-
迈向100倍加速:全栈Transformer推理优化

作者 | 符尧,爱丁堡大学博士生
OneFlow编译
翻译|宛子琳、杨婷
假设有两家公司,它们拥有同样强大的模型。公司A可以用1个GPU为10个用户提供模型,而公司B可以用1个GPU为20个用户提供模型。从长远来看,谁会在竞争中获胜呢?
答案是公司B,因为它的成本更低。
假设一位研究人员提出了一种超级聪明的解码方法:这种方法拥有巧妙的算法和扎实的数学基础,但无法与FlashAttention兼容。它能在生产环境中使用吗?
可能不行,因为FlashAttention对大规模模型部署至关重要。
对Transformer推理的深入理解对研究和生产极为有益。然而在现实中,大规模生产通常与前沿研究的关联并不密切,了解算法的人可能并不了解MLSys,反之亦然。
本文讨论了全栈Transformer推理优化,从A100内存层次结构等硬件规格,到FlashAttention和vLLM等MLSys方法,再到专家混合等模型架构,以及推测性解码(Speculative Decoding)及其变体等解码算法。我们确定了一个最基本的事实:Transformer推理受限于内存,且大部分优化(无论来自MLSys还是建模)都基于/利用了这一事实。就像在角色扮演游戏中添加buff一样,可以看到Transformer推理是如何逐步扩展和加速的。
(本文由OneFlow编译发布,转载请联系授权。原文:https://yaofu.notion.site/Towards-100x-Speedup-Full-Stack-Transformer-Inference-Optimization)
1
硬件:GPU上的推理
首先,我们将探讨GPU架构,特别是其内存层次结构。我们确定了两个重要模式:计算限制(compute bound)和内存限制(memory bound),并讨论了大规模Transformer推理受内存限制的原因。大部分优化都基于Transformer推理受内存限制这一基本事实,例如只要我们提高FLOP利用率,就能提高效率。
1.1 初步推理
1.1.1 GPU架构
GPU架构总体如下图所示:
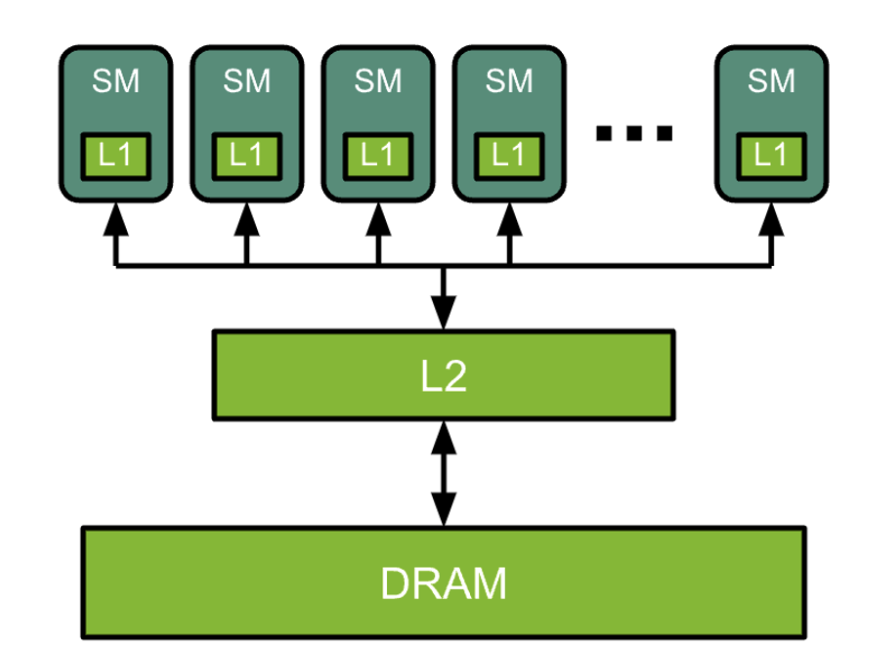
-
基础部分:DRAM(动态随机存取存储器)、L2缓存和SM(流处理器单元)
-
与CPU对比
-
SM类似于CPU核心,但具有更高级的并行性
-
L2缓存和DRAM类似于CPU的L2缓存和DRAM
-
在Flash Attention论文中,L2缓存被称为SRAM(静态随机存取存储器)
-
-
A100 80G SXM
-
108个SM,DRAM容量为80GB,有40M L2缓存
-
SM内部包含什么?

L1缓存:指令和数据
张量核心:进行矩阵乘法运算的地方。回想一下,神经网络计算基本上就是巨大批量的矩阵乘法。
1.1.2 GPU编程基础
在执行model.generate(prompt)时,我们进行以下操作:
-
内存访问:
-
从高带宽内存(HBM)加载模型权重到L2缓存,然后传输到SM(流处理器单元)
-
-
计算:
-
在SM中执行矩阵乘法,SM请求张量核心执行计算
-
-
A100:
-
108个SM,DRAM容量为80G,40M L2缓存
-
bf16张量核心:每秒312万亿浮点运算(TFLOPS)
-
DRAM内存带宽为2039GB/秒 = 2.039T/秒
-
-
如果模型很大,我们将其分割到多个GPU上,比如两个由NVLink连接的GPU
-
NVLink 300GB/秒 = 0.3T/秒
-
我们大致观察了速度层次结构。尽管不能直接比较,但它们的数量级差异是我们需要优化的主要方面:
-
312T(SM计算) > 2.03T(DRAM内存访问) > 0.3T=300G(NVLink跨设备通信) > 60G(PCIe跨设备通信)
-
-
这意味着,如果我们希望速度更快,我们应该尽力:
-
充分利用SM
-
减少单个GPU的内存访问(因为它比计算慢得多),
-
减少GPU之间的通信(因为它甚至比内存访问还要慢)。
-
1.1.3 计算限制与内存限制
如何确定我们是否充分利用了SM呢?我们通过以下方式检查是否计算或内存限制:
-
定义每字节GPU操作 = flop / 内存带宽
-
A100 = 312 / 2.039
-
-
定义计算强度 = 计算 / 内存访问
-
如果计算强度大,说明程序更会受到计算限制;如果计算强度较小,则更受内存限制。
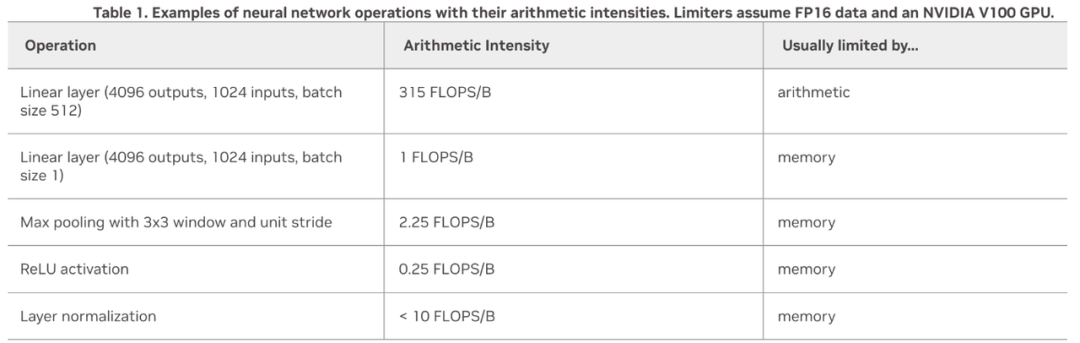
-
增加批次大小会将行为从内存限制变为计算限制。
-
内核融合:减少了内存访问操作,因为我们将多个操作合并为一个操作。
1.2 Transformer推理基础
1.2.1 预填充和解码
调用model.generate(prompt)时有两个步骤:
-
预填充:
-
为提示计算键值(kv)缓存。
-
这一步骤受计算限制,因为我们并行计算了一系列词元。
-
-
解码:
-
自回归采样下一个词元。
-
这一步骤受内存限制,因为我们仅计算一个词元,未充分利用SM。
-
1.2.2 Transformer推理受内存限制
增加批处理大小可以将模式从内存限制变为计算限制,正如Kipply博客《大型语言模型的推理演算》中的下图所示。
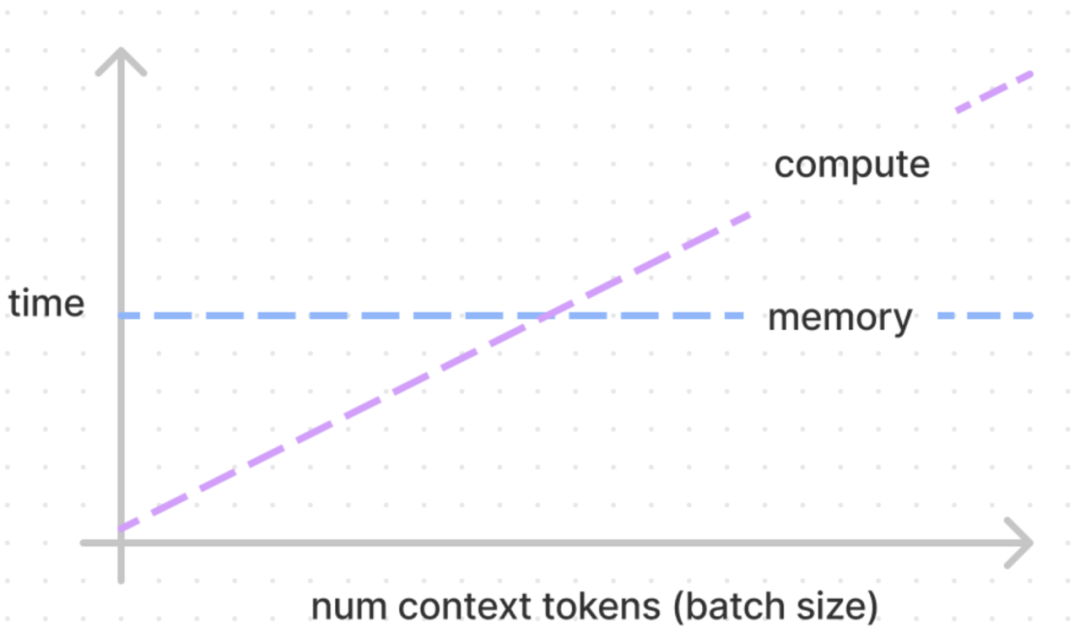
-
因为解码每次只采样一个词元。
-
增加批次大小提高了硬件效率。
-
因为我们同时计算多个词元。
-
大型批次从内存限制变为计算限制。
-
-
然而,我们可能无法使用太大型的批次大小,因为GPU内存有限,目前最大为80GB。
1.2.3 内存布局

正如我们所看到的,为了在bf16格式下运行一个13B模型,我们大约只有10GB的内存来存储kv缓存。这意味着:
-
不能使用太大型的批次(尽管我们希望使用更大的批次大小以提高效率)
-
也不能处理太长的序列,尽管我们确实希望能够处理长度为100k的序列。
1.2.4 在线与离线推理,吞吐量vs时延
-
离线:吞吐量优化
-
我们关注这种情况,因为希望能够离线评估模型,例如,在100个基准测试上运行一个中间的预训练检查点(checkpoint),用于验证预训练是否情况良好。
-
增加批次大小是有帮助的,但需要记住当前单个设备的最大内存为80GB。
-
-
在线:时延和吞吐量权衡
-
当批次大小较大型时(假设仍然适配内存),会受到计算吸纳之,随后时延会相应增加。
-
时延不应慢于人类的阅读速度,否则用户会抱怨,或者转而使用竞争对手的模型。
-
但再次强调,我们确实希望使用更大的批次大小以提高效率。
-
1.2.5 上下文长度扩展
到目前为止,我们的假设都是基于提示不长(低于4k)的情况。接下来,我们将考虑提示超过100k的情况,希望模型阅读多个PDF文件,然后进行文档问答。
-
预填充
-
这一次,预填充需要花费更长时间,因为输入长度很长
-
这种情况下,生成首个词元的时延很重要,因为用户希望在10秒内看到模型生成的响应。
-
大型KV缓存
-
由于上下文长度很长,我们需要一个大型的键值(KV)缓存。
-
-
目前就改进这方面的推理而言,人们做的工作似乎并不多。
2
MLSys:Flash Attention和vLLM
本节讨论了如何充分利用GPU内存层次结构。vLLM提供了一种进行GPU内存管理的方法,就像在操作系统中管理CPU虚拟内存一样;Flash Attention展示了如何通过在SM上执行大部分操作来有效减少内存IO,从而显著减少内存访问计算开销。
2.1 vLLM和Paged Attention
由于GPU内存有限,我们希望合理使用它来存储键值(kv)缓存。然而,GPU或PyTorch本身并不会自动提供将KV缓存置入内存的最佳方式,而其默认策略实际上相当糟糕。这激发了vLLM中用于GPU内存管理的Paged Attention:
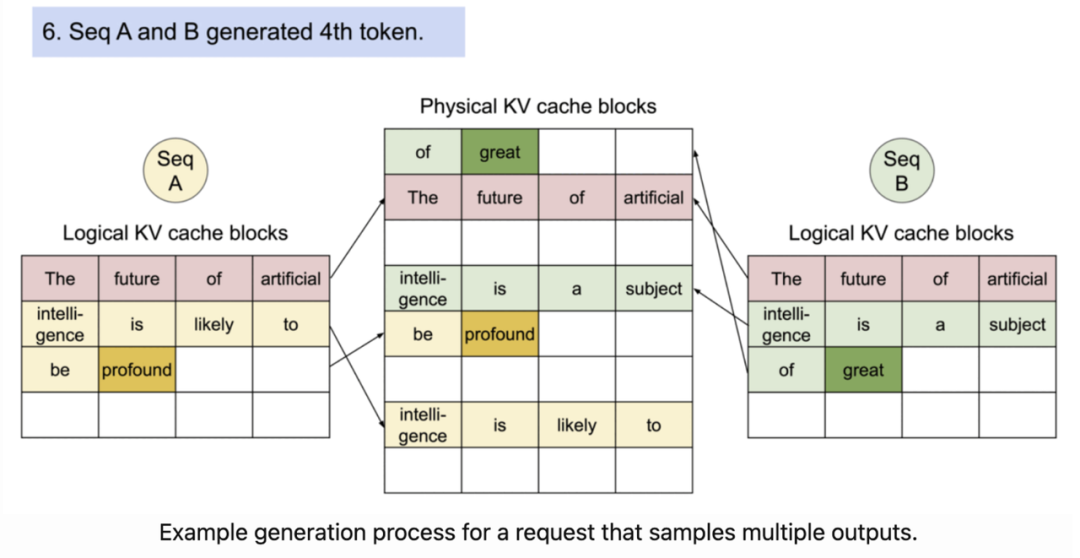
-
Paged Attention基本构建了一个类似于CPU内存管理的内存管理系统,以减少内存碎片并充分利用内存吞吐量
-
现在这成为了Transformer推理的首要选择
2.2 Flash attention
对每位从业者来说都是必备的,请简单记住完整的算法。
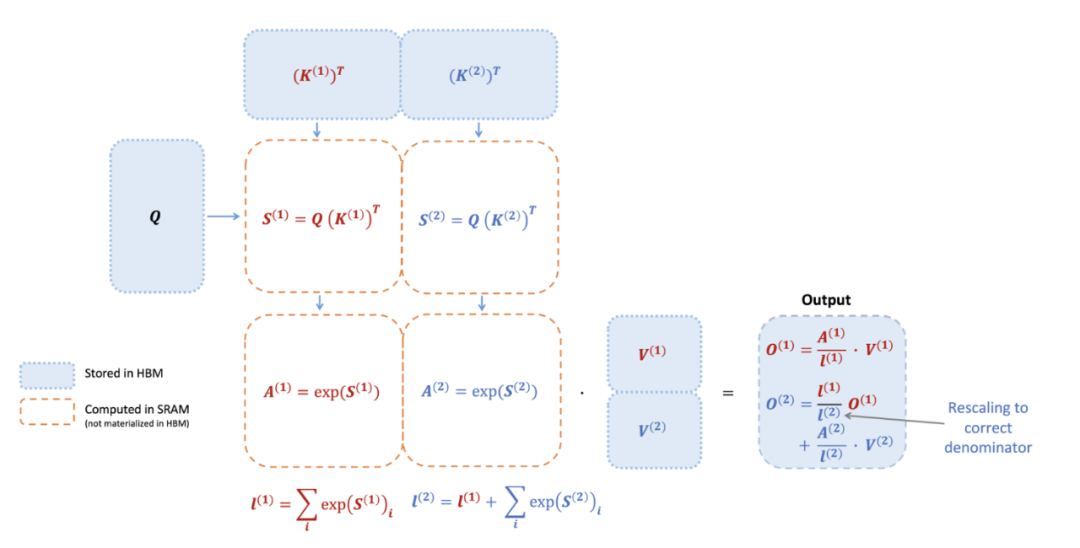
要点:
-
不要将完整的注意力矩阵存储在HBM中,而是对点积进行分块计算(blockwise computation),以便所有计算都在L2高速缓存中执行。
主要优势:
-
大幅减少内存使用,可以使用蛮力法(即“brutal force”,通过穷举所有可能性来解决问题)处理包含100k上下文长度的情况——没错,并没有使用复杂算法来处理100k上下文长度,而是采用了蛮力法。
-
在原始论文中,作者们最多只测试了16k,但其实完全可以处理100k的上下文长度。
-
-
大幅提高吞吐量,尤其是对于小模型,其中大部分浮点运算用于点积操作。
2.3 Flash解码

要点:不再使用一个查询来扫描整个KV缓存,而是复制查询,以便可以并行扫描KV缓存的不同块(chunk)。
3
建模:架构与解码算法
现在我们进入一个大家更熟悉的领域。我们将从蒸馏(distillation)和量化(quantization)等标准且广为人知的技术开始,然后深入探讨专家混合(MoE)和推测性解码(speculative decoding)等进阶主题。
3.1 经典方法
3.1.1 蒸馏和稀疏注意力
-
蒸馏:利用较大模型的输出/logits对小模型进行微调
-
对输出进行微调:如今,大家都很擅长从GPT进行蒸馏,所以这部分略过
-
对logits/分布进行微调的探索较少,一些结果表明,通过这种方法收敛速度更快,质量更好
-
-
稀疏和局部注意力,尤其适用于长上下文
-
在小模型时代,这一领域得到了深入研究(参见Yi Tay的出色调研,https://arxiv.org/abs/2009.06732),但不确定这些结果是否适用于更大规模的模型
-
在大模型时代,除了Mistral的滑动窗口注意力,这一领域几乎没有相关研究
-
3.1.2 量化
https://github.com/TimDettmers/bitsandbytes
-
最基本的方法,将模型权重量化为int 8。
-
量化如今是部署大模型的必备步骤。好消息是,它实际上并不会对性能造成实质损害。

-
Yi-34B聊天模型的4位量化仅需17G内存。而基准测试的性能几乎相同。
-
实际上它的速度相当快,你可以在Hugging Face(https://huggingface.co/spaces/01-ai/Yi-34B-Chat)上进行尝试。
3.1.3 多查询注意力和组查询注意力
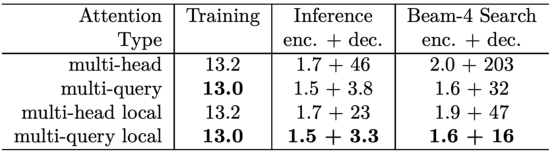
-
通常情况下,多查询注意力通过同时减少内存和计算,显著加快了训练和推理速度。
-
多查询注意力也是一个很好的例子,小模型与大模型在此方面的差异并不明显:对于7B这样的小模型,多查询注意力不如全注意力,但当模型达到70B时,多查询注意力的性能基本上与全注意力相同。LLaMA2 7B使用全注意力,而70B使用组查询注意力。
-
现有的顶尖大模型默认使用多查询注意力。
3.2 进阶技术
3.2.1 专家混合模型
从头开始预训练
-
假设我们有7B激活单元,总共34B参数。
-
能否实现以下目标?
-
与34B相似的性能
-
优于34B的吞吐量
-
与7B相似的时延 最近发布的Mistral MoE使上述目标成为了可能,详见推特上的讨论(https://twitter.com/Francis_YAO_/status/1733686003687112983)
-
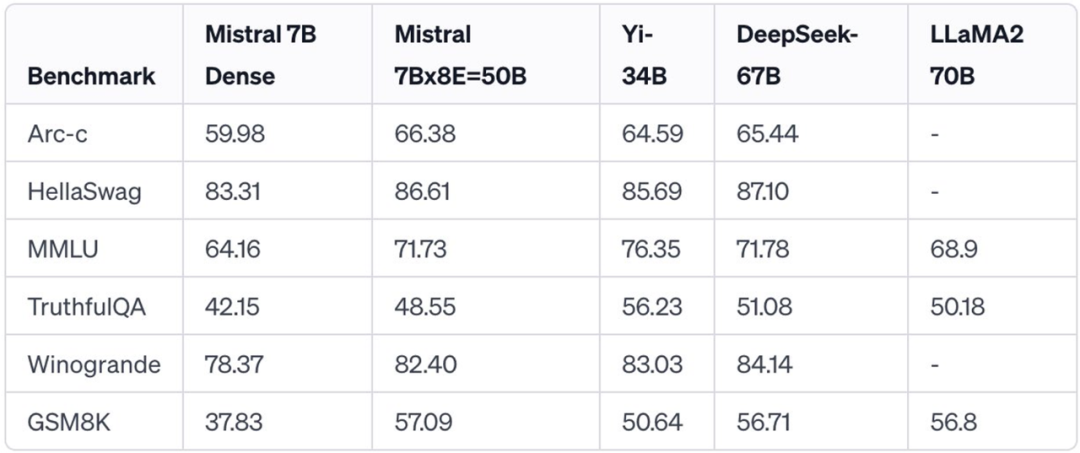
如上表所示:
-
性能:50B的MoE Mistral模型,其7B的密集部分在性能上接近于34B的Yi模型和67B的DeepSeek模型
-
推理效率:MoE的密集部分为7B,其中包含前2的激活单元
Mistral MoE展示了降低更小模型成本的同时,取得与更大模型相当的性能的可能性。

-
参考文献:
-
Zhang等,2021年。https://arxiv.org/abs/2110.01786
-
Zhang等,2023年。https://arxiv.org/abs/2305.18390
-
由Dmytro的Twitter帖子中的图表可知:
-
当并发性较低时,大部分时间都用于将两个激活的专家模型加载到内存中,这比密集层小,因此需要的内存访问时间更少,从而降低了时延。
换句话说,对于单个查询,MoE的时延低于密集层,因为我们需要从内存中读取的参数更少。
-
当并发性较高时,我们进入了flop限制的状态,但由于MoE的激活少于密集层,因此吞吐量更高。
换句话说,对于许多并发查询,MoE具有更高的吞吐量,因为:

随之而来的一个问题是,假如我已经训练了一个大型密集模型,是否可以将其转换为MoE模型?
-
MoE化(MoEfication):将一个密集模型分解为MoE模型,使其
-
具有小型模型的高效
-
同时拥有大型密集模型的强大性能。
-
-
参考文献:
-
Zhang等,2021年。https://arxiv.org/abs/2110.01786
-
Zhang等,2023年。https://arxiv.org/abs/2305.18390
-
3.2.2 提前退出
此处的要点是:对于简单词元,我们不需要计算所有的Transformer层,计算部分层就够了,因为它们是简单词元。
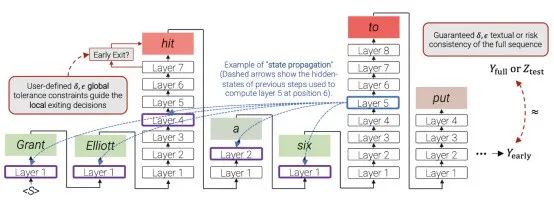
-
对于所有词元,使用一个门控(gate)来确定是否提前退出或继续计算
参考文献:
-
Schuster等,2022年。Confident Adaptive Language Modeling
-
Bae等,2023年。https://arxiv.org/abs/2310.05424
3.2.3 分块解码
推测性解码
关键在于,逐词元解码不能充分利用SM的计算能力,因此我们希望能够一次解码多个词元。以下文章值得参考:
-
Leviathan et. al. 2022. Fast Inference from Transformers via Speculative Decoding
-
Chen et. al. 2023. Accelerating Large Language Model Decoding with Speculative Sampling
-
Liu et. al. 2023. Online Speculative Decoding
-
Leviathan等,2022年。Fast Inference from Transformers via Speculative Decoding
-
Chen等,2023年。Accelerating Large Language Model Decoding with Speculative Sampling
-
Liu等,2023年。Online Speculative Decoding

使用小型草稿模型(draft model)存在以下缺点:
-
性能较弱,因此在一些具有挑战性的领域(如编码)中,拒绝率(rejection rate)可能较高。
-
我们需要在GPU中放入两个模型,但这已经耗尽了GPU内存。
因此,我们希望将大模型作为自身的提案模型(proposal model),因为
-
性能较强,因此可以降低拒绝率。
-
只需在内存中保留一个模型。
这就是我们推行Medusa的原因:
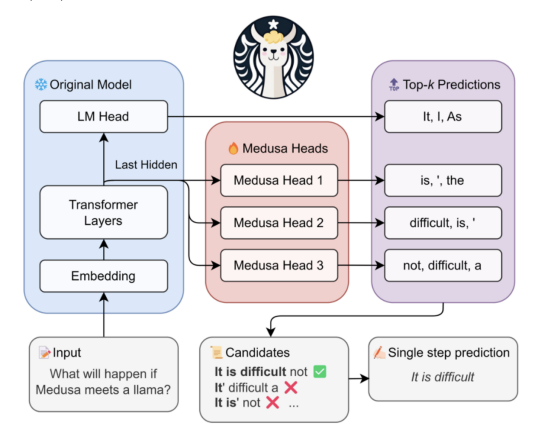
-
使用多头同时解码多个词元
-
使用大模型本身作为草稿模型
4
本文尚未涵盖的内容
-
深水(Deep water)硬件和MLSys
-
我对MLSys还很陌生,因此不得不向朋友询问自己的理解是否正确。因此,尽管我尝试覆盖最重要的基础知识,但我对MLSys的理解仍然仅是皮毛。
-
还有许多涵盖硬件和MLSys的精彩文章,我将在文末添加相关参考文献
-
-
超大模型的分布式推理。参见Pope等人的Efficiently Scaling Transformer Inference(https://arxiv.org/abs/2211.05102)
-
关键技术:模型分片(model sharding)、流水并行和张量并行
-
持续批处理和类似的库DeepSpeed MII(https://github.com/microsoft/DeepSpeed-MII)
-
-
对蒸馏的详细讨论
-
更进阶的分块解码
-
前向解码(lookahead decoding,https://lmsys.org/blog/2023-11-21-lookahead-decoding/)
-
基于检索的推测性解码(https://github.com/FasterDecoding/REST)
-
EAGLE(https://sites.google.com/view/eagle-llm)
-
5
个人选择
不幸的是,对于大部分模型架构论文而言,其收益和真正重要的工作大多来自MLSys,而非来自论文。实际上,许多花哨的论文并不切合实际,它们无法兼容SOTA MLSys的最新进展,如模型并行和Flash Attention。因此,亲爱的研究同行们,是时候动手实践,仔细研究真正的代码了。
然而,确实有一些来自建模方面的性能收益,以下是我最喜欢的技术,以备你的不时之需:
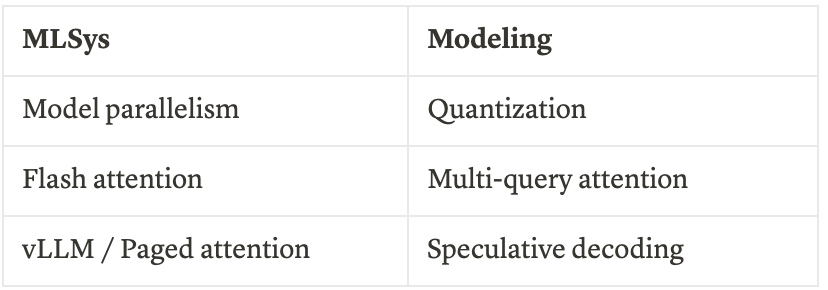
6
结论
本文回顾了从GPU架构到MLsys方法,从模型架构到解码算法的全栈Transformer推理优化方法。可以看出,大部分性能提升都来自于一个原则的利用:Transformer推理受内存限制,因此我们可以释放额外的计算能力/flops。其次,优化要么来自于优化内存访问,比如Flash Attention和Paged Attention,要么来自于释放计算能力,比如Medusa和前向解码。
我们相信MLSys和建模仍有许多改进空间。在即将到来的2024年,随着模型变得更大、上下文变得更长以及随着更多开源MoE(混合专家模型)、更高内存带宽和更大内存容量的硬件,以及具有更大DRAM和专用计算引擎的移动设备的亮相,将出现更强大且人人可操作、可访问的AI。一个新时代即将到来。
参考文献
-
https://pytorch.org/blog/accelerating-generative-ai-2/
-
https://arxiv.org/abs/2302.14017
-
https://arxiv.org/abs/2211.05102
-
https://kipp.ly/transformer-inference-arithmetic/
-
https://docs.nvidia.com/deeplearning/performance/dl-performance-gpu-background/index.html
-
https://www.baseten.co/blog/llm-transformer-inference-guide/
-
https://cursor.sh/blog/llama-inference
-
https://lilianweng.github.io/posts/2023-01-10-inference-optimization/
-
https://arxiv.org/abs/2311.03687
其他人都在看
试用OneFlow: github.com/Oneflow-Inc/oneflow/
 http://github.com/Oneflow-Inc/oneflow/
http://github.com/Oneflow-Inc/oneflow/ -
-
相关阅读:
vue实战——路由访问权限【详解】
Python网络编程(socket)
Android 12 正式发布 | 开发者们的全新舞台
CentOS 7 源码安装 Zabbix 6.0
浅读-《深入浅出Nodejs》
avec2013数据集谁有吗?可以分享一下吗?跪求
一文说透kafka底层架构
【Java】利用反射设置属性对象
简述WPF中MVVM的设计思想
木聚糖-聚乙二醇-牛血清白蛋白,BSA-PEG-Xylan,牛血清白蛋白-PEG-木聚糖
- 原文地址:https://blog.csdn.net/OneFlow_Official/article/details/134984341