-
用云服务器构建gpt和stable-diffusion大模型
用云服务器构建gpt和stable-diffusion大模型
参考: DataWhale学习手册链接
一、前置知识
采用云服务器创建项目时,选择平台预先下载的镜像、数据和模型往往可以事半功倍。
- 镜像是一个包含了操作系统、软件、库以及其他运行时需要的所有内容的快照。使用镜像可以快速部署具有相同环境配置的虚拟机实例或容器,无需手动配置每个环境。这样能够确保在不同计算环境中实现环境的一致性,并方便应用程序的部署和迁移。
- 预训练模型则是准备好预训练好的大模型,可以直接下载,可以使用驱动云直接下载好的。或者麻烦点,使用
git lfs clone https://huggingface.co/THUDM/chatglm3-6b下载模型权重,模型权重数据太大,克隆时间太长。 - 数据,在创建项目时选择数据,可以将需要的数据集直接加载到云端环境中,方便模型训练和验证。
二、用云端属于自己的聊天chatGLM3
step1、项目配置
-
采用 趋动云 云端配置,环境采用
Pytorch2.0.1、python3.9、cuda11.7的镜像,预训练模型选择葱姜蒜上传的这个ChtaGLM3-6B模型 -
资源配置采用拥有24G显存的 B1.large ,最好设置一个最长运行时间,以免忘关环境,导致资源浪费。
step2、环境配置
成功配置好项目基本资源后,就可以进入JupyterLab开发环境了。现在需要在终端进一步配置环境,通过我们选择的模型资源中的加载的文件,我们首先要设置镜像源、克隆ChatGLM项目。
1、前置知识
-
apt-get是一个在 Debian 及其衍生发行版(比如 Ubuntu)中用来管理软件包的命令行工具。它的主要作用包括:- 安装软件包:使用
apt-get install命令可以安装指定的软件包,系统会自动解决依赖关系并下载安装所需的软件包。 - 升级软件包:通过
apt-get upgrade命令可以升级系统中已安装的软件包到最新版本。系统会检查可用的更新并进行相应的升级操作。 - 移除软件包:使用
apt-get remove命令可以移除系统中已安装的软件包,同时也会移除其相关的配置文件。 - 清理无用的软件包:通过
apt-get autoremove命令可以清理掉系统中不再需要的无用软件包。这些软件包通常是因为其他软件的升级或移除而留下来的。 - 更新软件包列表:使用
apt-get update命令可以更新本地软件包列表,以获取最新的软件包信息,包括可用的更新和安全修复程序。 - 升级发行版:通过
apt-get dist-upgrade命令可以升级整个发行版,包括进行系统核心的升级。
apt-get是一个强大的软件包管理工具,可以帮助用户方便地安装、升级、移除软件包,并保持系统中的软件包信息是最新的。 - 安装软件包:使用
-
git config --global url."https://gitclone.com/".insteadOf https://的作用是将 Git 在使用https://方式克隆(clone)远程仓库时,自动将 URL 中的https://替换为https://gitclone.com/。 -
pip config set global.index-url https://pypi.virtaicloud.com/repository/pypi/simple设置全局的 PyPI 镜像源为https://pypi.virtaicloud.com/repository/pypi/simple。PyPI(Python Package Index)是 Python 社区中最大的软件包仓库,开发者可以通过它来获取和安装各种 Python 包。默认情况下,pip 会从官方的 PyPI 仓库中获取包信息和下载包。 -
python3 -m pip install --upgrade pip的作用是使用 Python 3 自带的 pip 模块来升级当前系统中的 pip 工具到最新版本。python3 -m pip:使用 Python 3 自带的 pip 模块来执行 pip 相关操作。install --upgrade pip:安装最新版本的 pip 工具,而--upgrade标志表示即使已经安装了 pip,也要将其升级到最新版本。 -
pip install -r中的-r选项表示从指定的 requirements 文件中安装所有列出的 Python 包。 -
pip install peft:为解决大模型微调的一些问题,huggface开源的一个高效微调大模型-PEFT库(它提供了最新的参数高效微调技术,并且可以与Transformers和Accelerate进行无缝集成)-里面实现的方法,主要是针对transformer架构的大模型进行微调,当然repo中有对diffusion模型进行微调的案例
2、环境配置流程
-
升级apt,安装unzip
apt-get update && apt-get install unzip- 1
-
设置镜像源,升级pip
git config --global url."https://gitclone.com/".insteadOf https:// pip config set global.index-url https://pypi.virtaicloud.com/repository/pypi/simple python3 -m pip install --upgrade pip- 1
- 2
- 3
-
克隆chatGLM3模型的微调模型code
git clone https://github.com/THUDM/ChatGLM3.git- 1
-
进入项目目录
cd ChatGLM3- 1
-
安装项目依赖与peft,即模型代码运行所需要的必备库
由于最开始选择的镜像中包含torch,为避免重复安装,可以先把requirements.txt中的torch删掉
pip install -r requirements.txt pip install peft- 1
- 2
step3、创建镜像
由于,我们采用的镜像是系统预制的一些镜像,该镜像不具备保存功能,但是为了防止下次加载还得重新配置环境,可以当前环境制作成镜像,封装发布。
1、前置知识
Dockerfile 是用来构建 Docker 镜像的文本文件。通过 Dockerfile,您可以定义镜像中包含的文件、环境、依赖关系等信息。在 Dockerfile 中,您可以指定一系列指令,Docker 引擎将根据这些指令自动化地构建出一个完整的镜像。
一个典型的 Dockerfile 包含了一系列指令,如 FROM、RUN、COPY、CMD 等,用于描述镜像的构建过程。以下是一些常用的 Dockerfile 指令:
- FROM:指定基础镜像,即构建新镜像所基于的基础镜像。
- RUN:在镜像内执行命令,用于安装软件包、下载文件等操作。
- COPY:将文件从主机复制到镜像内的指定路径。
- CMD:设置容器启动时执行的默认命令或程序。
通过编写 Dockerfile,可以定义容器的环境、运行时配置以及应用程序所需的依赖项,**使得容器的部署和管理变得更加方便和可重复。**一旦编写好 Dockerfile,可以使用 Docker 命令构建镜像,并基于该镜像创建并运行容器。
2、创建镜像流程
-
点击右上角将当前环境制作为镜像
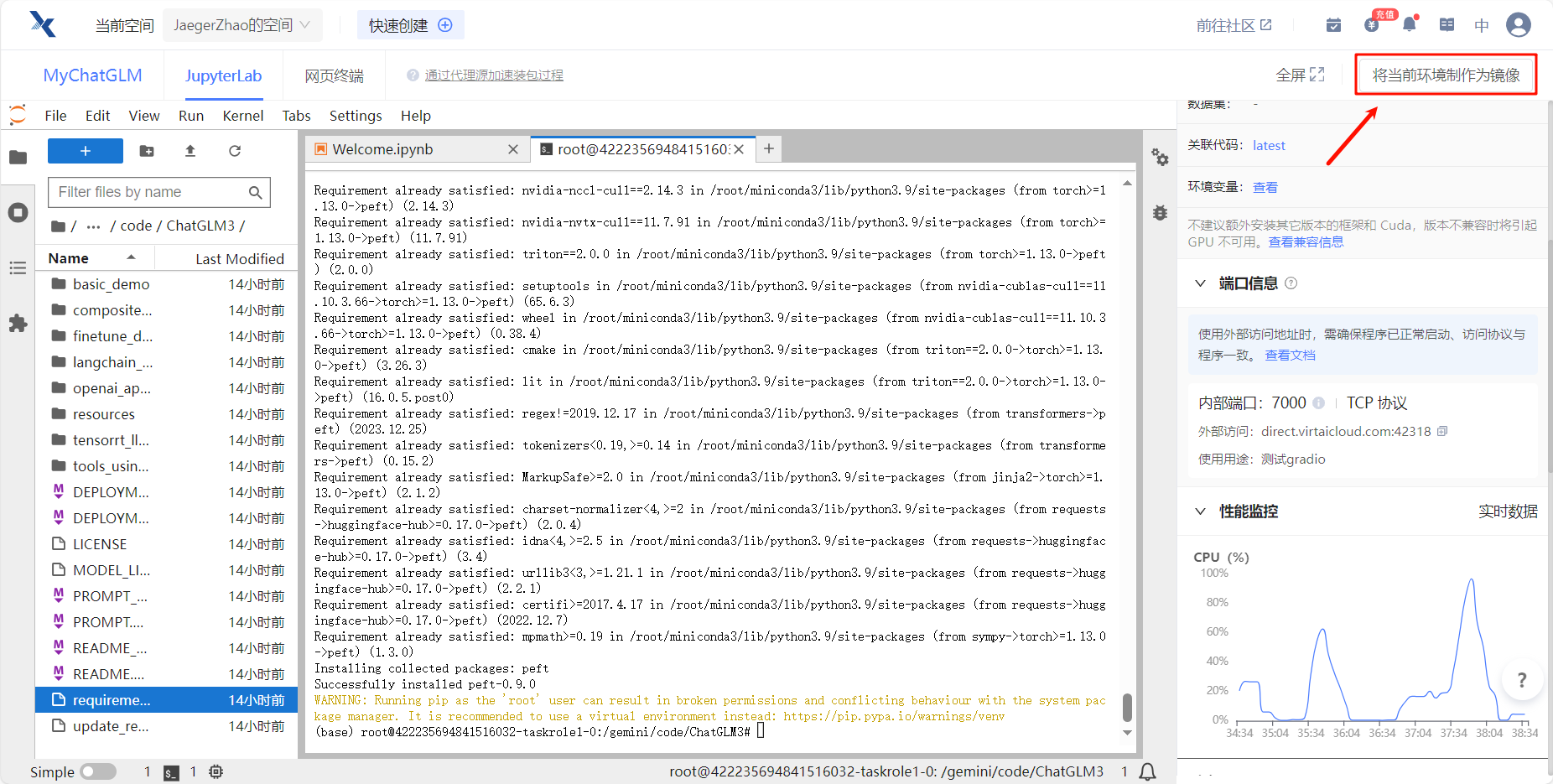
-
填写镜像名称,构建镜像,填写自定义镜像名称后,在Dockerfile中选择智能生成或者直接填写下边内容,以之前选择的基础镜像,创建镜像。
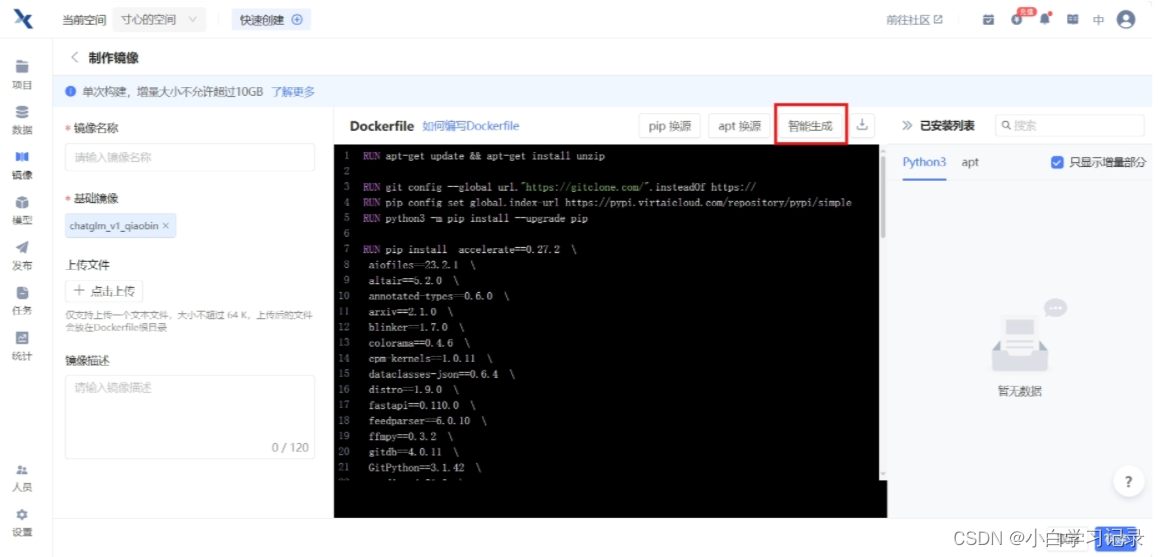
RUN apt-get update && apt-get install unzip RUN git config --global url."https://gitclone.com/".insteadOf https:// RUN pip config set global.index-url https://pypi.virtaicloud.com/repository/pypi/simple RUN python3 -m pip install --upgrade pip RUN pip install accelerate==0.27.2 \ aiofiles==23.2.1 \ altair==5.2.0 \ annotated-types==0.6.0 \ arxiv==2.1.0 \ blinker==1.7.0 \ colorama==0.4.6 \ cpm-kernels==1.0.11 \ dataclasses-json==0.6.4 \ distro==1.9.0 \ fastapi==0.110.0 \ feedparser==6.0.10 \ ffmpy==0.3.2 \ gitdb==4.0.11 \ GitPython==3.1.42 \ gradio==4.21.0 \ gradio_client==0.12.0 \ greenlet==3.0.3 \ h11==0.14.0 \ httpcore==1.0.4 \ httpx==0.27.0 \ huggingface-hub==0.21.4 \ jsonpatch==1.33 \ jupyter_client==8.6.0 \ langchain==0.1.11 \ langchain-community==0.0.27 \ langchain-core==0.1.30 \ langchain-text-splitters==0.0.1 \ langchainhub==0.1.15 \ langsmith==0.1.23 \ latex2mathml==3.77.0 \ loguru==0.7.2 \ markdown-it-py==3.0.0 \ marshmallow==3.21.1 \ mdtex2html==1.3.0 \ mdurl==0.1.2 \ openai==1.13.3 \ orjson==3.9.15 \ packaging==23.2 \ peft==0.9.0 \ protobuf==4.25.3 \ pydantic==2.6.3 \ pydantic_core==2.16.3 \ pydeck==0.8.1b0 \ pydub==0.25.1 \ PyJWT==2.8.0 \ python-multipart==0.0.9 \ regex==2023.12.25 \ requests==2.31.0 \ rich==13.7.1 \ ruff==0.3.2 \ safetensors==0.4.2 \ semantic-version==2.10.0 \ sentence-transformers==2.5.1 \ sentencepiece==0.2.0 \ sgmllib3k==1.0.0 \ shellingham==1.5.4 \ smmap==5.0.1 \ SQLAlchemy==2.0.28 \ sse-starlette==2.0.0 \ starlette==0.36.3 \ streamlit==1.32.0 \ tenacity==8.2.3 \ tiktoken==0.6.0 \ timm==0.9.16 \ tokenizers==0.15.2 \ toml==0.10.2 \ tomlkit==0.12.0 \ transformers==4.38.2 \ typer==0.9.0 \ typing_extensions==4.10.0 \ urllib3==2.2.1 \ uvicorn==0.28.0 \ watchdog==4.0.0 \ websockets==11.0.3 \ zhipuai==2.0.1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
-
等待镜像构建

-
构建成功后,在开发环境实例中修改镜像
在构建的项目中,点击右边栏的 开发 ,点击 修改挂载镜像 ,在 我的 里选择刚才创建的镜像。
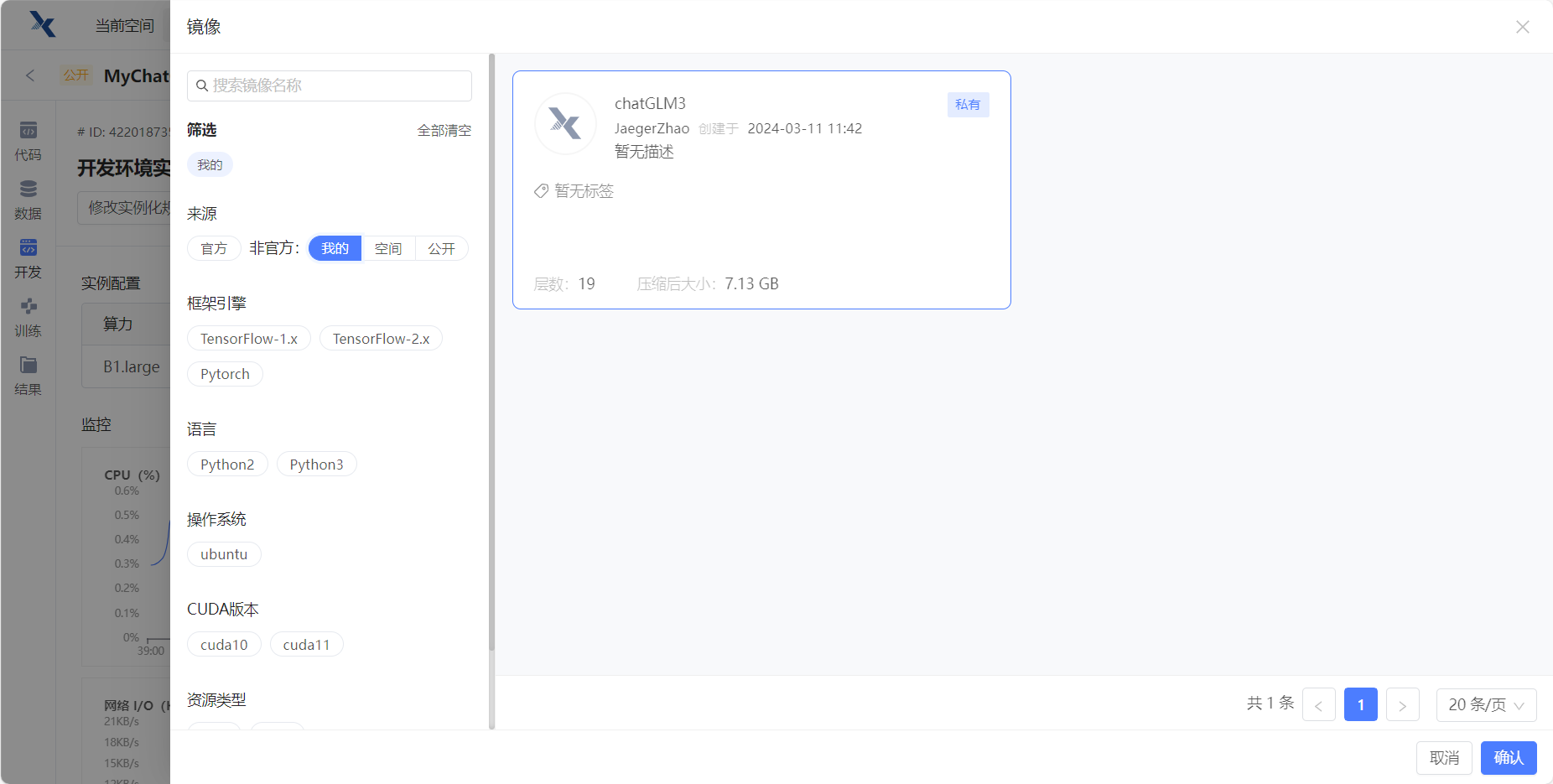
这样子之后就不用重复配置环境了。
step4、通过 Gradio 创建ChatGLM交互界面
1、前置知识
Gradio 是一个用于快速构建机器学习模型部署的开源库,它可以帮助快速创建简单而强大的交互式界面,用于展示和测试机器学习模型。通过 Gradio,可以轻松地将训练好的模型转化为可视化的 Web 应用程序,无需深度的前端知识。Gradio 提供了一个简单易用的 API,支持各种机器学习框架(如 TensorFlow、PyTorch 等),使得将模型部署为交互式应用变得非常容易。可以定义输入和输出的界面元素,包括文本框、滑块、图像上传等,以便用户与模型进行交互。
2、创建ChatGLM交互界面的流程
-
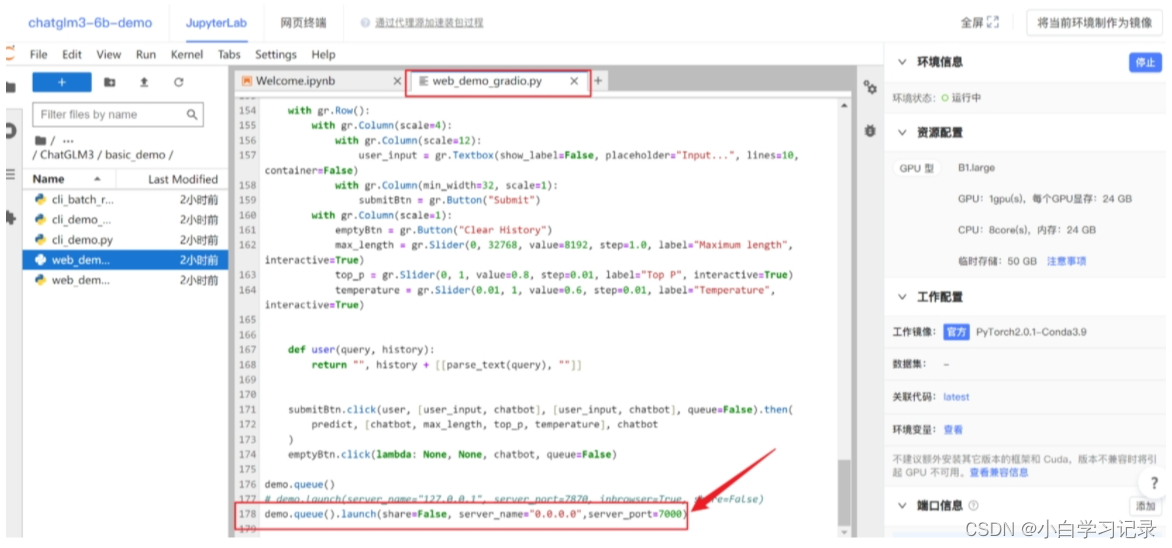
修改模型目录
双击
basic_demo编辑web_demo``_gradio``.py,将加载模型的路径修改为:/gemini/pretrain,如下图所示~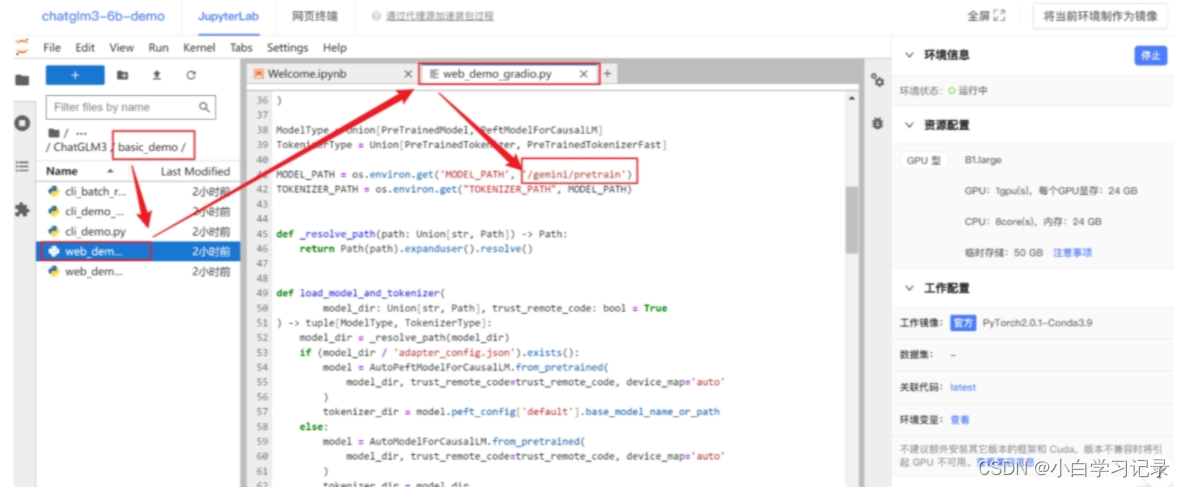
-
2、修改启动代码
接下来还需要修改一段启动代码,将滚动条拉到最后一行,启动代码修改为如下~
demo.queue().launch(share=False, server_name="0.0.0.0",server_port=7000)- 1
-
3、添加外部端口映射
在界面的右边添加外部端口:7000

-
4、运行gradio界面
点击左上选项卡,重新返回终端,运行web_demo_gradio.py
cd basic_demo python web_demo_gradio.py- 1
- 2
-
5、访问gradio页面
加载完毕之后,复制外部访问的连接,到浏览器打打开

可以看到,Gradio界面并不稳定,回复中夹杂指令字符
<|im_end|>与<|im_start|>。
step5、通过 streamlit 创建ChatGLM交互界面
1、前置知识
Streamlit 是一个用于快速构建数据应用程序的开源 Python 库。它可以帮助数据科学家和开发人员轻松地创建交互式的数据分析和展示界面,而无需深度的前端开发经验。通过 Streamlit,可以使用简单的 Python 脚本来创建数据应用程序,包括数据可视化、机器学习模型展示、文本分析等。Streamlit 提供了各种易于使用的组件,可以让用户快速构建交互式界面,包括图表、表格、滑块、文本框等。同时,Streamlit 还支持实时更新,当用户与应用程序交互时,界面会即时响应并更新展示结果。
2、创建ChatGLM交互界面流程
-
1、修改模型目录
将 basic_demo 文件夹中的 web_demo_streamlit.py 的模型加载路径改为 /gemini/pretrain
-
2、运行streamlit界面
在终端输入以下指令,运行web_demo_stream.py并指定7000端口,这样就不用再次添加外部端口映射啦~
streamlit run web_demo_streamlit.py --server.port 7000- 1
- 3、访问streamlit界面
复制外部访问地址到浏览器打开,之后模型才会开始加载。(不复制在浏览器打开是不会加载的!)

-
4、出现以上界面,等待加载,加载结束后工作台后端画面如下。可以在输入框提问。

三、用云端属于自己的stable-diffusion
step1、项目配置
-
采用 趋动云 云端配置,环境采用 趋动云小助手 的
AUTOMATIC1111/stable-diffusion-webui镜像,数据选择stable-diffusion-models数据集 -
资源配置采用拥有24G显存的 B1.large ,最好设置一个最长运行时间,以免忘关环境,导致资源浪费。
step2、环境配置
1、前置知识
-
tar命令是一个在 Unix 和类Unix操作系统中用来打包和解压文件的命令,其名称源自 “tape archive” 的缩写。-
创建归档文件(打包)
tar cf archive.tar file1 file2 ... # 创建名为 archive.tar 的归档文件,包含指定的文件 tar czf archive.tar.gz directory/ # 创建名为 archive.tar.gz 的归档文件,并使用 gzip 进行压缩- 1
- 2
-
c: 创建一个新的归档文件 -
f: 指定归档文件的名称 -
z: 使用 gzip 进行压缩 -
v: 显示详细的操作过程(可选) -
j: 使用 bzip2 进行压缩
-
提取归档文件(解压)
tar xf archive.tar # 从 archive.tar 中提取文件 tar xzf archive.tar.gz # 解压缩并从 archive.tar.gz 中提取文件- 1
- 2
-
x: 提取文件 -
f: 指定要提取的归档文件 -
z: 使用 gzip 进行解压 -
v: 显示详细的操作过程(可选) -
j: 使用 bzip2 进行解压
-
-
chmod是一个在 Unix 和类Unix操作系统中用来修改文件或目录权限的命令。其名称源自 “change mode” 的缩写。语法:
chmod [选项] 模式 文件或目录- 1
常用选项:
-R:递归地应用权限更改到指定的文件或目录,包括子目录中的所有文件和目录。-v:显示详细的操作过程。-c:仅在发生更改时显示详细的操作过程。
模式:
-
符号表示法:使用字符 u(所有者)、g(所属组)、o(其他用户)和 a(所有用户)来表示不同的用户类型;
-
加号(+)表示添加权限,减号(-)表示移除权限,等号(=)表示设定权限为指定值;
-
r(读取)、w(写入)、x(执行)分别表示读取、写入和执行权限。
-
python launch.py --deepdanbooru --share --xformers --listen是一个运行 Python 脚本的命令--deepdanbooru:这是一个选项标志,可能是脚本中用于启用 DeepDanbooru 模块的功能。它可能是指在运行脚本时开启 DeepDanbooru 相关的功能或配置。--share:这也是一个选项标志,可能表示在运行脚本时启用分享功能。具体功能和实现方式需要根据脚本的代码和上下文来确定。--xformers:这是一个选项标志,可能指示脚本在运行时使用 Xformers 模块。具体用途需要查看脚本的实现代码来确认。--listen:这是一个选项标志,可能指示脚本在运行时监听某个端口或地址,以便接收和处理传入的网络连接或数据。
2、环境配置流程
-
解压代码及模型
将 “stable-diffusion-webui.tar” 文件解压缩到 “/gemini/code/” 目录中。
tar xf /gemini/data-1/stable-diffusion-webui.tar -C /gemini/code/- 1
-
系统给frpc_linux_amd64_v0.2文件添加可执行权限。
chmod +x /root/miniconda3/lib/python3.10/site-packages/gradio/frpc_linux_amd64_v0.2- 1
-
将模型文件从
/gemini/data-1/v1-5-pruned-emaonly.safetensors拷贝到/gemini/code/stable-diffusion-webui/项目目录下。cp /gemini/data-1/v1-5-pruned-emaonly.safetensors /gemini/code/stable-diffusion-webui/- 1
-
更新系统httpx依赖
pip install httpx==0.24.1- 1
-
进入到运行文件目录下
cd /gemini/code/stable-diffusion-webui- 1
-
运行项目
运行Python 脚本,并且通过选项参数指定了脚本要启用的功能、模块或配置。
python launch.py --deepdanbooru --share --xformers --listen- 1
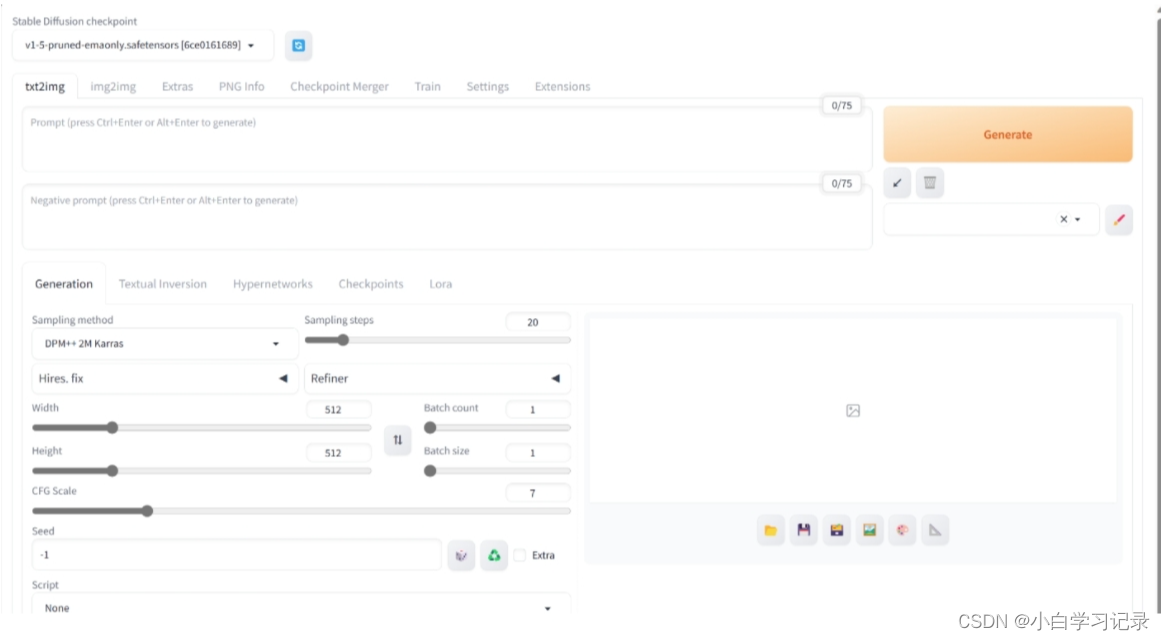
当命令窗口出现如下两个网址时表示部署成功,可以复制右侧的外部访问网址访问webui

访问这个网址就可以直接使用啦
-
相关阅读:
halcon NCC匹配算法
超强 | 保险单据在线OCR,秒速识别保单信息
C++ 4种智能指针的定义与使用——学习记录008
【无标题】
Chrome中devtools安装
SpringBoot中读取配置文件的几个注解
爬虫及词云总结
C语言中的多线程调用
node笔记记录36process之1
第三十六章 使用 CSP 进行基于标签的开发 - 使用尽可能少的#server和#call调用
- 原文地址:https://blog.csdn.net/feverfew1/article/details/136690312