-
34.Python从入门到精通—Python3 正则表达式检索和替换
34.从入门到精通:Python3 正则表达式检索和替换 repl 参数是一个函数 正则表达式对象 正则表达式修饰符 - 可选标志 正则表达式模式* 正则表达式实例
检索和替换
在 Python 的 re 模块中,可以使用 re.sub() 函数来进行字符串的检索和替换。
re.sub() 函数的语法如下:re.sub(pattern, repl, string, count=0, flags=0)- 1
其中,pattern 表示要匹配的正则表达式,repl 表示要替换成的字符串,string 表示要进行替换的字符串,count
表示最多替换的次数,flags 表示正则表达式的匹配模式。以下是一个简单的例子,说明如何使用 re.sub() 函数进行字符串的替换:
import re text = "Hello, world! This is a test." pattern = r"\b\w{4}\b" repl = "****" new_text = re.sub(pattern, repl, text) print(new_text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
在这个例子中,首先定义了一个要进行替换的字符串 text,然后使用正则表达式 \b\w{4}\b 匹配所有长度为 4 的单词,并使用
**** 进行替换。最后使用 re.sub() 函数进行替换,并将替换后的字符串赋值给 new_text 变量,最后输出 new_text。需要注意的是,re.sub() 函数并不会修改原始字符串,而是返回一个新的字符串。如果要修改原始字符串,可以直接对原始字符串进行赋值。
repl 参数是一个函数
- 在 Python 的 re 模块中,re.sub() 函数可以用于在字符串中替换匹配的子串。re.sub() 函数的第一个参数是正则表达式,第二个参数是要替换成的字符串,第三个参数是要搜索的字符串。
- 除此之外,re.sub()函数还可以接受一个可调用对象作为第二个参数,这个可调用对象可以根据匹配结果返回一个新的字符串。这个可调用对象通常被称为 repl 函数。
以下是一个简单的例子,说明如何使用 repl 函数:
import re # 要替换的字符串 text = "Hello, world! This is a test." # 替换所有的单词为大写字母 pattern = r"\w+" new_text = re.sub(pattern, lambda match: match.group().upper(), text) # 输出替换结果 print(new_text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这个例子中,首先定义了一个要替换的字符串 text,然后使用 re.sub() 函数替换所有的单词为大写字母。在第二个参数中,使用了一个匿名函数来将匹配结果转换为大写字母。最后输出替换结果。
需要注意的是,repl 函数必须接受一个参数,这个参数是一个匹配对象,可以通过调用 group() 方法来获取匹配的字符串。repl 函数可以返回任何类型的对象,但必须返回一个字符串,否则会抛出 TypeError 异常。
正则表达式对象
在 Python 的 re 模块中,正则表达式对象是通过 re.compile() 函数创建的。正则表达式对象可以重复使用,可以提高程序的效率,尤其是在需要多次使用同一个正则表达式时。
以下是一个简单的例子,说明如何使用正则表达式对象:import re # 创建正则表达式对象 pattern = re.compile(r'\d+') # 使用正则表达式对象进行匹配 text = 'There are 123 apples and 456 oranges.' match_obj = pattern.search(text) print(match_obj.group()) # 输出结果:123- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这个例子中,首先使用 re.compile() 函数创建了一个正则表达式对象 pattern,然后使用 pattern.search( 方法进行匹配。正则表达式对象可以多次使用,可以在程序的其他地方使用同一个对象进行匹配。
- 需要注意的是,使用正则表达式对象进行匹配时,可以使用正则表达式对象的 search()、match()、findall()等方法。另外,正则表达式对象还可以通过调用 pattern.sub() 方法来进行替换操作。
- 正则表达式对象还可以接受一些参数,用于指定正则表达式的匹配模式。例如,可以通过 re.compile() 函数的 flags参数来指定正则表达式的匹配模式。
正则表达式修饰符 - 可选标志
在 Python 的 re 模块中,可以使用正则表达式修饰符(也称为可选标志)来更改正则表达式的匹配行为。正则表达式修饰符是在正则表达式模式中以特殊字符的形式出现的,用于指定匹配模式。
以下是一些常用的正则表达式修饰符: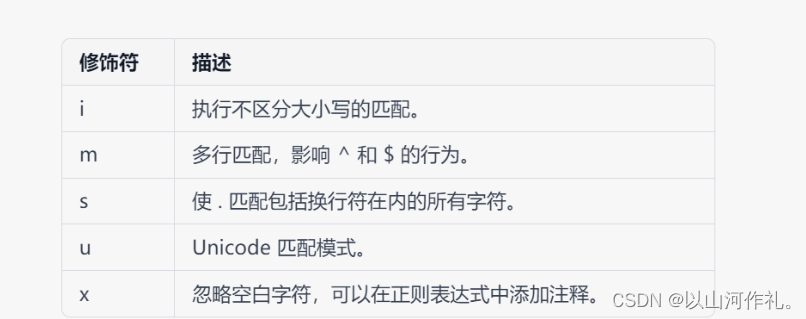
可以使用 re.compile() 函数来指定正则表达式修饰符。例如:
import re # 不区分大小写的匹配 pattern = re.compile("hello", re.IGNORECASE) match_obj = pattern.search("Hello, world!") print(match_obj.group()) # 输出 "Hello"- 1
- 2
- 3
- 4
- 5
- 6
在这个例子中,首先使用 re.compile() 函数指定了正则表达式模式 “hello” 和修饰符re.IGNORECASE,这表示进行不区分大小写的匹配。然后使用 pattern.search() 函数在字符串 “Hello,world!” 中搜索匹配结果,最后输出匹配结果。
- 需要注意的是,正则表达式修饰符可以同时使用多个,可以通过按位或运算符 | 来组合它们。例如,re.IGNORECASE | re.MULTILINE 表示同时使用不区分大小写的匹配和多行匹配。
正则表达式模式*
在 Python 的 re 模块中,正则表达式模式是用于匹配字符串的模式。正则表达式模式由一些特殊字符和普通字符组成,用于指定匹配规则。
以下是一些常用的正则表达式模式:
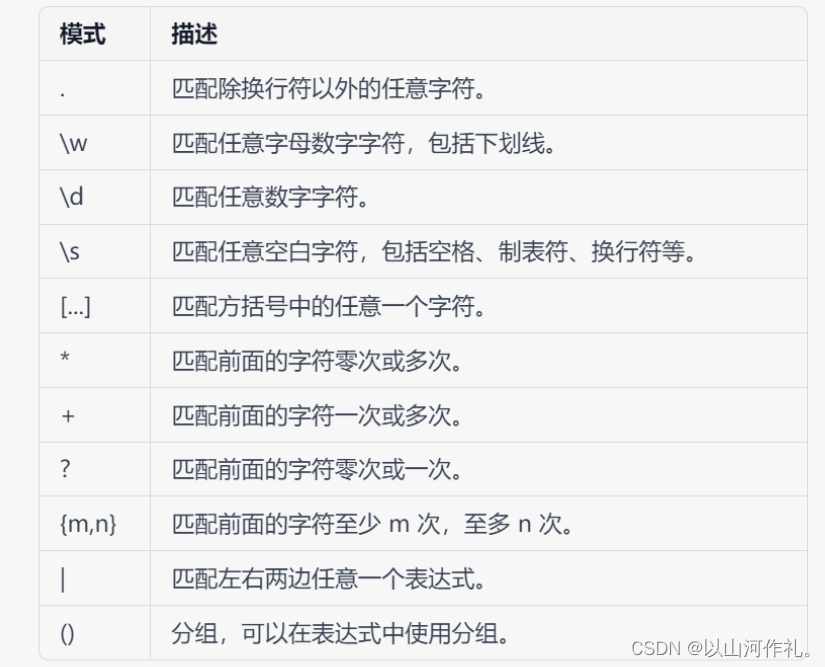
需要注意的是,正则表达式模式中的特殊字符需要进行转义,例如 . 表示匹配一个点号。可以使用反斜杠 \ 来进行转义。
以下是一个简单的例子,说明如何使用正则表达式模式:import re # 匹配所有的数字 pattern = "\d+" match_obj = re.search(pattern, "There are 123 apples and 456 oranges.") print(match_obj.group()) # 输出 "123"- 1
- 2
- 3
- 4
- 5
- 6
在这个例子中,正则表达式模式 “\d+” 表示匹配一个或多个数字字符。使用 re.search() 函数在字符串 “There are
123 apples and 456 oranges.” 中搜索匹配结果,最后输出匹配结果。正则表达式实例
下面是一些正则表达式的实例:
匹配手机号码
import re pattern = re.compile(r'^1[3-9]\d{9}$') phone_number = '13888888888' if pattern.match(phone_number): print('Valid phone number') else: print('Invalid phone number')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
匹配电子邮件地址
import re pattern = re.compile(r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$') email = 'example@example.com' if pattern.match(email): print('Valid email address') else: print('Invalid email address')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
匹配身份证号码
import re pattern = re.compile(r'^[1-9]\d{5}(18|19|20)\d{2}(0[1-9]|1[0-2])(0[1-9]|[1-2]\d|3[0-1])\d{3}[0-9Xx]$') id_number = '110101199001011234' if pattern.match(id_number): print('Valid ID number') else: print('Invalid ID number')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
匹配 URL
import re pattern = re.compile(r'^(http|https):\/\/[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}(\/\S*)?$') url = 'https://www.example.com/path/to/page.html' if pattern.match(url): print('Valid URL') else: print('Invalid URL')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这些正则表达式只是一些常见的例子,实际上正则表达式可以匹配各种各样的文本模式。需要注意的是,正则表达式的性能可能会受到匹配的文本长度和复杂度的影响,需要谨慎使用。
-
相关阅读:
开源|商品识别推荐系统
每日刷题记录 (二十四)
教你遇到vcomp120.dll无法继续执行代码的解决方法
第一章三层交换应用
不安装运行时运行.NET程序
C# Winfrom Chart 图表控件 柱状图、折线图
旅游推荐系统
python网络爬虫教程笔记(1)
【Mysql】mysql学习之旅06-事务
机器学习笔记 - 基于CNN+OpenCV的图像着色
- 原文地址:https://blog.csdn.net/weixin_50804299/article/details/137347600