-
树形结构 一篇文章梳理
树形结构是一种非常重要的非线性数据结构,它模拟了具有层次关系的数据模型。在树形结构中,
目录
数据元素(或称为节点)被组织成一系列的父子关系,形成了层次分明的结构。以下是关于树形结构的更多细节描述:
一、组成元素:
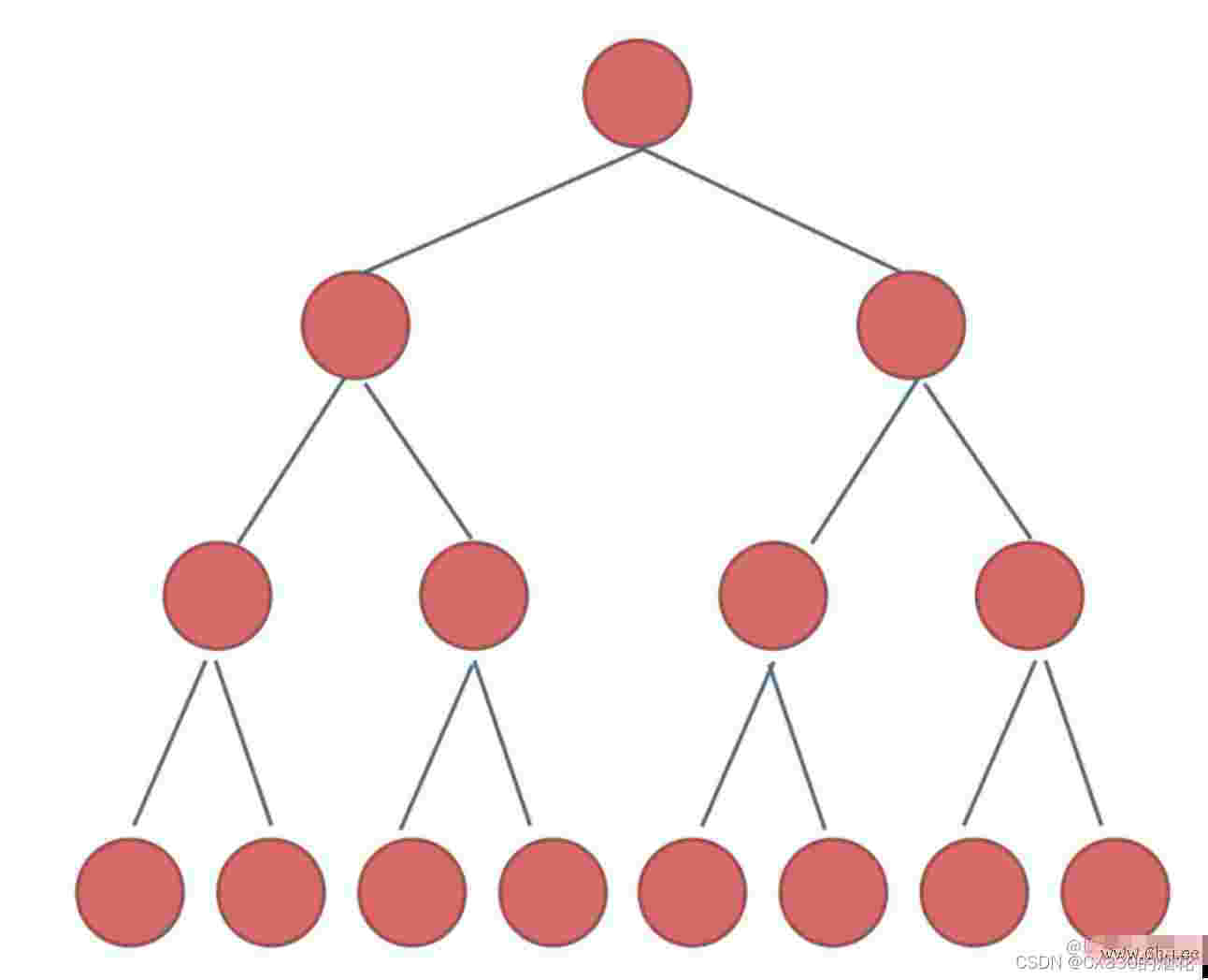
- 根节点
树形结构的起始点,没有父节点,但可能有多个子节点。
- 内部节点
除了根节点和叶节点之外的节点,通常既有父节点又有子节点。
- 叶节点
没有子节点的节点,通常位于树的底部。
- 边
连接父节点和子节点的线,表示它们之间的关系。
二、树的属性:
深度或高度
从根节点到最远叶节点的最长路径上的节点数。
度
一个节点的子节点数。对于特定类型的树(如二叉树),每个节点的度受到限制。
路径
从树的一个节点到另一个节点所经过的节点序列。
路径长度
路径上经过的边的数量。
三、树的类型
1 二叉树
每个节点最多有两个子节点,通常称为左子节点和右子节点。特殊的二叉树如平衡二叉树、AVL树、红黑树等,在保持平衡的同时提供了高效的搜索性能。
2 多叉树
每个节点可以有多个子节点,例如n叉树。
3 完全二叉树
除了最后一层外,其他层的节点数都达到最大值,并且最后一层的节点都靠左对齐。
4 满二叉树
每一层的节点数都达到最大值。
四、树形结构的应用
文件系统目录和文件以树形结构组织,方便用户浏览和管理。
- HTML文档:DOM(文档对象模型)是一个树形结构,表示HTML文档的结构。
- XML和JSON数据:这些数据结构经常以树形方式表示和组织数据。
- 数据库索引:B树和B+树等数据结构常用于数据库索引,以加速数据检索。
- 决策树:在机器学习和数据挖掘中,决策树用于分类和回归任务。
五、树形结构的操作:
1 遍历
按照某种规则访问树的每个节点,常见的遍历方式有前序遍历、中序遍历和后序遍历(针对二叉树)。
2 插入
在树的适当位置添加新节点。
3 删除
从树中移除指定的节点,可能需要重新平衡树。
4 搜索
在树中查找具有特定属性的节点。
五、代码事例
树形结构的基本操作通常包括创建树、插入节点、删除节点、遍历树等。这里我将给出一个简单的树形结构示例,并使用Python编程语言来实现一些基本操作。
首先,我们定义一个树节点类:
- class TreeNode:
- def __init__(self, value):
- self.value = value
- self.children = []
在这个类中,value 存储节点的值,children 是一个列表,存储该节点的子节点。
接下来,我们可以实现一些基本操作:
1 创建树
- def create_tree():
- root = TreeNode("root")
- child1 = TreeNode("child1")
- child2 = TreeNode("child2")
- root.children.append(child1)
- root.children.append(child2)
- return root
这个函数创建了一个简单的树,根节点为 "root",有两个子节点 "child1" 和 "child2"。
2 插入节点
- def insert_node(parent, value):
- new_node = TreeNode(value)
- parent.children.append(new_node)
- return new_node
这个函数在给定父节点下插入一个新的节点。
3 删除节点
- def delete_node(node, value):
- for child in node.children:
- if child.value == value:
- node.children.remove(child)
- return True
- return False
(这里我们实现一个简单版本,只删除没有子节点的节点)
这个函数在给定节点下删除一个值为 value 的子节点。如果找不到这样的节点,函数返回 False。
4 遍历树
(这里我们使用前序遍历作为示例)
- def preorder_traversal(node):
- if node is None:
- return
- print(node.value)
- for child in node.children:
- preorder_traversal(child)
这个函数以前序遍历的方式遍历树,并打印每个节点的值。
你可以使用这些函数来操作树形结构。例如:
- root = create_tree()
- insert_node(root, "child1.1")
- preorder_traversal(root) # 输出: root child1 child1.1 child2
- delete_node(root, "child1.1")
- preorder_traversal(root) # 输出: root child1 child2
5 查找节点
查找树中是否存在具有特定值的节点。
- def find_node(node, value):
- if node is None:
- return None
- if node.value == value:
- return node
- for child in node.children:
- result = find_node(child, value)
- if result is not None:
- return result
- return None
6 树的深度:
计算树的深度(即最长路径上的节点数)。
- def tree_depth(node):
- if node is None:
- return 0
- max_depth = 0
- for child in node.children:
- child_depth = tree_depth(child)
- max_depth = max(max_depth, child_depth)
- return max_depth + 1
7 树的宽度
计算树的最大宽度(即某一层上节点数的最大值)。这通常需要使用队列来进行层序遍历。
- from collections import deque
- def tree_width(root):
- if root is None:
- return 0
- queue = deque([root])
- max_width = 0
- current_level = 0
- while queue:
- level_size = len(queue)
- if level_size > max_width:
- max_width = level_size
- for _ in range(level_size):
- node = queue.popleft()
- for child in node.children:
- queue.append(child)
- current_level += 1
- return max_width
8 平衡树检查
检查一棵树是否是平衡树。平衡树是指任意节点的左右子树的高度差不超过1。
- def is_balanced(node):
- def height(node):
- if node is None:
- return 0
- left_height = height(node.children[0]) if node.children else 0
- right_height = height(node.children[1]) if len(node.children) > 1 else 0
- if left_height == -1 or right_height == -1 or abs(left_height - right_height) > 1:
- return -1
- return max(left_height, right_height) + 1
- return height(node) != -1
六、树的变种和扩展
- N叉树:每个节点可以有N个子节点。
- 森林:由多个不相交的树组成的集合。
- 二叉搜索树:二叉树的一种,其中每个节点的值都大于其左子树中任何节点的值且小于其右子树中任何节点的值。
七、总结
总的来说,树形结构是一个灵活且强大的工具,可以用于各种应用场景中数据的组织和处理。不同的树形结构类型和操作方式使得它们能够适应各种特定的需求,从而提供高效和可靠的数据管理方案。
-
相关阅读:
WebSocket
《中国棒球》:少年强棒·崛起之路
10.VScode下载---Windows64x
.Net之延迟队列
Taurus .Net Core 微服务开源框架:Admin 插件【2】 - 系统环境信息管理 - 【OS、Assembly】
重温C语言十二---指针
[极客大挑战 2019]LoveSQL
《Webpack 5 基础配置》- 禁止在出现编译错误或警告时,覆盖浏览器全屏显示
PMP认证在即将到来的招聘季节有用吗?
驱动DAY8
- 原文地址:https://blog.csdn.net/2303_79387663/article/details/136750156
