很有价值,因为它被严格引用,以说明性文字形式写成,并且跨越多种语言和领域。一般来说,重点研究实验室会首先选取它的纯英文过滤版作为数据集。
1.2. 书籍
故事型书籍由小说和非小说两大类组成,主要用于训练模型的故事讲述能力和反应能力,数据集包括Project Gutenberg和Smashwords (Toronto BookCorpus/BookCorpus)等。
1.3. 杂志期刊
预印本和已发表期刊中的论文为数据集提供了坚实而严谨的基础,因为学术写作通常来说更有条理、理性和细致。这类数据集包括ArXiv和美国国家卫生研究院等。
1.4. Reddit链接
WebText是一个大型数据集,它的数据是从社交媒体平台Reddit所有出站链接网络中爬取的,每个链接至少有三个赞,代表了流行内容的风向标,对输出优质链接和后续文本数据具有指导作用。
1.5. Common Crawl
Common Crawl是2008年至今的一个网站抓取的大型数据集,数据包含原始网页、元数据和文本提取,它的文本来自不同语言、不同领域。重点研究实验室一般会首先选取它的纯英文过滤版(C4)作为数据集。
1.6. 其他数据集
不同于上述类别,这类数据集由GitHub等代码数据集、StackExchange 等对话论坛和视频字幕数据集组成。
2
常用数据集2019年以来,大多数基于Transformer的大型语言模型 (LLM) 都依赖于英文维基百科和Common Crawl的大型数据集。在本节中,我们参考了Jesse Dodge和AllenAI(AI2)[8]团队的综合分析,按类别对英文维基百科作了高级概述,并在Common Crawl数据集[7]的基础上,用谷歌C4[6] (Colossal Clean Crawled Corpus)在Common Crawl中提供了顶级域(domains)。
2.1. 维基百科(英文版)分析
下面按类别[9]列出了维基百科的详细信息,涵盖了2015年抽样的1001篇随机文章,研究人员注意到随时间推移文章传播的稳定性。假设一个11.4GB、经过清理和过滤的维基百科英文版有30亿token,我们就可以确定类别大小和token。
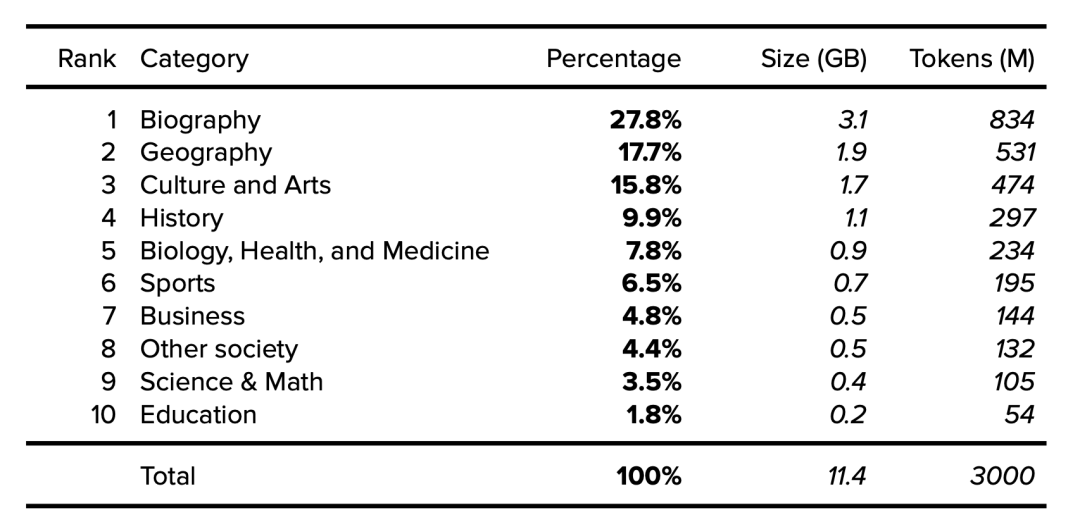
表2. 英文维基百科数据集类别。公开的数据以粗体表示。确定的数据以斜体表示。
2.2 Common Crawl分析
基于AllenAI (AI2)的C4论文,我们可以确定,过滤后的英文C4数据集的每个域的token数和总体百分比,该数据集为305GB,其中token数为1560亿。
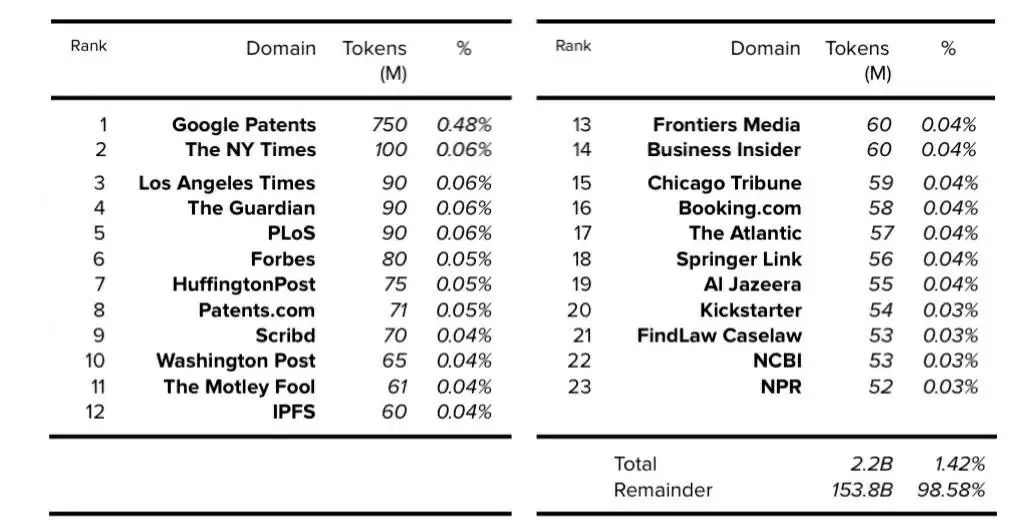
表3. C4:前23个域
-
相关阅读:
第3章业务功能开发(修改市场活动备注)
Stable Diffusion 的提示词使用技巧
第2-3-4章 上传附件的接口开发-文件存储服务系统-nginx/fastDFS/minio/阿里云oss/七牛云oss
Git 的原理与使用(下)
vue重修003
Redis~01 缓存:如何利用读缓存提高系统性能?
【高等数学】极限(下)(最全万字详解)
leetcode(力扣) 763. 划分字母区间
【王道】计算机网络网络层(三)
Vue3学习笔记+报错记录
- 原文地址:https://blog.csdn.net/OneFlow_Official/article/details/129036156