-
Keepalived+LVS构建高可用集群
一、Keepalive基础介绍:
1. Keepalive与VRRP:
Keepalive 是一种用于监视系统或服务是否处于活动状态的机制。在网络环境中,它通常指定一个周期性的信号或数据包,用于检测设备、服务或连接是否仍然处于活动状态。如果设备或服务停止响应,相应的监视器将触发警报或采取预定义的操作。
VRRP 是一种用于提供冗余路由器功能的协议,通过允许多个路由器共享同一个虚拟 IP 地址来提供冗余。这样,即使其中一个路由器失效,网络流量仍然可以被另一个路由器接管,从而保证了网络的连通性和可用性。
这两种技术通常结合使用,因为 Keepalive 可以用于监视 VRRP 路由器的活动状态。如果 VRRP 主要路由器失效,备份路由器可以通过接收不再有主要路由器发送的 keepalive 信号来检测到这一事件,并迅速接管虚拟 IP 地址,从而确保网络的连通性。
2. VRRP相关技术:
通告:心跳,优先级等;周期性
工作方式:抢占式,非抢占式,延迟抢占模式
安全认证:如没有安全认证,不在集群中的keeplive服务器设置超高的优先级,会造成事故
工作模式:
- 主/备:单虚拟路径器
- 主/主:主/备(虚拟路由器1),备/主(虚拟路由器2)
3. 工作原理 :
Keepalived是以VRRP协议为实现基础的,VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议,保证集群高可用的一个服务软件,用来防止单点故障。将N台提供相同功能的服务器组成一个服务器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(该服务器所在局域网内其他机器的默认路由为该vip),master会发组播,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。
IPV4总共三种通信方式:单播,组播,广播。组播是指以224.0.0.0地址作为通信地址的一种方式。
4. 模块:
分别是core、check和vrrp。
- core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。
- check负责健康检查,包括常见的各种检查方式。
- vrrp模块是来实现VRRP协议的。
5. 架构:
用户空间核心组件:
① vrrp stack:VIP消息通告,用来管理虚拟ip
② checkers:监测real server(简单来说 就是监控后端真实服务器的服务)是否存活
③ system call:实现 vrrp 协议状态转换时调用脚本的功能
④ SMTP:邮件组件(报警邮件)
⑤ IPVS wrapper:生成IPVS规则(直接生成ipvsadm)
⑥ Netlink Reflector:网络接口(将虚拟地址ip(vip)地址飘动)
⑦ WatchDog:监控进程(整个架构是否有问题)
⑧ 控制组件:提供keepalived.conf 的解析器,完成Keepalived配置
⑨ IO复用器:针对网络目的而优化的自己的线程抽象
⑩ 内存管理组件:为某些通用的内存管理功能(例如分配,重新分配,发布等)提供访问权限
keeplive可以配合ngnix等软件,反向代理

6. 安装:
① yum安装:
yum install keepalived -y
② 官网下载安装包,编译安装:Keepalived for Linux
7. Keepalived 相关文件::
软件包名:keepalived
主程序文件:/usr/sbin/keepalived
主配置文件:/etc/keepalived/keepalived.conf
配置文件示例:/usr/share/doc/keepalived/
Unit File单元文件:/lib/systemd/system/keepalived.service
Unit File的环境配置文件:/etc/sysconfig/keepalived CentOS7.1 配置组成:
/etc/keepalived/keepalived.conf 配置组成:
① 全局配置:这部分包括全局参数的定义,例如进程 ID 文件、日志文件路径、通知邮箱地址等。全局配置通常用于指定整体行为和设置。
② 模块配置:Keepalived 配置文件中会包含关于 VRRP 或者 LVS 模块的配置。对于 VRRP 模块,需要定义虚拟路由器的标识符、优先级、虚拟 IP 地址以及监视其他路由器可用性所需的健康检查。对于 LVS 模块,需要定义负载均衡器的设置,包括虚拟服务器、后端服务器池、负载均衡算法等。
③ VRRP 实例配置:在 VRRP 模式下,配置文件中会包含一个或多个 VRRP 实例的配置。每个实例都会定义一个独立的虚拟路由器,包括其标识符、优先级、虚拟 IP 地址、健康检查设置等。
④ LVS 实例配置:在 Load Balancer 模式下,配置文件中会包含一个或多个 LVS 实例的配置。每个实例会定义一个独立的负载均衡服务,包括虚拟服务器、后端服务器池、负载均衡算法等设置。
⑤ 状态转换脚本:Keepalived 允许用户定义状态转换时执行的自定义脚本,这些脚本可以在主备切换时执行特定的操作,如通知管理员、启动或停止相关服务等。
7.2 全局配置:
全局配置参数定义了邮件通知设置、路由器标识符以及 VRRP 的一些行为特性,确保在需要时可以进行状态通知,并控制 VRRP 协议的一些细节行为。
- global_defs {
- notification_email { #定义了接收通知邮件的邮箱地址列表
- acassen@firewall.loc
- failover@firewall.loc
- sysadmin@firewall.loc
- }
- notification_email_from Alexandre.Cassen@firewall.loc 指定了发送通知邮件的邮箱地址
- smtp_server 192.168.200.1 #设置 SMTP 服务器的地址为 192.168.200.1
- smtp_connect_timeout 30 #SMTP 连接超时时间为 30 秒
- router_id LVS_DEVEL #指定了路由器的标识符为 LVS_DEVEL
- vrrp_skip_check_adv_addr #表示在 VRRP 状态转换时跳过对广播地址的检查
- vrrp_strict #启用严格模式,要求 VRRP 实例只能在其配置的网络接口上工作
- vrrp_garp_interval 0 #设置 Gratuitous ARP(GARP)消息发送的间隔时间为 0,即禁用 GARP
- vrrp_gna_interval 0 #设置 Gratuitous Neighbor Advertisement(GNA)消息发送的间隔时间为 0,即禁用 GNA
- #GARP 是指发送者在不请求的情况下主动发送 ARP 响应消息
- #GNA 是 IPv6 网络中的类似协议,它也是主动发送者在不请求的情况下向网络上的其他设备发送邻居通告消息。类似于 GARP
- vrrp_mcast_group4 224.0.0.18
- #指定组播IP地址范围:224.0.0.0到239.255.255.255,默认值:224.0.0.18;建议使用特有的组播地址或者改为单播
- vrrp_iptables
- #此项和vrrp_strict同时开启时,则不会添加防火墙规则,如果无配置vrrp_strict项,则无需启用此项配置
- }
7.3 VRRP实例配置(lvs调度器):
共同定义了一个 VRRP 实例的属性、身份验证设置以及与其关联的虚拟 IP 地址,使得 Keepalived 能够管理虚拟路由器的状态,并确保在故障时能够进行适当的状态转换。
- vrrp_instance VI_1 { #定义了一个名为 VI_1 的 VRRP 实例,用于创建一个虚拟路由器实体(lvs虚拟调度器)
- state MASTER #指定该实例的初始状态为 MASTER,即主服务器状态。在 VRRP 中,可以将路由器配置为主服务器或备份服务器。
- interface eth0 #指定了 VRRP 实例所使用的网络接口,这里是 eth0
- virtual_router_id 51 #为 VRRP 实例指定了一个唯一的虚拟路由器 ID。该 ID 在同一广播域内必须是唯一的,范围:0-255
- priority 100 #设置了该实例的优先级为 100。在 VRRP 中,具有最高优先级的路由器将被选举为主服务器
- advert_int 1 #指定了 VRRP 报文的发送间隔为 1 秒。这决定了 VRRP 路由器之间交换状态信息的频率
- authentication { #这个部分定义了 VRRP 实例的身份验证设置(认证机制)
- auth_type PASS #指定了使用密码进行身份验证
- auth_pass 1111 #设置了用于身份验证的密码为 1111
- auth_type AH|PASS #AH为IPSEC认证(不推荐),PASS为简单密码(建议使用)
- auth_pass
#预共享密钥,仅前8位有效,同一个虚拟路由器的多个keepalived节点必须一样 - }
- virtual_ipaddress { #列出了该 VRRP 实例关联的虚拟 IP 地址列表。这些 IP 地址将会在主服务器和备份服务器之间切换,确保始终有一台服务器能够接收流量并处理数据包。生产环境可能指定上百个IP地址
- 192.168.200.16 #指定VIP,不指定网卡,默认为eth0,注意:不指定/prefix,默认为/32
- 192.168.200.17/24 dev eth1 #指定了一个带子网掩码的虚拟 IP 地址,并且明确地指定了它要绑定到的网络接口(eth1)
- 192.168.200.18/24 dev eth2 label eth2:1 #指定VIP的网卡label,即将这个虚拟ip绑在eth2的虚拟网卡上
- }
- }
- track_interface { #配置监控网络接口,一旦出现故障,则转为FAULT(失败)状态实现地址转移
- eth0
- eth1
- …
- }
注意:当生产环境中虚拟IP过多,可以在 virtual_ipaddress{ }前加入子配置文件声明,如:include /etc/keepalived/conf.d/*.conf,删除或注释主配置文件virtual_ipaddress{ }虚拟IP部分,最后每个项目生成一个子文件夹。
7.4 虚拟服务器与真实服务器配置 :
定义虚拟服务器的行为,包括负载均衡算法、持久化会话设置以及用于检查真实服务器健康状态的参数。同时,您还可以为每个真实服务器定义权重和健康检查的详细规则,以确保负载均衡系统能够有效地分发流量并监控后端服务器的状态。
- virtual_server 192.168.200.100 443 { #定义了一个虚拟服务器,监听 IP 地址为 192.168.200.100,端口为 443
- delay_loop 6 #设置检测真实服务器状态的时间间隔为 6 秒
- lb_algo rr #指定了负载均衡算法为 Round Robin(轮询)方式
- lb_kind NAT #指定了负载均衡的类型为 NAT。NAT 模式将客户端的请求通过 NAT 转换后发送到后端服务器
- persistence_timeout 50 #设置了持久化会话的超时时间为 50 秒
- protocol TCP #指定了虚拟服务器所使用的协议为 TCP
- real_server 192.168.201.100 443 { #定义了一个真实服务器,其 IP 地址为 192.168.201.100,端口为 443
- weight 1 #设置了该真实服务器的权重为 1,用于负载均衡算法
- SSL_GET { #这一部分定义了用于检查真实服务器健康状态的 SSL GET 请求的参数
- url { #指定了要进行健康检查的 URL 路径,并提供了对应的摘要信息
- path /
- digest ff20ad2481f97b1754ef3e12ecd3a9cc
- }
- url {
- path /mrtg/
- digest 9b3a0c85a887a256d6939da88aabd8cd
- }
- TCP_CHECK {
- connect_port 443 #检查目标端口
- connect_timeout 3 #设置了连接超时时间为 3 秒
- nb_get_retry 3 #指定了在失败时尝试重新连接的次数为 3 次
- delay_before_retry 3 #设置了重试前的延迟时间为 3 秒
- }
- }
- }
- real_server 192.168.91.105 80 { #定义第二台真实服务器
- weight 1
- TCP_CHECK {
- connect_port 80
- connect_timeout 3
- nb_get_retry 3
- delay_before_retry 3
- }
- }
- }
二、Keepalived结合LVS负载均衡:
Keepalived结合LVS构建的负载均衡系统不仅可以提高系统的可靠性和性能,还能简化管理并降低成本,是企业构建稳定、高效的网络架构的重要组成部分。

实验:7-1为主; 7-2为备; 7-3和7-4为后端服务器
1.关闭防火墙和selinux:
- [root@localhost ~]# systemctl stop firewalld
- [root@localhost ~]# setenforce 0
2.配置主设备7-1:
1.安装ipvsadm和keepalived:
[root@localhost ~]# yum install ipvsadm.x86_64 keepalived.x86_64 -y
2.修改keepalived的配置:
做备份
- [root@localhost ~]# cd /etc/keepalived
- [root@localhost keepalived]# ls
- keepalived.conf
- [root@localhost keepalived]# cp keepalived.conf keepalived.conf.bak
- [root@localhost keepalived]# ls
- keepalived.conf keepalived.conf.bak
- [root@localhost keepalived]#

更改配置文件:
[root@localhost keepalived]# vim keepalived.conf




3.开启ipvsadm:
- [root@localhost keepalived]# systemctl restart keepalived.service
- [root@localhost keepalived]# systemctl restart ipvsadm.service
- [root@localhost keepalived]# ipvsadm -ln
查看:

3.配置7-3Web服务器:
1.安装httpd并开启:
- [root@localhost ~]# yum install httpd -y
- [root@localhost ~]# systemctl start httpd
- [root@localhost ~]# cd /var/www/html
- [root@localhost html]# echo 7-3 > index.html
- [root@localhost html]# systemctl restart httpd
4.配置7-4Web服务器:
1.安装httpd并开启
- [root@localhost ~]# yum install httpd -y
- [root@localhost ~]# systemctl start httpd
- [root@localhost ~]# cd /var/www/html
- [root@localhost html]# echo 7-4 > index.html
- [root@localhost html]# systemctl restart httpd
5.给7-3和7-4做虚拟网卡:
- [root@localhost html]# ifconfig lo:0 192.168.91.30/32
- [root@localhost html]#
- [root@localhost html]#
- [root@localhost html]# ip a
7-3:

7-4:

给7-3和7-4添加ARP规则:
- vim /etc/sysctl.conf
- net.ipv4.conf.all.arp_ignore = 1
- net.ipv4.conf.all.arp_announce = 2
- net.ipv4.conf.default.arp_ignore = 1
- net.ipv4.conf.default.arp_announce = 2
- net.ipv4.conf.lo.arp_ignore = 1
- net.ipv4.conf.lo.arp_announce = 2


生效一下并重启服务:
- [root@localhost html]# sysctl -p
- [root@localhost html]# systemctl restart httpd
- [root@localhost html]#
6.用7-1传内容给7-2:
[root@localhost keepalived]# scp keepalived.conf 192.168.91.4:/data
7.配置7-2的keepalived:
1.安装keepalived和ipvsadm:
[root@localhost ~]# yum install ipvsadm.x86_64 keepalived.x86_64 -y2.复制文件:
- [root@localhost ~]# cd /etc/keepalived/
- [root@localhost keepalived]# ls
- keepalived.conf
- [root@localhost keepalived]# cp keepalived.conf keepalived.conf.bak
- [root@localhost keepalived]#
- [root@localhost keepalived]# mv /data/keepalived.conf .
3.改配置文件:
- 12 router_id LVS_02
- 20 state BACKUP
- 23 priority 80

- [root@localhost keepalived]# systemctl start keepalived.service
- [root@localhost keepalived]# ipvsadm-save > /etc/sysconfig/ipvsadm
- [root@localhost keepalived]#
- [root@localhost keepalived]# systemctl start ipvsadm
- [root@localhost keepalived]#
- [root@localhost keepalived]# ipvsadm -ln
查看:

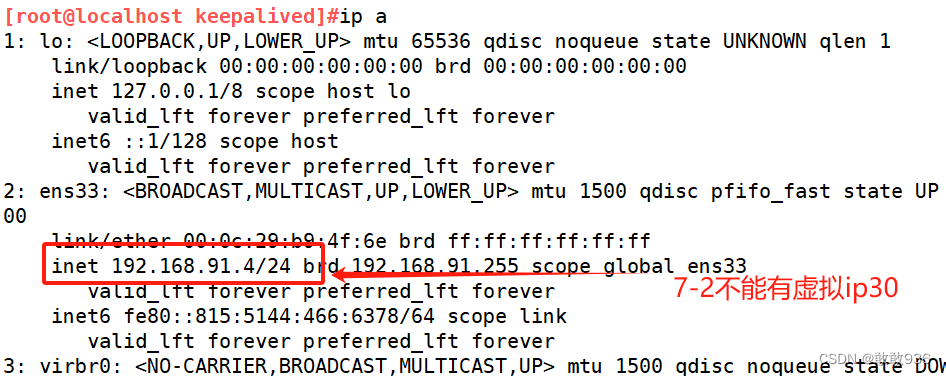
8.把7-3和7-4的长连接关掉:
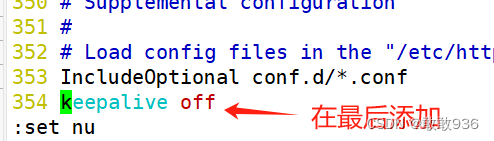
- [root@localhost html]# vim /etc/httpd/conf/httpd.conf
- 354 keepalive off
- [root@localhost html]# systemctl restart httpd
因为apache默认开启所以7-3和7-4都关掉:
9.去浏览器访问虚拟IP:


三.其他配置 :
1.抢占模式:
1.1.当主设备7-1keepalived开启时

虚拟IP192.168.91.30在主设置7-1上

1.2.当从设备7-1keepalived关闭时:

虚拟IP到了从设备7-2上

2.非抢占模式:
1.修改7-1的keepalived:
- vim keepalived.conf
- 20 state BACKUP
- 21 nopreempt

跑去7-2了

3.延迟抢占模式:
1.修改7-1配置:

2.修改7-2配置:

3.去7-1看结果:

4.去7-2看结果:

5.去7-1看延迟抢占的结果:

三、多播修改 :
1.去7-2上抓包:
[root@localhost keepalived]# tcpdump -i ens33 -nn src host 192.168.91.3默认单播地址,来自于224.0.0.18

2.修改7-1的配置文件:
- vim keepalived.conf
- 14 vrrp_mcast_group4 234.6.6.6

3.修改7-2的配置文件:

4.去7-2上抓包看结果:
[root@localhost keepalived]# tcpdump -i ens33 -nn src host 192.168.91.3

四、单播修改:
1.修改7-1配置:
- vim keepalived.conf
- 31 unicast_src_ip 192.168.91.3
- 32 unicast_peer {
- 33 192.168.91.4
- 34 }
2.修改7-2配置:
- vim keepalived.conf
- 33 unicast_src 192.168.91.4
- 34 unicast_peer {
- 35 192.168.91.3
- 36 }

3.去7-2上抓包:
tcpdump -i ens33 -nn src host 192.168.91.3 and dst host 192.168.91.4
五、通知脚本:
1.修改7-1配置:
- [root@localhost keepalived]# cd /opt
- [root@localhost opt]# ls
- rh
- [root@localhost opt]# vim keepalived.sh
- [root@localhost opt]#
- [root@localhost opt]# mv keepalived.sh keepalive.sh
- [root@localhost opt]#
- [root@localhost opt]# chmod +x keepalive.sh
- [root@localhost opt]#
- [root@localhost opt]# vim /etc/keepalived/keepalived.conf
- vim keepalive.sh
- #!/bin/bash
- #
- contact='2084927936@qq.com'
- notify() {
- mailsubject="$(hostname) to be $1, vip floating"
- mailbody="$(date +'%F %T'): vrrp transition, $(hostname) changed to be $1"
- echo "$mailbody" | mail -s "$mailsubject" $contact
- }
- case $1 in
- master)
- notify master
- ;;
- backup)
- notify backup
- ;;
- fault)
- notify fault
- ;;
- *)
- echo "Usage: $(basename $0) {master|backup|fault}"
- exit 1
- ;;
- esac
- 31 notify_master "/opt/keepalive.sh master"
- 32 notify_backup "/opt/keepalive.sh backup"
- 33 notify_fault "/opt/keepalive.sh fault"

- systemctl restart keepalived.service
- ###重启
- [root@localhost ~]# killall keepalived
2.最后可以去QQ邮箱的垃圾箱查看:

六、日志功能:
1.去7-1上去修改:
- [root@localhost ~]# vim /etc/sysconfig/keepalived
- KEEPALIVED_OPTIONS="-D -S 6"

- vim /etc/rsyslog.conf
- 74 local6.* /data/keepalive.log
- #自定义位置

- [root@localhost opt]# vim /etc/rsyslog.conf
- local6.* /data/keepalived.log
- [root@localhost opt]# systemctl restart rsyslog.service
- [root@localhost opt]# systemctl restart keepalived.service
- [root@localhost opt]# ls /data
- keepalived.log
- #查看生成日志文件
四.高可用群集的脑裂现象和预防措施:
4.1 现象和原因:
现象:
在"双机热备"高可用(HA)系统中,当联系两个节点的"心跳线"断开时(即两个节点断开联系时),本来为一个整体、动作协调的HA系统,就分裂成为两个独立的节点(即两个独立的个体)。由于相互失去了联系,都以为是对方出了故障,此时备用调度器会运转起来争做主调度器的工作,而主调度器依然保持着调度工作,两个调度的同时运转导致整个系统的紊乱。就会发生严重后果:(1)共享资源被瓜分、两边"服务"都起不来了.(2)或者两边"服务"都起来了,但同时读写"共享存储",导致数据损坏(常见如数据库轮询着的联机日志出错)。
原因:
硬件原因:
1. 高可用服务器各节点之间心跳线链路发生故障,导致无法正常通信。
2. 因心跳线坏了(包括断了,老化)。
3. 因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)。
4. 因心跳线间连接的设备故障(网卡及交换机)。
5. 因仲裁的机器出问题(采用仲裁的方案)。运用配置原因:
6. 高可用服务器上开启了 iptables 防火墙阻挡了心跳消息传输。
7. 高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败。
8. 其他服务配置不当等原因,如心跳方式不同,心跳广插冲突、软件Bug等9. Keepalived 配置里同一VRRP实例如果 virtual_router_id 两端参数配置不一致也会导致裂脑问题发生。
4.2 脑裂预防
针对脑裂现象的产生,运维人员第一时间要做的不是处理发生故障的调度器或则故障线路,而是首先确保业务不会因此中断,进行脑裂的预防尤为重要。出现问题,先保证业务的进行,再进行排障。
方式一:添加冗余的心跳线
添加冗余的心跳线支持HA多线路的进行,在多线路的加持下,一条线路故障后,也会有其余的线路也可传输心跳信息,让主备调度器继续保持正常运转。此方案可减少脑裂产生的概率。
方式二:脚本配合周期任务计划检测,调度器自我裁决
脑裂分析:产生脑裂的最主要最常见的原因是备调度器接收不到主调度器的的心跳信息。首先调度器大多数情况下都会是在统一局域网中,是通过网络来进行心跳信息的传送。所以心跳信息的检测可以基于icmp协议来进行检测脚本思路:
如下图:若产生脑裂时我们需要探究的是通过脚本预测是1号线路的问题还是2号线路的问题 。所以本次脚本的编写只要能判断出哪条线路产生问题后,进行相应的裁决就可以在脑裂产生的第一时间免除其带来的影响
(1) 主调度器本身使用ping命令进行周期计划ping备用调度器,保证时刻畅通。
(2)采用条件判断语句,若主调调度器ping不通备调度器时,主调度器启用ssh服务远程借用节点服务器对备用调度器进行ping命令(可以多设置几台节点服务器ping,确保准确性)。若节点服务能ping通则说明问题出现在1号线路,主调度器进行自我裁决,让备调度器进行主调调度器的工作。若节点服务器也ping不通备调度器,说明问题出在了2号线路。
(3)可以在备调度器中也添加一个该方式的脚本,时刻ping主调度器。保证2号线出现问题时进行自我裁决。
(4)将主备调度器的脚本均添加周期计划任务中(crontab -e),进行合理的时间段检测。
方式三:第三方工具,监控软件 :
利用主流的监控软件,例如 zabbix。当两个节点出现分歧时,由第3方的仲裁者决定听谁的。这个仲裁者,可能是一个锁服务,一个共享盘或者其它什么东西。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端。不仅"心跳"、还兼对外"服务"的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。方式四:启用磁盘锁 :
正在服务一方锁住共享磁盘,"裂脑"发生时,让对方完全"抢不走"共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动"解锁",另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了"智能"锁。即:正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
五. 实现其它应用的高可用性 VRRP Script
keepalived 利用 VRRP Script 技术,可以调用外部的辅助脚本进行资源监控,并根据监控的结果实现优先动态调整,从而实现其它应用的高可用性功能。
1.把7-1和7-2的ipvsadm关掉:
[root@localhost ~]# systemctl stop ipvsadm.service2.安装并开启7-1和7-2的Nginx:
- yum install epel-release -y
- yum install nginx -y
- systemctl start nginx
3.去7-1的Nginx主配置文件中做反向代理:
- [root@localhost ~]# vim /etc/nginx/nginx.conf
- upstream web {
- server 192.168.91.5;
- server 192.168.91.7;
- }
- location / {
- proxy_pass http://web;
- }
4.curl看一下:
- [root@localhost ~]# curl 192.168.91.5
- 7-3
- [root@localhost ~]# curl 192.168.91.7
- 7-4
5.7-1直接复制给7-2:
- [root@localhost ~]# scp /etc/nginx/nginx.conf 192.168.91.4:/etc/nginx/nginx.conf
- root@192.168.91.4's password:
- nginx.conf 100% 2448 200.2KB/s 00:00
- [root@localhost ~]#
6.去7-2curl看一下:
- [root@localhost keepalived]# systemctl restart nginx
- [root@localhost keepalived]# curl 192.168.91.4
- 7-3
- [root@localhost keepalived]# curl 192.168.91.4
- 7-4
7.去7-1修改keepalive:
- [root@localhost ~]# vim /etc/keepalived/keepalived.conf
- 18 vrrp_script check_down {
- 19 script "/etc/keepalived/ng.sh"
- 20 interval 1
- 21 weight -30
- 22 fall 1
- 23 rise 2
- 24 timeout 2
- 25 }
- 40 track_script {
- 41 check_down
- 42 }
模拟故障,关闭代理服务器1nginx服务,访问页面需要多次刷新,同时观察VIP在哪台机器
-
相关阅读:
电视盒子/投影仪是怎么看电视的?安利两款软件教程教会你
Android Radio实战——打开Tuner(十八)
word 页眉 页脚 页码 分页符 目录
EDA(Exploratory Data Analysis)探索性数据分析
Java替换RequestBody和RequestParam参数的属性
【zlm】SRT概念
MySQL慢查询日志
用Speedtest-Tracker跟踪上网速度
时序数据库介绍及应用场景,C#实例
YAGEO(国巨)旧电脑风扇制作风力发电机步骤详解 - 电动机控制电路图
- 原文地址:https://blog.csdn.net/m0_75067030/article/details/136710515
