-
Hadoop学习1:概述、单体搭建、伪分布式搭建
概述
Hadoop: 分布式系统基础架构
解决问题: 海量数据存储、海量数据的分析计算
官网:https://hadoop.apache.org/
HDFS(Hadoop Distributed File System): 分布式文件系统,用于存储数据
Hadoop的默认配置【core-site.xml】: https://hadoop.apache.org/docs/r3.3.6/hadoop-project-dist/hadoop-common/core-default.xml == 配置Hadoop集群中各个组件间共享属性和通用参数以实现更好的性能和可靠性 == hadoop目录\share\hadoop\common\hadoop-common-3.3.6.jar
Hadoop的默认配置【hdfs-site.xml】: https://hadoop.apache.org/docs/r3.3.6/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml === 配置HDFS组件中各种参数以实现更好的性能和可靠性(如数据块大小、心跳间隔等)== hadoop目录\share\hadoop\hdfs\hadoop-hdfs-3.3.6.jar
Hadoop的默认配置【mapred-site.xml】: https://hadoop.apache.org/docs/r3.3.6/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml === 配置MapReduce任务执行过程进行参数调整、优化等操作 == hadoop目录\share\hadoop\mapreduce\hadoop-mapreduce-client-core-3.3.6.jar
Hadoop的默认配置【yarn-site.xml】: https://hadoop.apache.org/docs/r3.3.6/hadoop-yarn/hadoop-yarn-common/yarn-default.xml === 配置YARN资源管理器(ResourceManager)和节点管理器(NodeManager)的行为 == hadoop目录\share\hadoop\yarn\hadoop-yarn-common-3.3.6.jar基础知识
Hadoop组件构成

Hadoop配置文件
配置文件路径: hadoop目录/etc/hadoop

环境准备
配置
//修改主机名 //more /etc/sysconfig/network == 内容如下 //不同机器取不同的HOSTNAME,不要取成一样的 NETWORKING=yes HOSTNAME=hadoop107 //======================= //固定IP地址 == 自行百度 ifconfig more /etc/sysconfig/network-scripts/ifcfg-ens33 //======================= // 查看自定义主机名、ip的映射关系 == more /etc/hosts ping 主机名- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14


Hadoop配置
下载



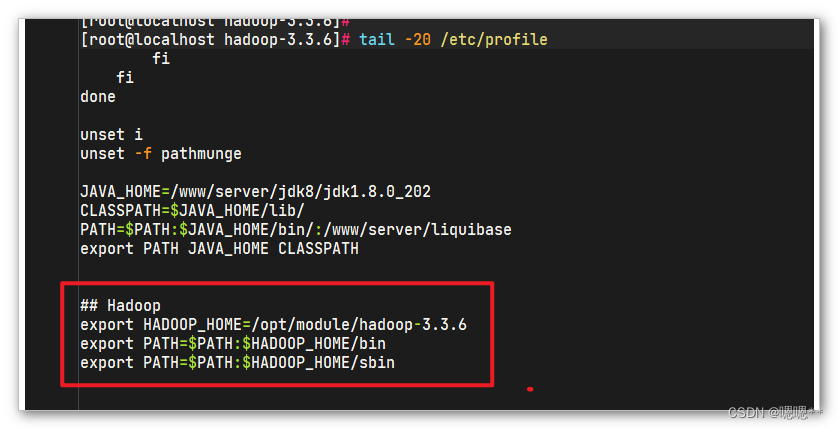
配置环境变量
//将压缩包解压到指定目录 mkdir -p /opt/module/ && tar -zxvf hadoop-3.3.6.tar.gz -C /opt/module/ //进入解压后的软件目录 cd /opt/module/hadoop-3.3.6 //设置环境变量 vim /etc/profile //此文件末尾添加下面四行内容 ## Hadoop export HADOOP_HOME=/opt/module/hadoop-3.3.6 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin //使环境变量生效 source /etc/profile- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20

Hadoop运行模式
Standalone Operation(本地)
官方Demo
官方Demo,统计文件中某个正则规则的单词出现次数
# hadoop目录 cd /opt/module/hadoop-3.3.6 # 创建数据源文件 == 用于下面进行demo统计单词 mkdir input # 复制一些普通的文件 cp etc/hadoop/*.xml input # 统计input里面的源文件规则是'dfs[a-z.]+'的单词个数,并将结果输出到当前目录下的output目录下 == 输出目录不得提前创建,运行时提示会报错 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar grep input output 'dfs[a-z.]+' # 查看统计结果 cat output/* cat output/part-r-00000 # 显示出来的结果,跟grep查出来的一样- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

WordCount单词统计Demo
//创建数据目录 mkdir -p /opt/module/hadoop-3.3.6/input/wordCountData && cd /opt/module/hadoop-3.3.6/input/ //文件数据创建 = 用于demo测试 echo "cat apple banana" >> wordCountData/data1.txt echo "dog" >> wordCountData/data1.txt echo " elephant" >> wordCountData/data1.txt echo "cat apple banana" >> wordCountData/data2.txt echo "dog" >> wordCountData/data2.txt echo " elephant queen" >> wordCountData/data2.txt //查看数据内容 more wordCountData/data1.txt more wordCountData/data2.txt //开始统计wordCountData文件目录下的单词数 hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /opt/module/hadoop-3.3.6/input/wordCountData wordCountDataoutput //查看统计结果 cd /opt/module/hadoop-3.3.6/input/wordCountDataoutput cat ./*- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26



Pseudo-Distributed Operation(伪分布式模式)
参考: https://hadoop.apache.org/docs/r3.3.6/hadoop-project-dist/hadoop-common/SingleCluster.html#Pseudo-Distributed_Operation
概述: 单节点的分布式系统(用于测试使用)配置修改
核心配置文件修改: vim /opt/module/hadoop-3.3.6/etc/hadoop/core-site.xml<configuration> <property> <name>fs.defaultFSname> <value>hdfs://192.168.19.107:9000value> property> <property> <name>hadoop.tmp.dirname> <value>/opt/module/hadoop-3.3.6/tmpvalue> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
核心配置文件修改: vim /opt/module/hadoop-3.3.6/etc/hadoop/hdfs-site.xml<configuration> <property> <name>dfs.replicationname> <value>1value> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
启动DFS【9870】
Hadoop-DFS数据清空格式化
hdfs namenode -format- 1

启动DFS组件
注意: 启动过程中可能遇到非root用户、JAVA_HOME找不到的现象,导致启动失败,自行参考下面的问题解决
# 未启动hadoop时所系统所运行java程序 jps # 启动hadoop相关的应用程序 sh /opt/module/hadoop-3.3.6/sbin/start-dfs.sh # 查看启动hadoop的应用变化 jps- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

访问DFS前端页面(不同版本的Hadoop的NameNode端口有变)
浏览器NameNode前端页面: http://192.168.19.107:9870/


dfs命令使用(主要用来操作文件)
帮助文档: hdfs dfs --help

复制物理机文件中hadoop中
hdfs dfs -mkdir /test hdfs dfs -put /opt/module/hadoop-3.3.6/input /test- 1
- 2
- 3
- 4


文件展示以及读取文件内容
hdfs dfs -ls -R / hdfs dfs -cat /test/input/core-site.xml- 1
- 2
- 3

创建目录、文件
hdfs dfs -mkdir -p /test/linrc hdfs dfs -touch /test/linrc/1.txt- 1
- 2
- 3
- 4

使用mapreduce进行计算hadoop里面某个文件夹的内容
hdfs dfs -ls /test/input # 对hadoop里面某个文件夹内容进行单词统计 hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /test/input/wordCountData /test/input/wordCountDataoutput2 hdfs dfs -ls /test/input # 查看统计结果 hdfs dfs -cat /test/input/wordCountDataoutput2/*- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

启动Yarn组件【8088】
配置修改
强制指定Yarn的环境变量: /opt/module/hadoop-3.3.6/etc/hadoop/yarn-env.sh

export JAVA_HOME=/www/server/jdk8/jdk1.8.0_202- 1
yarn-site.xml添加如下两个配置 /opt/module/hadoop-3.3.6/etc/hadoop/yarn-site.sh
<configuration> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.resourcemanager.hostnamename> <value>192.168.19.107value> property> <property> <name>yarn.nodemanager.env-whitelistname> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HO MEvalue> property> <property> <name>yarn.timeline-service.hostnamename> <value>192.168.19.107value> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29

启动
//非常重要,必须回到hadoop的目录里面进行启动,我也不知道为什么 cd /opt/module/hadoop-3.3.6 //不要使用 sh命令启动,否则报错,我也不知道为什么 ./sbin/start-yarn.sh- 1
- 2
- 3
- 4
- 5

访问yarn前端页面
浏览器: http://ip:8088
yarn页面端口配置: https://hadoop.apache.org/docs/r3.3.6/hadoop-yarn/hadoop-yarn-common/yarn-default.xml的【yarn.resourcemanager.webapp.address】

运行计算dfs某个目录所有文件的单词数,yarn页面有运行记录


//单词计算开始 hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /test/input/wordCountData /test/input/wordCountDataoutput3- 1
- 2


启动MapReduce组件
配置修改
强制指定mapred的环境变量: /opt/module/hadoop-3.3.6/etc/hadoop/mapred-env.sh

export JAVA_HOME=/www/server/jdk8/jdk1.8.0_202- 1
mapred-site.xml添加如下配置: /opt/module/hadoop-3.3.6/etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.namename> <value>yarnvalue> property> <property> <name>mapreduce.application.classpathname> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*value> property> <property> <name>mapreduce.jobhistory.addressname> <value>192.168.19.107:10020value> property> <property> <name>mapreduce.jobhistory.webapp.addressname> <value>192.168.19.107:19888value> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
启动日志采集系统

mapred --daemon start historyserver- 1
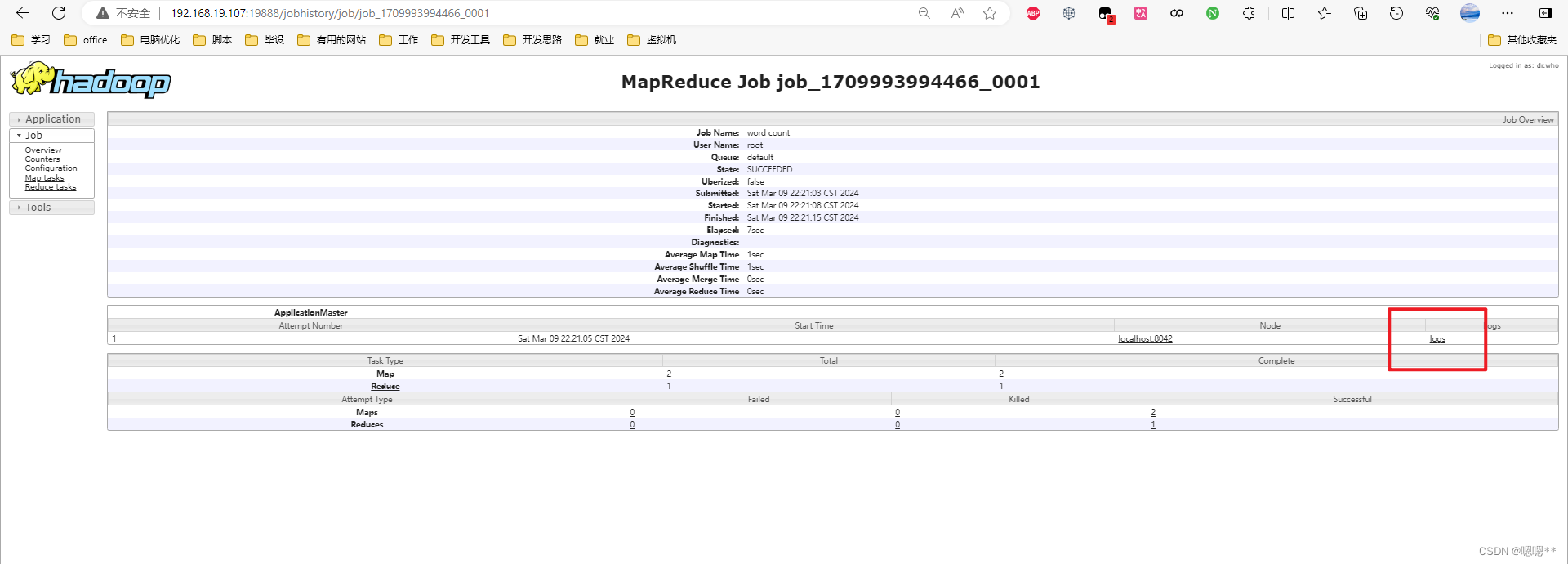
查看任务日志


启动日志聚集(任务执行的具体详情上传到HDFS组件中)
未启动前


启动
注意: 如果yarn组件已经启动,修改yarn的配置需要重新启动,使得配置生效
#停止日志系统 mapred --daemon stop historyserver #停止yarn组件 cd /opt/module/hadoop-3.3.6 ./sbin/stop-yarn.sh- 1
- 2
- 3
- 4
- 5
- 6
- 7

yarn-site.xml添加如下配置 /opt/module/hadoop-3.3.6/etc/hadoop/yarn-site.sh

<configuration> <property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.resourcemanager.hostnamename> <value>192.168.19.107value> property> <property> <name>yarn.nodemanager.env-whitelistname> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HO MEvalue> property> <property> <name>yarn.timeline-service.hostnamename> <value>192.168.19.107value> property> <property> <name>yarn.log-aggregation-enablename> <value>truevalue> property> <property> <name>yarn.log-aggregation.retain-secondsname> <value>2592000value> property> configuration>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
#启动yarn组件 cd /opt/module/hadoop-3.3.6 ./sbin/start-yarn.sh #启动日志系统 mapred --daemon start historyserver- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

# 重新运行一个任务 hadoop jar /opt/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /test/input/wordCountData /test/input/wordCountDataoutput5- 1
- 2



-
相关阅读:
酷早报:6月23日Web3加密行业每日新闻汇总
逍遥自在学C语言 | 指针的基础用法
Spark Join类型和适用的场景
卡奥斯第二届1024程序员节正式启动!
vue3 组件与API直接使用,怎样无需import?
27.CF1004F Sonya and Bitwise OR 区间合并线段树
Elixir-Tuples
【书籍篇】Git 学习指南(二)提交与多次提交
Dropdown 下拉菜单实现标签页的相关操作
龙口联合化学通过注册:年营收5.5亿 李秀梅控制92.5%股权
- 原文地址:https://blog.csdn.net/weixin_39651356/article/details/136639113
