-
Python deepFM推荐系统,推荐算法,deepFM源码实战,deepFM代码模板
1.DeepFM介绍:
DeepFM(Deep Factorization Machine)是一种结合了深度学习和因子分解机的推荐模型。它在CTR(点击率)预测任务中表现出色,并能够有效地处理稀疏特征。
DeepFM模型由两个部分组成:因子分解机(Factorization Machine)和深度神经网络(Deep Neural Network)。
因子分解机(FM)部分利用了二阶多项式交互特征,可以有效地捕捉特征之间的交互关系。它将输入的特征向量分解为两个部分:一阶线性项和二阶交叉项。一阶线性项基于特征的原始值进行加权求和,而二阶交叉项通过内积计算不同特征之间的交叉权重。FM部分的输出表示了特征和交叉特征的组合信息。
深度神经网络(DNN)部分通过多层神经网络学习高阶特征的表达。DNN可以自动学习到更加抽象和复杂的特征表示,从而提升模型的性能。这些隐藏层间的全连接层允许模型进行端到端的训练,通过非线性的激活函数和权重参数的更新,逐渐提取和组合特征。
DeepFM模型通过将FM部分和DNN部分联合起来,充分利用了FM的低阶特征交叉和DNN的高阶特征学习能力。模型在训练过程中通过最小化预测值与真实值之间的差距来学习模型参数。在预测阶段,将输入的特征经过FM和DNN部分的计算得到最终的预测结果。
相比于传统的模型,DeepFM模型能够同时利用低阶和高阶的特征交叉信息,提高了模型的表达能力和预测准确率。同时,它可以处理大规模稀疏特征和高维特征的问题,并且模型结构相对简洁,计算效率较高。因此,DeepFM在推荐系统和广告点击率预测等任务中具有很高的应用价值。
论文精要如下:
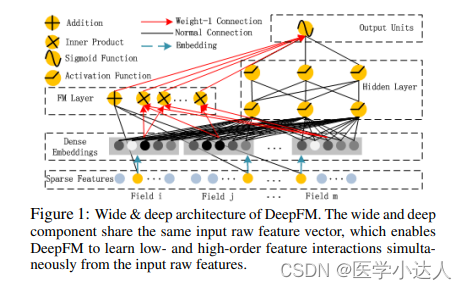
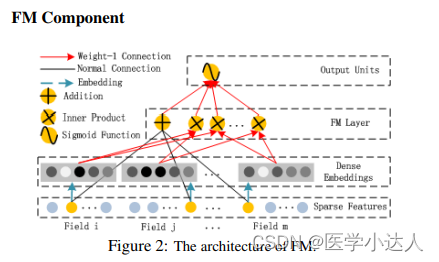
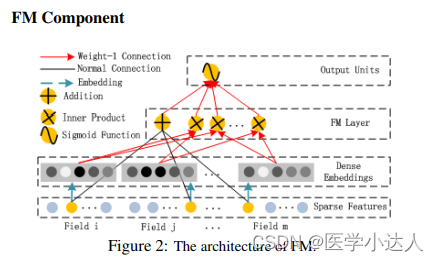
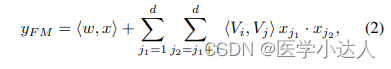

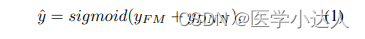
其实最后就是把两部分特征相加,然后通过sigmoid函数输出最后的概率值。
2.DeepFM代码实战:
main.py文件
- import numpy as np
- import torch
- import torch.optim as optim
- from torch.utils.data import DataLoader
- from torch.utils.data import sampler
- from model.DeepFM import DeepFM
- from data.dataset import CriteoDataset
- # 900000 items for training, 10000 items for valid, of all 1000000 items
- Num_train = 9000
- # load data
- train_data = CriteoDataset('./data', train=True)
- loader_train = DataLoader(train_data, batch_size=16,
- sampler=sampler.SubsetRandomSampler(range(Num_train)))
- val_data = CriteoDataset('./data', train=True)
- loader_val = DataLoader(val_data, batch_size=16,
- sampler=sampler.SubsetRandomSampler(range(Num_train, 10000)))
- feature_sizes = np.loadtxt('./data/feature_sizes.txt', delimiter=',')
- feature_sizes = [int(x) for x in feature_sizes]
- print(feature_sizes)
- model = DeepFM(feature_sizes, use_cuda=False)
- optimizer = optim.Adam(model.parameters(), lr=1e-4, weight_decay=0.0)
- model.fit(loader_train, loader_val, optimizer, epochs=5, verbose=True)
数据处理文件 data/dataset.py
- import torch
- from torch.utils.data import Dataset
- import pandas as pd
- import numpy as np
- import os
- continous_features = 13
- class CriteoDataset(Dataset):
- """
- Custom dataset class for Criteo dataset in order to use efficient
- dataloader tool provided by PyTorch.
- """
- def __init__(self, root, train=True):
- """
- Initialize file path and train/test mode.
- Inputs:
- - root: Path where the processed data file stored.
- - train: Train or test. Required.
- """
- self.root = root
- self.train = train
- if not self._check_exists():
- raise RuntimeError('Dataset not found.')
- if self.train:
- data = pd.read_csv(os.path.join(root, 'train.txt'))
- self.train_data = data.iloc[:, :-1].values
- self.target = data.iloc[:, -1].values
- else:
- data = pd.read_csv(os.path.join(root, 'test.txt'))
- self.test_data = data.iloc[:, :-1].values
- def __getitem__(self, idx):
- if self.train:
- dataI, targetI = self.train_data[idx, :], self.target[idx]
- # index of continous features are zero
- Xi_coutinous = np.zeros_like(dataI[:continous_features])
- Xi_categorial = dataI[continous_features:]
- Xi = torch.from_numpy(np.concatenate((Xi_coutinous, Xi_categorial)).astype(np.int32)).unsqueeze(-1)
- # value of categorial features are one (one hot features)
- Xv_categorial = np.ones_like(dataI[continous_features:])
- Xv_coutinous = dataI[:continous_features]
- Xv = torch.from_numpy(np.concatenate((Xv_coutinous, Xv_categorial)).astype(np.int32))
- return Xi, Xv, targetI
- else:
- dataI = self.test_data.iloc[idx, :]
- # index of continous features are one
- Xi_coutinous = np.ones_like(dataI[:continous_features])
- Xi_categorial = dataI[continous_features:]
- Xi = torch.from_numpy(np.concatenate((Xi_coutinous, Xi_categorial)).astype(np.int32)).unsqueeze(-1)
- # value of categorial features are one (one hot features)
- Xv_categorial = np.ones_like(dataI[continous_features:])
- Xv_coutinous = dataI[:continous_features]
- Xv = torch.from_numpy(np.concatenate((Xv_coutinous, Xv_categorial)).astype(np.int32))
- return Xi, Xv
- def __len__(self):
- if self.train:
- return len(self.train_data)
- else:
- return len(self.test_data)
- def _check_exists(self):
- return os.path.exists(self.root)
模型文件 model/DeepFM.py
- # -*- coding: utf-8 -*-
- """
- A pytorch implementation of DeepFM for rates prediction problem.
- """
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- import torch.optim as optim
- from time import time
- class DeepFM(nn.Module):
- """
- A DeepFM network with RMSE loss for rates prediction problem.
- There are two parts in the architecture of this network: fm part for low
- order interactions of features and deep part for higher order. In this
- network, we use bachnorm and dropout technology for all hidden layers,
- and "Adam" method for optimazation.
- You may find more details in this paper:
- DeepFM: A Factorization-Machine based Neural Network for CTR Prediction,
- Huifeng Guo, Ruiming Tang, Yunming Yey, Zhenguo Li, Xiuqiang He.
- """
- def __init__(self, feature_sizes, embedding_size=4,
- hidden_dims=[32, 32], num_classes=1, dropout=[0.5, 0.5],
- use_cuda=True, verbose=False):
- """
- Initialize a new network
- Inputs:
- - feature_size: A list of integer giving the size of features for each field.
- - embedding_size: An integer giving size of feature embedding.
- - hidden_dims: A list of integer giving the size of each hidden layer.
- - num_classes: An integer giving the number of classes to predict. For example,
- someone may rate 1,2,3,4 or 5 stars to a film.
- - batch_size: An integer giving size of instances used in each interation.
- - use_cuda: Bool, Using cuda or not
- - verbose: Bool
- """
- super().__init__()
- self.field_size = len(feature_sizes)
- self.feature_sizes = feature_sizes
- self.embedding_size = embedding_size
- self.hidden_dims = hidden_dims
- self.num_classes = num_classes
- self.dtype = torch.long
- self.bias = torch.nn.Parameter(torch.randn(1))
- """
- check if use cuda
- """
- if use_cuda and torch.cuda.is_available():
- self.device = torch.device('cuda')
- else:
- self.device = torch.device('cpu')
- """
- init fm part
- """
- self.fm_first_order_embeddings = nn.ModuleList(
- [nn.Embedding(feature_size, 1) for feature_size in self.feature_sizes])
- self.fm_second_order_embeddings = nn.ModuleList(
- [nn.Embedding(feature_size, self.embedding_size) for feature_size in self.feature_sizes])
- """
- init deep part
- """
- all_dims = [self.field_size * self.embedding_size] + \
- self.hidden_dims + [self.num_classes]
- for i in range(1, len(hidden_dims) + 1):
- setattr(self, 'linear_'+str(i),
- nn.Linear(all_dims[i-1], all_dims[i]))
- # nn.init.kaiming_normal_(self.fc1.weight)
- setattr(self, 'batchNorm_' + str(i),
- nn.BatchNorm1d(all_dims[i]))
- setattr(self, 'dropout_'+str(i),
- nn.Dropout(dropout[i-1]))
- def forward(self, Xi, Xv):
- """
- Forward process of network.
- Inputs:
- - Xi: A tensor of input's index, shape of (N, field_size, 1)
- - Xv: A tensor of input's value, shape of (N, field_size, 1)
- """
- """
- fm part
- """
- fm_first_order_emb_arr = [(torch.sum(emb(Xi[:, i, :]), 1).t() * Xv[:, i]).t() for i, emb in enumerate(self.fm_first_order_embeddings)]
- fm_first_order = torch.cat(fm_first_order_emb_arr, 1)
- #print(fm_first_order.shape)
- fm_second_order_emb_arr = [(torch.sum(emb(Xi[:, i, :]), 1).t() * Xv[:, i]).t() for i, emb in enumerate(self.fm_second_order_embeddings)]
- fm_sum_second_order_emb = sum(fm_second_order_emb_arr)
- fm_sum_second_order_emb_square = fm_sum_second_order_emb * \
- fm_sum_second_order_emb # (x+y)^2
- #print(fm_sum_second_order_emb_square.shape)
- fm_second_order_emb_square = [
- item*item for item in fm_second_order_emb_arr]
- fm_second_order_emb_square_sum = sum(
- fm_second_order_emb_square) # x^2+y^2
- fm_second_order = (fm_sum_second_order_emb_square -
- fm_second_order_emb_square_sum) * 0.5
- """
- deep part
- """
- deep_emb = torch.cat(fm_second_order_emb_arr, 1)
- deep_out = deep_emb
- for i in range(1, len(self.hidden_dims) + 1):
- deep_out = getattr(self, 'linear_' + str(i))(deep_out)
- deep_out = getattr(self, 'batchNorm_' + str(i))(deep_out)
- deep_out = getattr(self, 'dropout_' + str(i))(deep_out)
- """
- sum
- """
- total_sum = torch.sum(fm_first_order, 1) + \
- torch.sum(fm_second_order, 1) + torch.sum(deep_out, 1) + self.bias
- return total_sum
- def fit(self, loader_train, loader_val, optimizer, epochs=100, verbose=False, print_every=100):
- """
- Training a model and valid accuracy.
- Inputs:
- - loader_train: I
- - loader_val: .
- - optimizer: Abstraction of optimizer used in training process, e.g., "torch.optim.Adam()""torch.optim.SGD()".
- - epochs: Integer, number of epochs.
- - verbose: Bool, if print.
- - print_every: Integer, print after every number of iterations.
- """
- """
- load input data
- """
- model = self.train().to(device=self.device)
- criterion = F.binary_cross_entropy_with_logits
- for _ in range(epochs):
- for t, (xi, xv, y) in enumerate(loader_train):
- xi = xi.to(device=self.device, dtype=self.dtype)
- xv = xv.to(device=self.device, dtype=torch.float)
- y = y.to(device=self.device, dtype=torch.float)
- total = model(xi, xv)
- loss = criterion(total, y)
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
- if verbose and t % print_every == 0:
- print('Iteration %d, loss = %.4f' % (t, loss.item()))
- self.check_accuracy(loader_val, model)
- print()
- def check_accuracy(self, loader, model):
- if loader.dataset.train:
- print('Checking accuracy on validation set')
- else:
- print('Checking accuracy on test set')
- num_correct = 0
- num_samples = 0
- model.eval() # set model to evaluation mode
- with torch.no_grad():
- for xi, xv, y in loader:
- xi = xi.to(device=self.device, dtype=self.dtype) # move to device, e.g. GPU
- xv = xv.to(device=self.device, dtype=torch.float)
- y = y.to(device=self.device, dtype=torch.bool)
- total = model(xi, xv)
- preds = (F.sigmoid(total) > 0.5)
- num_correct += (preds == y).sum()
- num_samples += preds.size(0)
- acc = float(num_correct) / num_samples
- print('Got %d / %d correct (%.2f%%)' % (num_correct, num_samples, 100 * acc))
3. 项目数据在下方连接
deepFM数据下载链接
https://download.csdn.net/download/L_goodboy/88950471
-
相关阅读:
深入剖析:HTML页面从用户请求到完整呈现的多阶段加载与渲染全流程详解
网站SEO优化指北
数据挖掘学习笔记02——算法(分类、聚类、回归、关联)
随机函数变换示例
使用openpyxl库读取Excel文件数据
初学Matlab第一天
RabbitMQ 死信队列详解
好朋友离职了,一周面试了20多场,我直呼内行
本周内容整理
L6.linux命令每日一练 -- 第二章 文件和目录操作命令 -- touch和ls命令
- 原文地址:https://blog.csdn.net/L_goodboy/article/details/136656575