-
01 Python进阶:正则表达式
re.match函数
使用 Python 中的 re 模块时,可以通过 re.match() 函数来尝试从字符串的开头匹配一个模式。以下是一个简单的详解和举例:
import re # 定义一个正则表达式模式 pattern = r'^[a-z]+' # 匹配开头的小写字母序列 # 要匹配的字符串 text = "hello world" # 使用 re.match() 尝试匹配模式 match_obj = re.match(pattern, text) if match_obj: print("匹配成功:", match_obj.group()) else: print("无匹配结果")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在这个示例中,我们使用了 re.match() 函数来尝试从字符串的开头匹配一个小写字母序列。让我们具体解释一下:
-
r'^[a-z]+':这是一个正则表达式模式,包含了以下几个部分:^表示匹配字符串的开头。[a-z]表示匹配任意一个小写字母。+表示匹配前面的模式一次或多次。
-
"hello world":这是我们要进行匹配的字符串。 -
re.match(pattern, text):使用 re.match() 函数尝试从字符串开头匹配指定的模式。 -
match_obj:re.match() 函数返回一个 Match 对象,如果匹配成功则包含匹配的结果,否则为 None。 -
match_obj.group():如果匹配成功,可以通过 match_obj.group() 方法获取匹配的内容。
在这个示例中,由于 “hello” 符合模式
r'^[a-z]+',因此匹配成功,输出 “匹配成功: hello”。re.search方法
可以通过 re.search() 函数来搜索整个字符串,尝试找到与指定模式匹配的子串。以下是一个详细解释和示例:
import re # 定义一个正则表达式模式 pattern = r'world' # 要匹配的模式是 "world" # 要搜索的字符串 text = "hello world" # 使用 re.search() 方法在整个字符串中搜索模式 search_obj = re.search(pattern, text) if search_obj: print("找到匹配:", search_obj.group()) else: print("未找到匹配")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在这个示例中,我们使用了 re.search() 函数来搜索整个字符串,尝试找到子串 “world”。以下是每个部分的详细解释:
-
r'world':这是一个简单的正则表达式模式,它表示要匹配的字符串是 “world”。 -
"hello world":这是我们要进行搜索的字符串。 -
re.search(pattern, text):使用 re.search() 函数在整个字符串中搜索指定的模式。 -
search_obj:re.search() 函数返回一个 Match 对象,如果找到了匹配的子串,Match 对象就会包含匹配的结果,否则为 None。 -
search_obj.group():如果找到了匹配的子串,可以通过调用 match_obj.group() 方法来获取匹配的内容。
在这个示例中,由于字符串 “world” 存在于 “hello world” 中,因此 re.search() 函数找到了匹配,输出 “找到匹配: world”。
re.search() 是一个非常有用的函数,可以帮助您在字符串中查找特定的模式。希望这个示例能够帮助您理解 re.search() 函数的使用方法。
re.match 与 re.search的区别
re.match() 和 re.search() 是 Python 中 re 模块中用于正则表达式匹配的两个函数,它们之间有以下区别:
-
re.match():
- re.match() 函数尝试从字符串的开头开始匹配模式。
- 如果字符串开头不符合模式,则匹配失败,返回 None。
- 如果字符串开始部分与模式匹配,返回一个 Match 对象,可以通过 group() 方法获取匹配的内容。
-
re.search():
- re.search() 函数在整个字符串中搜索并找到第一个符合模式的子串。
- 不要求字符串从开头开始匹配,只要找到一个符合模式的子串就返回。
- 返回第一个匹配到的结果,也是一个 Match 对象,可以通过 group() 方法获取匹配的内容。
举例来说,假设有字符串 “hello world”,并使用以下两个正则表达式模式进行匹配:
-
模式为
r'world':- re.match() 将会匹配失败,因为 “hello” 不符合该模式,返回 None。
- re.search() 将会匹配成功,在 “world” 中找到了符合的子串,返回 “world”。
-
模式为
r'hello':- re.match() 将会匹配成功,因为 “hello” 符合该模式,返回 “hello”。
- re.search() 将会匹配成功,在 “hello world” 中找到了符合的子串,返回 “hello”。
re.match() 适用于需要从字符串开头处进行匹配的场景,而 re.search() 则适用于需要在整个字符串中查找符合模式的子串的场景。根据具体的需求选择使用不同的函数能够更有效地实现匹配目的。
检索和替换
在Python中,您可以使用re模块来进行文本的检索和替换。下面是一个简单的例子来说明如何使用re模块进行检索和替换:
import re # 要操作的字符串 text = "The cat and the hat sat on the mat." # 定义要搜索的模式 pattern = r'cat' # 使用re.sub()进行替换 new_text = re.sub(pattern, 'dog', text) print(new_text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
在上面的示例中,我们使用了re.sub()函数来将文本中所有匹配模式r’cat’的部分替换为’dog’。执行上述代码后,输出结果为:“The dog and the hat sat on the mat.”。
另外,如果想要查找所有匹配的子串,并对其进行特定处理,也可以使用re.findall()和re.finditer()函数来实现。这两个函数可以用于找到所有匹配的子串,并返回它们的位置或者进行进一步的处理。
repl 参数是一个函数
是的,re 模块中的 re.sub() 函数允许使用一个函数作为 repl 参数,以便对每个匹配的子串进行更复杂的替换操作。下面是一个示例,演示了如何使用函数作为 repl 参数:
import re # 要操作的字符串 text = "The cat and the hat sat on the mat." # 定义替换函数 def repl_function(match_obj): word = match_obj.group() if word == 'cat': return 'dog' elif word == 'hat': return 'rug' else: return '***' # 使用re.sub()并将函数作为repl参数 new_text = re.sub(r'\b(cat|hat)\b', repl_function, text) print(new_text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在这个示例中,我们定义了一个名为
repl_function的函数,该函数接收一个 Match 对象作为输入,并根据匹配到的子串来决定如何进行替换。然后,我们使用re.sub()函数,将这个函数作为repl参数传递给它。执行上述代码后,输出结果为:“The dog and the rug sat on the mat.”。函数作为
repl参数的用法,可以让你对每个匹配到的子串进行更加灵活和复杂的处理,从而进行更加精细的替换操作。compile 函数
在 Python 中,re 模块提供了 compile() 函数,用于将正则表达式编译为一个对象,以便在之后的匹配中复用。这种预编译的方式可以提高匹配效率,特别是在需要多次使用同一模式进行匹配时。下面是一个简单的示例来说明 compile() 函数的使用:
import re # 将正则表达式编译为对象 pattern = re.compile(r'hello') # 要匹配的字符串 text = "hello world" # 使用编译后的对象进行匹配 match_obj = pattern.search(text) if match_obj: print("找到匹配:", match_obj.group()) else: print("未找到匹配")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在上述示例中,我们首先使用 re.compile() 函数将正则表达式模式 r’hello’ 编译为一个模式对象 pattern,然后在之后的代码中可以重复使用这个 pattern 对象进行匹配操作。
使用 compile() 函数的优点包括提高匹配效率和可以提前检查正则表达式的有效性(如果有语法错误,会在编译阶段就抛出异常)。
re.compile() 函数允许您事先编译好正则表达式模式,并得到一个可重复使用的模式对象,为之后的匹配操作提供了便利和性能上的提升。
findall
在 Python 的 re 模块中,
re.findall()函数用于在给定的字符串中查找所有匹配指定模式的子串,并以列表的形式返回这些子串。下面是一个简单的示例来说明re.findall()函数的使用:import re # 要匹配的字符串 text = "The cat and the hat sat on the mat." # 使用 re.findall() 查找所有匹配的子串 matches = re.findall(r'\b\w{3}\b', text) print(matches)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
使用了
re.findall()函数来搜索字符串中所有匹配特定模式的子串。具体来说,我们使用的模式是\b\w{3}\b,表示匹配长度为 3 的单词。执行这段代码后,将输出结果作为一个列表:
['The', 'cat', 'the', 'hat', 'sat', 'the', 'mat'],其中包含所有匹配到的长度为3的单词。re.findall()函数非常适合在不需要对每个匹配结果做更复杂处理的情况下,快速地获取所有匹配到的子串。当需要获取文本中所有符合特定模式的部分时,这个函数非常实用。re.finditer
re.finditer()函数与re.findall()类似,但它返回一个迭代器(iterator),该迭代器生成匹配的模式在字符串中的每一次出现。下面是一个简单的示例来说明re.finditer()函数的使用:import re # 要匹配的字符串 text = "The cat and the hat sat on the mat." # 使用 re.finditer() 查找所有匹配的子串 matches = re.finditer(r'\b\w{3}\b', text) for match in matches: print(match.group(), match.start(), match.end())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
在这个示例中,我们使用了
re.finditer()函数来搜索字符串中所有匹配特定模式的子串。具体来说,我们使用的模式是\b\w{3}\b,表示匹配长度为 3 的单词。使用
re.finditer()返回的迭代器,我们可以迭代处理每次匹配到的结果,从中获取匹配子串的内容以及其在原始文本中的起始和结束位置。执行上述代码后, 将输出每个匹配子串的内容以及起始和结束索引位置。因此,
re.finditer()是一个非常有用的函数,特别适用于需要对每个匹配结果做更复杂处理的情况,或者在需要获取匹配子串的位置信息时。re.split
re.split()函数用于根据指定的模式对字符串进行分割,并返回分割后的子串组成的列表。下面是一个简单的示例来说明re.split()函数的使用方式:import re # 要分割的字符串 text = "apple, banana, cherry, date" # 使用 re.split() 进行分割 result = re.split(r',\s*', text) print(result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这个示例中,我们使用了
re.split()函数来根据逗号加空格的模式,\\s*对字符串进行分割,其含义是以逗号加零或多个空格为分隔符。执行上述代码后,将输出结果作为一个列表:['apple', 'banana', 'cherry', 'date'],即根据指定的模式成功地将原始字符串分割成了多个子串。re.split()是在字符串操作中非常有用的函数,特别适用于需要根据复杂的模式对字符串进行分割的情况,如按照标点符号、空格或其他自定义的分割符号进行分割。正则表达式对象
正则表达式对象
re.RegexObject
re.compile() 返回 RegexObject 对象。re.MatchObject
group() 返回被 RE 匹配的字符串。- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
在 Python 的 re 模块中,使用
re.compile()函数可以将正则表达式模式编译为一个正则表达式对象。正则表达式对象具有与模式相关联的各种方法,可用于在文本中进行搜索、匹配和替换操作。以下是一些常用的正则表达式对象的方法:search(string[, pos[, endpos]]): 在字符串中搜索模式的第一个匹配项,返回一个匹配对象。match(string[, pos[, endpos]]): 在字符串开头匹配模式,如果匹配成功则返回一个匹配对象。findall(string[, pos[, endpos]]): 找到所有与模式匹配的子串,并以列表的形式返回这些子串。finditer(string[, pos[, endpos]]): 返回一个迭代器,用于生成字符串中与模式匹配的每一个匹配对象。split(string[, maxsplit]): 根据模式对字符串进行分割,返回分割后的子串组成的列表。sub(repl, string, count=0): 使用指定的替换字符串替换匹配到的模式,返回替换后的字符串。
正则表达式对象的创建通过
re.compile()函数,其基本语法如下:import re pattern = re.compile(r'正则表达式模式')- 1
- 2
接下来,您可以使用
pattern对象调用上述列出的方法来进行搜索、匹配或替换操作。例如:# 使用 compile() 函数将正则表达式模式编译为对象 pattern = re.compile(r'\b\w{4}\b') # 使用 findall() 方法找到所有匹配的子串 matches = pattern.findall("The cat and the hat sat on the mat.") print(matches)- 1
- 2
- 3
- 4
- 5
- 6
这将会输出:
['cat', 'hat', 'sat'],即从字符串中找到了所有长度为 4 的单词。正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。
以下标志可以单独使用,也可以通过按位或(|)组合使用。例如,re.IGNORECASE | re.MULTILINE 表示同时启用忽略大小写和多行模式。
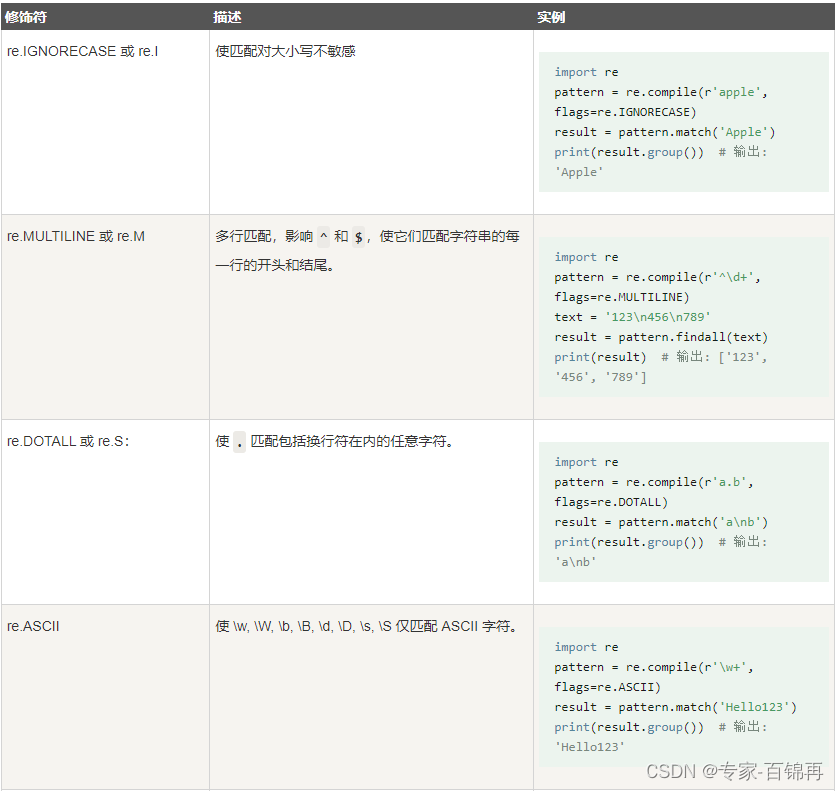

正则表达式模式
正则表达式模式是由普通字符(例如字符 a 到 z)和特殊字符(称为元字符)组合而成的字符串,用于描述在文本中搜索、匹配或替换特定模式的规则。下面列举了一些常用的正则表达式元字符及其含义:
.:匹配任意单个字符,除了换行符。^:匹配字符串的开头。$:匹配字符串的结尾。*:匹配前面的元素零次或多次。+:匹配前面的元素一次或多次。?:匹配前面的元素零次或一次。\d:匹配任意数字,相当于 [0-9]。\w:匹配字母、数字、下划线,相当于 [a-zA-Z0-9_]。[...]:匹配方括号中的任意一个字符。(x|y):匹配 x 或 y。\s:匹配任意空白字符,包括空格、制表符、换行符等。
除了上述元字符外,正则表达式还支持通过括号来表示分组,使用
{}来指定重复次数,使用\来转义特殊字符等。例如,正则表达式模式
\b\w{3}\b可以用于匹配长度为 3 的单词,其中:\b表示单词的边界。\w匹配任意字母、数字或下划线。{3}表示重复前面的元素三次。- 因此,整个模式就是匹配长度为 3 的单词。
正则表达式模式在对文本进行搜索、匹配或替换时非常强大,可以满足各种复杂的匹配需求。

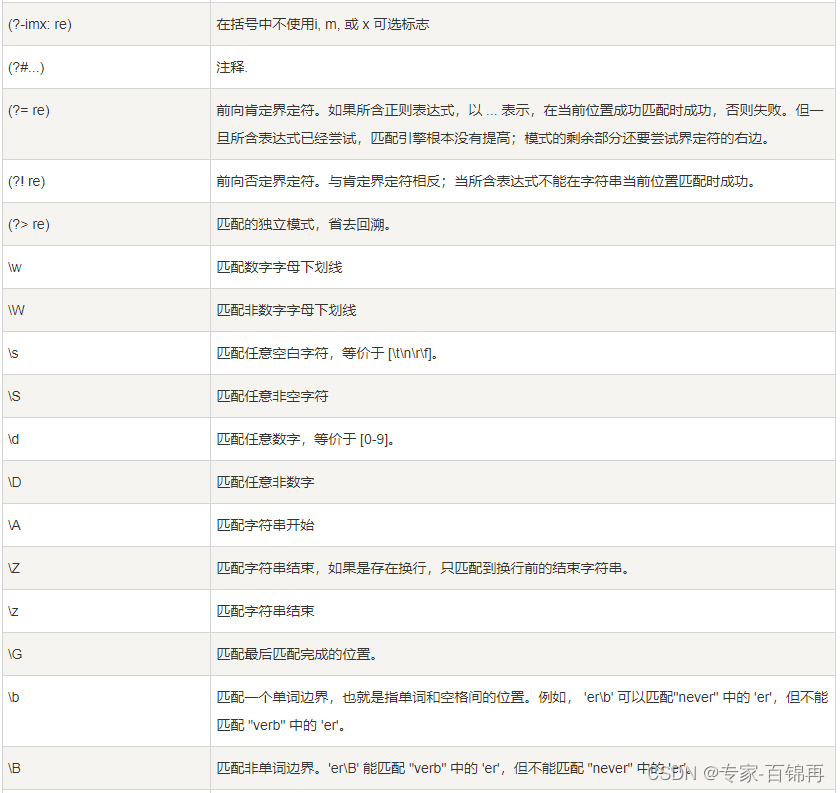

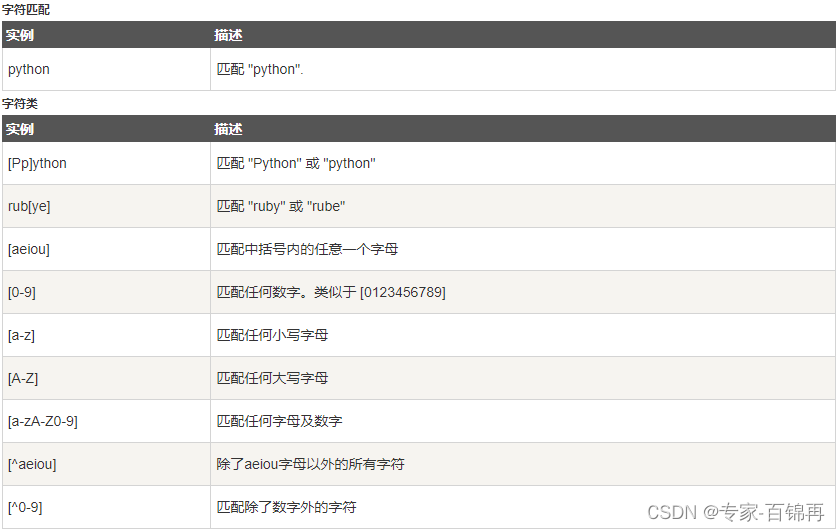
正则表达式实例

关注我,不迷路,共学习,同进步

-
相关阅读:
安装EasyX--图形库--从代码到图形
JAVA计算机毕业设计诗词文化网站源码+系统+mysql数据库+lw文档
【面经】如何使用less命令查看和搜索日志
win11部署自己的privateGpt(2024-0304)
Python 断言的使用
iOS开发-Lottie实现下拉刷新动画效果
STL是什么?如何理解STL?
d的属性效果2
行情分析——加密货币市场大盘走势(10.18)
JavaWeb后端开发登录操作 登录功能 通用模板/SpringBoot整合
- 原文地址:https://blog.csdn.net/sixpp/article/details/137276484
