-
机器学习_类偏斜的误差度量
简介
偏斜类(skewed classes)的问题。类偏斜情况表现为我们的
训练集中有非常多的同一种类的实例,只有很少或没有其他类的实例。例如:我们希望用算法来预测癌症是否是恶性的,在我们的训练集中,只有 0.5%的实例是恶性肿瘤。假设我们编写一个非学习而来的算法,在所有情况下都预测肿瘤是良性的,那么误差只有 0.5%。
然而我们通过训练而得到的神经网络算法却有 1%的误差。这时,误差的大小是不能视为评判算法效果的依据的。查准率(Precision)和查全率(Recall) 我们将算法预测的结果分成四种情况:
- 正确肯定(True Positive,TP):预测为真,实际为真
- 正确否定(True Negative,TN):预测为假,实际为假
- 错误肯定(False Positive,FP):预测为真,实际为假
- 错误否定(False Negative,FN):预测为假,实际为真
则:
查准率=TP/(TP+FP)。例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率=TP/(TP+FN)。例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。这样,对于我们刚才那个总是预测病人肿瘤为良性的算法,其查全率是 0。

查准率和查全率之间的权衡
我们谈到查准率和召回率,作为遇到偏斜类问题的评估度量值。在很多应用中,我们希望能够保证查准率和召回率的相对平衡。
查准率(Precision)=TP/(TP+FP) 例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率(Recall)=TP/(TP+FN)例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
如果我们希望只在非常确信的情况下预测为真(肿瘤为恶性),即我们希望更高的查准率,我们可以使用比 0.5 更大的阀值,如 0.7,0.9。这样做我们会减少错误预测病人为恶性肿瘤的情况,同时却会增加未能成功预测肿瘤为恶性的情况。
如果我们希望提高查全率,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地检查、诊断,我们可以使用比 0.5 更小的阀值,如 0.3。我们可以将不同阀值情况下,查全率与查准率的关系绘制成图表,曲线的形状根据数
据的不同而不同.
然后为了说明模型更好,我们希望有一个帮助我们选择这个阀值的方法。一种方法是计算 F1 值(F1 Score),其计算公式为:
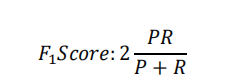
` 我们选择使得 F1 值最高的阀值。`- 1
-
相关阅读:
苹果电脑快捷键
苏宁一面复盘
LeetCode 第60天 | 84. 柱状图中最大的矩形 单调栈完结
一文带你摸清设计模式之单例模式!
学C++从Cmake学起
Stream流、FiLe和IO流、
leetcode 刷题日记 计算右侧小于当前元素的个数
让我看看谁还不会现在火爆的Spring Cloud,赶紧跟着大佬学起来
LoveCount统计“爱”——Scala-Spark实战应用案例
用RNN & CNN进行情感分析 - PyTorch
- 原文地址:https://blog.csdn.net/Don_t_always_ail/article/details/136877427