-
NCCL源码解析⑤:路径计算

作者|KIDGINBROOK
更新|潘丽晨上节NCCL完成了对机器PCI系统拓扑的建图,其中建好的图如下所示,其中GPU之间是通过NVLink连接起来的。
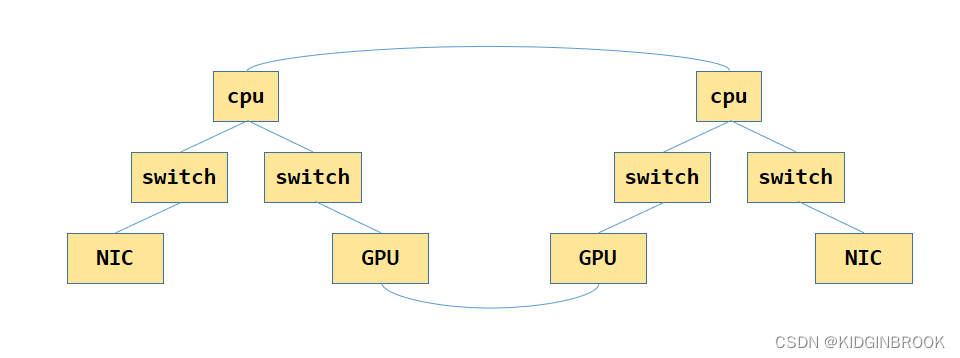
为了方便之后的搜索channel,接下来NCCL会先计算GPU和NIC节点到其他任意节点之间的最优路径,以及对应的带宽,即最优路径上所有边的带宽的最小值。
那么抽象一下,这个问题可以建模为给定一个无向图,每条边有一个权值,给定查询(u, v),求节点u到节点v的路径,使得路径上的最小边的权值最大,类似无向图的最小瓶颈路,可以用生成树+LCA的方法解决;如果查询中的u是固定的,那么也可以使用类似SPFA的方法解决,将松弛方法改一下即可。
上节忘记介绍图的数据结构,这里补一下。
图中的边由ncclTopoLink表示,type区分边的类型,比如NVLink,PCI;width表示带宽;remNode表示当前边连接的对端节点。
最后计算出来节点之间的路径由ncclTopoLinkList表示,路径一共有count条边,这个路径的带宽是width,即count条边中带宽最小为width,list为具体的边。
- struct ncclTopoLink {
- int type;
- float width;
- struct ncclTopoNode* remNode;
- };
- struct ncclTopoLinkList {
- struct ncclTopoLink* list[NCCL_TOPO_MAX_HOPS];
- int count;
- float width;
- int type;
- };
其中type为路径的类型,一共有如下几种枚举值。
- #define PATH_LOC 0
- #define PATH_NVL 1
- #define PATH_PIX 2
- #define PATH_PXB 3
- #define PATH_PHB 4
- #define PATH_SYS 5
- #define PATH_NET 6
PATH_LOC为节点到自己,PATH_NVL表示路径上的边都是NVLink,PATH_PIX表示经过最多一个PCIe switch,PATH_PXB表示经过了多个PCIe witch,但是没有经过CPU,PATH_PHB表示经过了CPU,PATH_SYS表示不同numa之间的路径。
每个节点由ncclTopoNode表示,nlinks表示该节点有几条边,links存储了具体连接的边,paths存储了到其他节点的路径,node1中的paths[type][id]就是node1到type类型的第id个node的路径。
ncclTopoNodeSet表示某种类型的所有节点,比如GPU,PCI,NIC等,ncclTopoSystem存储了全局所有类型的节点。
每个节点由ncclTopoNode表示,nlinks表示该节点有几条边,links存储了具体连接的边,paths存储了到其他节点的路径,node1中的paths[type][id]就是node1到type类型的第id个node的路径。
ncclTopoNodeSet表示某种类型的所有节点,比如GPU,PCI,NIC等,ncclTopoSystem存储了全局所有类型的节点。
- struct ncclTopoNodeSet {
- int count;
- struct ncclTopoNode nodes[NCCL_TOPO_MAX_NODES];
- };
- struct ncclTopoSystem {
- struct ncclTopoNodeSet nodes[NCCL_TOPO_NODE_TYPES];
- float maxWidth;
- };
- struct ncclTopoNode {
- int type;
- int64_t id;
- // Type specific data
- union {
- struct {
- int dev; // NVML dev number
- int rank;
- int cudaCompCap;
- int gdrSupport;
- }gpu;
- struct {
- uint64_t asic;
- int port;
- float width;
- int gdrSupport;
- int collSupport;
- int maxChannels;
- }net;
- struct {
- int arch;
- int vendor;
- int model;
- cpu_set_t affinity;
- }cpu;
- };
- int nlinks;
- struct ncclTopoLink links[NCCL_TOPO_MAX_LINKS];
- // Pre-computed paths to GPUs and NICs
- struct ncclTopoLinkList* paths[NCCL_TOPO_NODE_TYPES];
- // Used during search
- uint64_t used;
- };
然后看下NCCL路径计算的过程,主要是这三步。- NCCLCHECK(ncclTopoComputePaths(comm->topo, comm->peerInfo));
- // Remove inaccessible GPUs and unused NICs
- NCCLCHECK(ncclTopoTrimSystem(comm->topo, comm));
- // Recompute paths after trimming
- NCCLCHECK(ncclTopoComputePaths(comm->topo, comm->peerInfo));
其中ncclTopoComputePaths就是执行路径的计算,ncclTopoTrimSystem是删除用不到的节点,接下来详细看下。
- ncclResult_t ncclTopoComputePaths(struct ncclTopoSystem* system, struct ncclPeerInfo* peerInfos) {
- // Precompute paths between GPUs/NICs.
- // Remove everything in case we're re-computing
- for (int t=0; t<NCCL_TOPO_NODE_TYPES; t++) ncclTopoRemovePathType(system, t);
- // Set direct paths from/to CPUs. We need them in many cases.
- for (int c=0; c<system->nodes[CPU].count; c++) {
- NCCLCHECK(ncclTopoSetPaths(system->nodes[CPU].nodes+c, system));
- }
- ...
- }
首先通过ncclTopoRemovePathType将所有node中的paths清空。
ncclTopoSetPaths作用就是计算出其他所有节点到baseNode的path,这里遍历所有的CPU节点,计算出其他所有节点到所有CPU节点的路径。
ncclTopoSetPaths实现类似SPFA,由于这个版本的NCCL不允许GPU作为路径的中间节点,所以在SPFA的过程中不会将GPU节点添加到队列中更新其他节点,相当于这个无向图没有环,因此这个场景下的SPFA过程也就相当于BFS。
这里baseNode就是CPU节点,先分配CPU到CPU path的空间,nodeList和nextNodeList就是队列的作用,先将baseNode入队列。
getPath函数是获取node中到type为t的第id个节点的路径path。
static ncclResult_t getPath(struct ncclTopoSystem* system, struct ncclTopoNode* node, int t, int64_t id, struct ncclTopoLinkList** path);通过getPath获取到CPU节点到自己的path,然后设置count为0,带宽为LOC_WIDTH,type为PATH_LOC。
然后每次从nodeList中拿出一个节点node,获取node到baseNode的路径path,然后用node去更新和node相连的节点,遍历node的边link,获取link对端节点remNode,获取remNode到baseNode的路径remPath,此时需要比较两个路径哪个更优,一个路径是原来的remPath,另一个是path+link这个新路径,新路径的带宽width是path和link的带宽取个min,如果width大于remPath->width,那么remPath更新为path+link。
- static ncclResult_t ncclTopoSetPaths(struct ncclTopoNode* baseNode, struct ncclTopoSystem* system) {
- if (baseNode->paths[baseNode->type] == NULL) {
- NCCLCHECK(ncclCalloc(baseNode->paths+baseNode->type, system->nodes[baseNode->type].count));
- }
- // breadth-first search to set all paths to that node in the system
- struct ncclTopoNodeList nodeList;
- struct ncclTopoNodeList nextNodeList;
- nodeList.count = 1; nodeList.list[0] = baseNode;
- nextNodeList.count = 0;
- struct ncclTopoLinkList* basePath;
- NCCLCHECK(getPath(system, baseNode, baseNode->type, baseNode->id, &basePath));
- basePath->count = 0;
- basePath->width = LOC_WIDTH;
- basePath->type = PATH_LOC;
- while (nodeList.count) {
- nextNodeList.count = 0;
- for (int n=0; nstruct ncclTopoNode* node = nodeList.list[n];struct ncclTopoLinkList* path;NCCLCHECK(getPath(system, node, baseNode->type, baseNode->id, &path));for (int l=0; l
nlinks; l++) { struct ncclTopoLink* link = node->links+l;struct ncclTopoNode* remNode = link->remNode;if (remNode->paths[baseNode->type] == NULL) {NCCLCHECK(ncclCalloc(remNode->paths+baseNode->type, system->nodes[baseNode->type].count));}struct ncclTopoLinkList* remPath;NCCLCHECK(getPath(system, remNode, baseNode->type, baseNode->id, &remPath));float width = std::min(path->width, link->width);if (remPath->width < width) {// Find reverse linkfor (int l=0; lnlinks; l++) { if (remNode->links[l].remNode == node) {remPath->list[0] = remNode->links+l;break;}}if (remPath->list[0] == NULL) {WARN("Failed to find reverse path from remNode %d/%lx nlinks %d to node %d/%lx",remNode->type, remNode->id, remNode->nlinks, node->type, node->id);return ncclInternalError;}// Copy the rest of the pathfor (int i=0; icount; i++) remPath->list[i+1] = path->list[i]; remPath->count = path->count + 1;remPath->width = width;// Start with path type = link type. PATH and LINK types are supposed to match.// Don't consider LINK_NET as we only care about the NIC->GPU path.int type = link->type == LINK_NET ? 0 : link->type;// Differentiate between one and multiple PCI switchesif (type == PATH_PIX && (node->type == PCI || link->remNode->type == PCI) && remPath->count > 3) type = PATH_PXB;// Consider a path going through the CPU as PATH_PHBif (link->type == LINK_PCI && (node->type == CPU || link->remNode->type == CPU)) type = PATH_PHB;// Ignore Power CPU in an NVLink pathif (path->type == PATH_NVL && type == PATH_SYS && link->remNode->type == CPU &&link->remNode->cpu.arch == NCCL_TOPO_CPU_ARCH_POWER) type = 0;remPath->type = std::max(path->type, type);// Add to the list for the next iteration if not already in the list// Disallow GPUs as intermediate steps for nowif (remNode->type != GPU) {int i;for (i=0; iif (i == nextNodeList.count) nextNodeList.list[nextNodeList.count++] = remNode;}}}}memcpy(&nodeList, &nextNodeList, sizeof(nodeList));}return ncclSuccess;}路径更新后需要计算remPath的type,这里有个取巧的地方是上节设置边type和本节设置路径type是对应的,比如LINK_PCI等于PATH_PIX,然后可以看到之前说的各种路径的type是怎么计算出来的。
首先计算当前link作为一条路径的type,初始化为link的type,比如这个边是LINK_PCI,那么就是LINK_PIX,如果remPath的count大于3的话type就会更新为PATH_PXB(但是这里有个疑问是大于3可能也跨过了两个PCIe switch),如果link有一端是CPU,那么type进一步更新为PATH_PHB,最后取个max,remPath->type = std::max(path->type, type)。
- #define LINK_LOC 0
- #define LINK_NVL 1
- #define LINK_PCI 2
- // Skipping 3 for PATH_PXB
- // Skipping 4 for PATH_PHB
- #define LINK_SYS 5
- #define LINK_NET 6
- #define PATH_LOC 0
- #define PATH_NVL 1
- #define PATH_PIX 2
- #define PATH_PXB 3
- #define PATH_PHB 4
- #define PATH_SYS 5
- #define PATH_NET 6
如果remNode不是GPU,那么将remNode添加到nextNodeList,等nodeList遍历完之后,将nextNodeList赋给nodeList继续遍历。
然后回到ncclTopoComputePaths,还是使用ncclTopoSetPaths计算GPU节点到其他所有节点的距离。
- ncclResult_t ncclTopoComputePaths(struct ncclTopoSystem* system, struct ncclPeerInfo* peerInfos) {
- ...
- // Set direct paths from/to GPUs.
- for (int g=0; g
nodes[GPU].count; g++) { - // Compute paths to GPU g
- NCCLCHECK(ncclTopoSetPaths(system->nodes[GPU].nodes+g, system));
- // Update path when we don't want to / can't use GPU Direct P2P
- for (int p=0; p
nodes[GPU].count; p++) { - int p2p, read;
- NCCLCHECK(ncclTopoCheckP2p(system, system->nodes[GPU].nodes[p].id, system->nodes[GPU].nodes[g].id, &p2p, &read));
- if (p2p == 0) {
- // Divert all traffic through the CPU
- int cpu;
- NCCLCHECK(getLocalCpu(system, g, &cpu));
- NCCLCHECK(addCpuStep(system, cpu, GPU, p, GPU, g));
- }
- }
- if (peerInfos == NULL) continue;
- // Remove GPUs we can't talk to because of containers.
- struct ncclPeerInfo* dstInfo = peerInfos+system->nodes[GPU].nodes[g].gpu.rank;
- for (int p=0; p
nodes[GPU].count; p++) { - if (p == g) continue;
- struct ncclPeerInfo* srcInfo = peerInfos+system->nodes[GPU].nodes[p].gpu.rank;
- int shm;
- NCCLCHECK(ncclTransports[TRANSPORT_SHM].canConnect(&shm, system, NULL, srcInfo, dstInfo));
- if (shm == 0) {
- // Mark this peer as inaccessible. We'll trim it later.
- system->nodes[GPU].nodes[p].paths[GPU][g].count = 0;
- }
- }
- }
- // Set direct paths from/to NICs.
- for (int n=0; n
nodes[NET].count; n++) { - struct ncclTopoNode* netNode = system->nodes[NET].nodes+n;
- NCCLCHECK(ncclTopoSetPaths(netNode, system));
- for (int g=0; g
nodes[GPU].count; g++) { - // Update path when we dont want to / can't use GPU Direct RDMA.
- int gdr;
- NCCLCHECK(ncclTopoCheckGdr(system, system->nodes[GPU].nodes[g].id, netNode->id, 0, &gdr));
- if (gdr == 0) {
- // We cannot use GPU Direct RDMA, divert all traffic through the CPU local to the GPU
- int localCpu;
- NCCLCHECK(getLocalCpu(system, g, &localCpu));
- NCCLCHECK(addCpuStep(system, localCpu, NET, n, GPU, g));
- NCCLCHECK(addCpuStep(system, localCpu, GPU, g, NET, n));
- }
- }
- }
- return ncclSuccess;
- }
然后通过ncclTopoCheckP2p检查当前GPU节点和其他所有的GPU节点之间是否可以使用p2p通信,其实就是判断gpu1到gpu2的路径type是否满足p2pLevel的限制,默认p2pLevel是PATH_SYS,如果用户没有通过环境变量设置的话就相当于没有限制,任意gpu之间都是支持p2p通信,另外如果路径类型为PATH_NVL的话,那么还支持p2p read。
- ncclResult_t ncclTopoCheckP2p(struct ncclTopoSystem* system, int64_t id1, int64_t id2, int* p2p, int *read) {
- *p2p = 0;
- *read = 0;
- // Get GPUs from topology
- int g1, g2;
- NCCLCHECK(ncclTopoIdToIndex(system, GPU, id1, &g1));
- struct ncclTopoNode* gpu1 = system->nodes[GPU].nodes+g1;
- if (ncclTopoIdToIndex(system, GPU, id2, &g2) == ncclInternalError) {
- // GPU not found, we can't use p2p.
- return ncclSuccess;
- }
- struct ncclTopoLinkList* path = gpu1->paths[GPU]+g2;
- // In general, use P2P whenever we can.
- int p2pLevel = PATH_SYS;
- // User override
- if (ncclTopoUserP2pLevel == -1)
- NCCLCHECK(ncclGetLevel(&ncclTopoUserP2pLevel, "NCCL_P2P_DISABLE", "NCCL_P2P_LEVEL"));
- if (ncclTopoUserP2pLevel != -2) {
- p2pLevel = ncclTopoUserP2pLevel;
- goto compare;
- }
- // Don't use P2P through ARM CPUs
- int arch, vendor, model;
- NCCLCHECK(ncclTopoCpuType(system, &arch, &vendor, &model));
- if (arch == NCCL_TOPO_CPU_ARCH_ARM) p2pLevel = PATH_PXB;
- if (arch == NCCL_TOPO_CPU_ARCH_X86 && vendor == NCCL_TOPO_CPU_VENDOR_INTEL) {
- if (model == NCCL_TOPO_CPU_TYPE_BDW) p2pLevel = PATH_PXB;
- else p2pLevel = PATH_PHB;
- }
- compare:
- // Compute the PCI distance and compare with the p2pLevel.
- if (path->type <= p2pLevel) *p2p = 1;
- if (path->type == PATH_NVL) {
- struct ncclTopoNode* gpu2 = system->nodes[GPU].nodes+g2;
- // Enable P2P Read for Ampere/NVLink only
- if ((gpu1->gpu.cudaCompCap == gpu2->gpu.cudaCompCap) && (gpu1->gpu.cudaCompCap == 80)) *read = 1;
- }
- return ncclSuccess;
- }
然后判断当前GPU和其他GPU是否可以通过shm通信,因为在docker环境中如果shm挂载的不一样就无法通信,如果无法通过shm通信的话就将path的count设置为0,之后会删除掉对应节点(但是这里有个疑问,shm不通的话为什么没有继续判断p2p是否可用)。
最后类似GPU,然后对所有的NIC执行ncclTopoSetPaths计算出路径,然后遍历每个NIC和每个GPU,判断是否支持gdr。
- ncclResult_t ncclTopoCheckGdr(struct ncclTopoSystem* system, int64_t busId, int netDev, int read, int* useGdr) {
- *useGdr = 0;
- // Get GPU and NET
- int n, g;
- NCCLCHECK(ncclTopoIdToIndex(system, NET, netDev, &n));
- struct ncclTopoNode* net = system->nodes[NET].nodes+n;
- NCCLCHECK(ncclTopoIdToIndex(system, GPU, busId, &g));
- struct ncclTopoNode* gpu = system->nodes[GPU].nodes+g;
- // Check that both the NIC and GPUs support it
- if (net->net.gdrSupport == 0) return ncclSuccess;
- if (gpu->gpu.gdrSupport == 0) return ncclSuccess;
- if (read) { // For reads (sends) only enable under certain conditions
- int gdrReadParam = ncclParamNetGdrRead();
- if (gdrReadParam == 0) return ncclSuccess;
- if (gdrReadParam < 0) {
- int nvlink = 0;
- // Since we don't know whether there are other communicators,
- // it's better to keep things local if we have a single GPU.
- if (system->nodes[GPU].count == 1) nvlink = 1;
- for (int i=0; i<system->nodes[GPU].count; i++) {
- if (i == g) continue;
- if (gpu->paths[GPU][i].type == PATH_NVL) {
- nvlink = 1;
- break;
- }
- }
- if (!nvlink) return ncclSuccess;
- }
- }
- // Check if we are close enough that it makes sense to enable GDR
- int netGdrLevel = PATH_PXB;
- NCCLCHECK(ncclGetLevel(&ncclTopoUserGdrLevel, NULL, "NCCL_NET_GDR_LEVEL"));
- if (ncclTopoUserGdrLevel != -2) netGdrLevel = ncclTopoUserGdrLevel;
- int distance = gpu->paths[NET][n].type;
- if (distance > netGdrLevel) {
- INFO(NCCL_NET,"GPU Direct RDMA Disabled for GPU %lx / HCA %d (distance %d > %d)", busId, netDev, distance, netGdrLevel);
- return ncclSuccess;
- }
- *useGdr = 1;
- INFO(NCCL_NET,"GPU Direct RDMA Enabled for GPU %lx / HCA %d (distance %d <= %d), read %d", busId, netDev, distance, netGdrLevel, read);
- return ncclSuccess;
- }
这里除了看之前判断是否支持gdr之外,还要看GPU和NIC之间的距离是否小于netGdrLevel,netGdrLevel默认是PATH_PXB,用户也可以自定义,默认值为PXB的原因可见官方文档:
Even though the only theoretical requirement for GPUDirect RDMA to work between a third-party device and an NVIDIA GPU is that they share the same root complex, there exist bugs (mostly in chipsets) causing it to perform badly, or not work at all in certain setups.
We can distinguish between three situations, depending on what is on the path between the GPU and the third-party device:
PCIe switches only
single CPU/IOH
CPU/IOH <-> QPI/HT <-> CPU/IOH
The first situation, where there are only PCIe switches on the path, is optimal and yields the best performance. The second one, where a single CPU/IOH is involved, works, but yields worse performance ( especially peer-to-peer read bandwidth has been shown to be severely limited on some processor architectures ). Finally, the third situation, where the path traverses a QPI/HT link, may be extremely performance-limited or even not work reliably.
可以看到在只有经过PCIe switch的时候性能最好,在经过CPU的时候性能较差,在跨numa的时候性能很差,甚至不可用。
当p2p或者gdr不支持的时候,会通过CPU进行中转,通过getLocalCpu找到最近的CPU c。
- static ncclResult_t getLocalCpu(struct ncclTopoSystem* system, int gpu, int* retCpu) {
- // Find the closest CPU to a GPU
- int minHops = 0;
- int localCpu = -1;
- struct ncclTopoLinkList* paths = system->nodes[GPU].nodes[gpu].paths[CPU];
- for (int c=0; c
nodes[CPU].count; c++) { - int hops = paths[c].count;
- if (minHops == 0 || hops < minHops) {
- localCpu = c;
- minHops = hops;
- }
- }
- if (localCpu == -1) {
- WARN("Error : could not find CPU close to GPU %d", gpu);
- return ncclInternalError;
- }
- *retCpu = localCpu;
- return ncclSuccess;
- }
然后addCpuStep将 i1 到 i2 的路径修改为 i1 到 c 的路径 + cpu到 i2 的路径。
- static ncclResult_t addCpuStep(struct ncclTopoSystem* system, int c, int t1, int i1, int t2, int i2) {
- struct ncclTopoNode* cpuNode = system->nodes[CPU].nodes+c;
- struct ncclTopoNode* srcNode = system->nodes[t1].nodes+i1;
- int l=0;
- // Node 1 -> CPU
- for (int i=0; i<srcNode->paths[CPU][c].count; i++) srcNode->paths[t2][i2].list[l++] = srcNode->paths[CPU][c].list[i];
- // CPU -> Node 2
- for (int i=0; i<cpuNode->paths[t2][i2].count; i++) srcNode->paths[t2][i2].list[l++] = cpuNode->paths[t2][i2].list[i];
- // Update path characteristics
- srcNode->paths[t2][i2].count = l;
- srcNode->paths[t2][i2].type = std::max(srcNode->paths[CPU][c].type, cpuNode->paths[t2][i2].type);
- srcNode->paths[t2][i2].width = std::min(srcNode->paths[CPU][c].width, cpuNode->paths[t2][i2].width);
- return ncclSuccess;
- }
到这里ncclTopoComputePaths就完成了,接下来会通过ncclTopoTrimSystem删除图中不可达的GPU节点和用不到的NIC。
- ncclResult_t ncclTopoTrimSystem(struct ncclTopoSystem* system, struct ncclComm* comm) {
- int *domains;
- int64_t *ids;
- NCCLCHECK(ncclCalloc(&domains, system->nodes[GPU].count));
- NCCLCHECK(ncclCalloc(&ids, system->nodes[GPU].count));
- int myDomain = 0;
- for (int g=0; g
nodes[GPU].count; g++) { - struct ncclTopoNode* gpu = system->nodes[GPU].nodes+g;
- domains[g] = g;
- ids[g] = gpu->id;
- for (int p=0; pif (gpu->paths[GPU][p].count > 0) {domains[g] = std::min(domains[g], domains[p]);}}if (gpu->gpu.rank == comm->rank) myDomain = domains[g];}int ngpus = system->nodes[GPU].count;for (int i=0; iif (domains[i] == myDomain) continue;struct ncclTopoNode* gpu = NULL;int g;for (g=0; g
nodes[GPU].count /* This one varies over the loops */; g++) { gpu = system->nodes[GPU].nodes+g;if (gpu->id == ids[i]) break; else gpu=NULL;}if (gpu == NULL) {WARN("Could not find id %lx", ids[i]);free(domains);free(ids);return ncclInternalError;}NCCLCHECK(ncclTopoRemoveNode(system, GPU, g));}comm->localRanks = system->nodes[GPU].count;if (system->nodes[GPU].count == comm->nRanks) {for (int n=system->nodes[NET].count-1; n>=0; n--)NCCLCHECK(ncclTopoRemoveNode(system, NET, n));}free(domains);free(ids);return ncclSuccess;}首先通过类似并查集的思路将多个GPU节点合并成多个集合,myDomain为当前rank的GPU所对应的集合号,然后将不属于myDomain集合的GPU节点在图中删除掉,最后判断下如果comm的rank数等于当前图中的gpu节点数,那么说明不需要网卡,所以也将网卡从图中删除。
得到新的图结构后再重新执行一次ncclTopoComputePaths就得到最终各个节点之间的路径了。
(本文经授权后由OneFlow发布。原文:https://blog.csdn.net/KIDGIN7439/article/details/127849771)
其他人都在看
试用OneFlow:github.com/Oneflow-Inc/oneflow/
-
相关阅读:
linux安装mysql8.0
Qt OpenGL(二十四)——Qt OpenGL 核心模式-实现彩色三角形
GitHub标星65k,阿里面试核心技术手册,我不允许还有人没看过!
不要慌,选择排序也是一样简单的
CellMarker 2.0 | 鼠标点一点就完成单细胞分析的完美工具~
队列题目:用队列实现栈
Windows下解决Loading composer repositories with package information 慢的问题。
docker搭建minio服务器,解决内网穿透后外网无法访问问题
node安装,nvm管理器
马斯克热搜体质无疑,称已将大脑上传云端,却遭网友热议!
- 原文地址:https://blog.csdn.net/OneFlow_Official/article/details/131843165
