-
【Redis】 缓存双写一致性
缓存双写一致性
给缓存设置过期时间,定期清理缓存并回写,是保证最终一致性的解决方案。
我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存,达到一致性,切记,要以mysql的数据库写入库为准。
上述方案和后续落地案例是调研后的主流+成熟的做法,但是考虑到各个公司业务系统的差距,
不是100%绝对正确,不保证绝对适配全部情况,请同学们自行酌情选择打法,合适自己的最好。
双检加锁

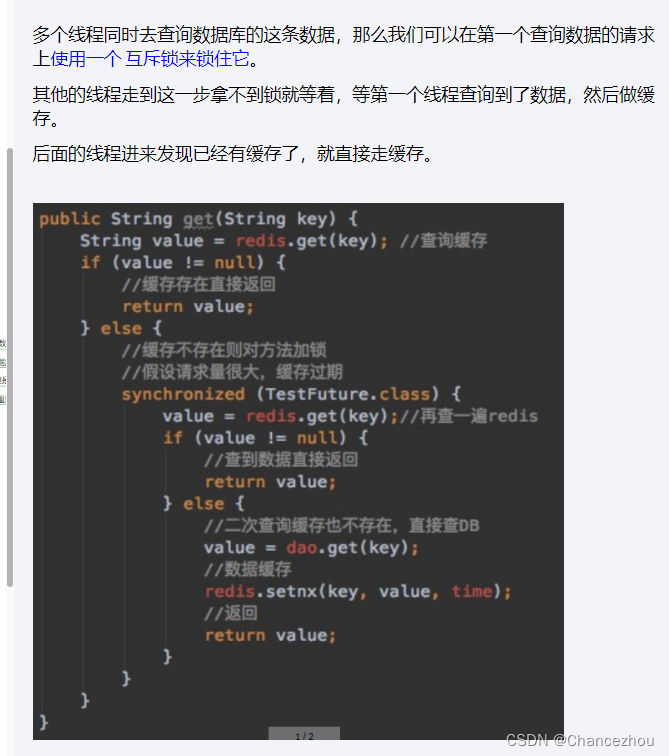
@Service @Slf4j public class UserService { public static final String CACHE_KEY_USER = "user:"; @Resource private UserMapper userMapper; @Resource private RedisTemplate redisTemplate; /** * 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行 * @param id * @return */ public User findUserById(Integer id) { User user = null; String key = CACHE_KEY_USER+id; //1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql user = (User) redisTemplate.opsForValue().get(key); if(user == null) { //2 redis里面无,继续查询mysql user = userMapper.selectByPrimaryKey(id); if(user == null) { //3.1 redis+mysql 都无数据 //你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redis return user; }else{ //3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率 redisTemplate.opsForValue().set(key,user); } } return user; } /** * 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。 * @param id * @return */ public User findUserById2(Integer id) { User user = null; String key = CACHE_KEY_USER+id; //1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql, // 第1次查询redis,加锁前 user = (User) redisTemplate.opsForValue().get(key); if(user == null) { //2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql synchronized (UserService.class){ //第2次查询redis,加锁后 user = (User) redisTemplate.opsForValue().get(key); //3 二次查redis还是null,可以去查mysql了(mysql默认有数据) if (user == null) { //4 查询mysql拿数据(mysql默认有数据) user = userMapper.selectByPrimaryKey(id); if (user == null) { return null; }else{ //5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作 redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS); } } } } return user; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
延时双删
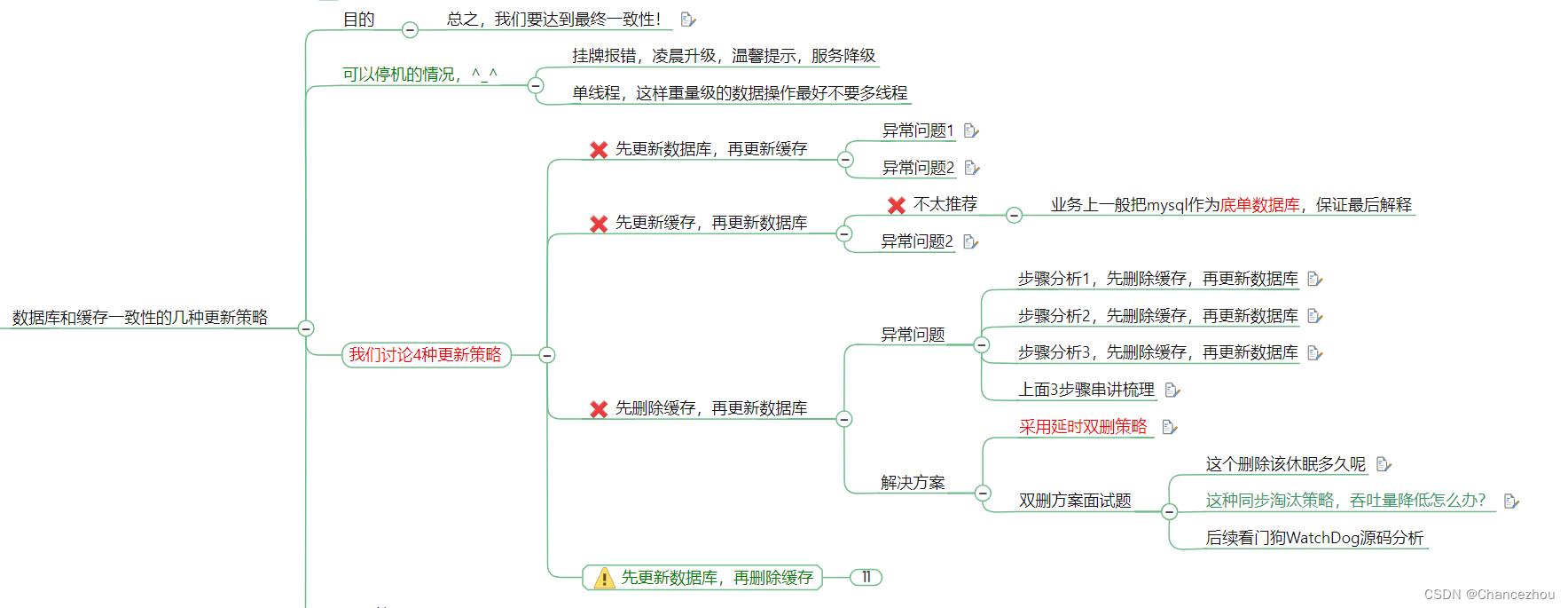
考虑异常和多线程并发

休眠时间多久?线程A sleep的时间,就需要大于线程B读取数据再写入缓存的时间。
这个时间怎么确定呢?
- 第一种方法:
在业务程序运行的时候,统计下线程读数据和写缓存的操作时间,自行评估自己的项目的读数据业务逻辑的耗时,以此为基础来进行估算。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上加百毫秒即可。
这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
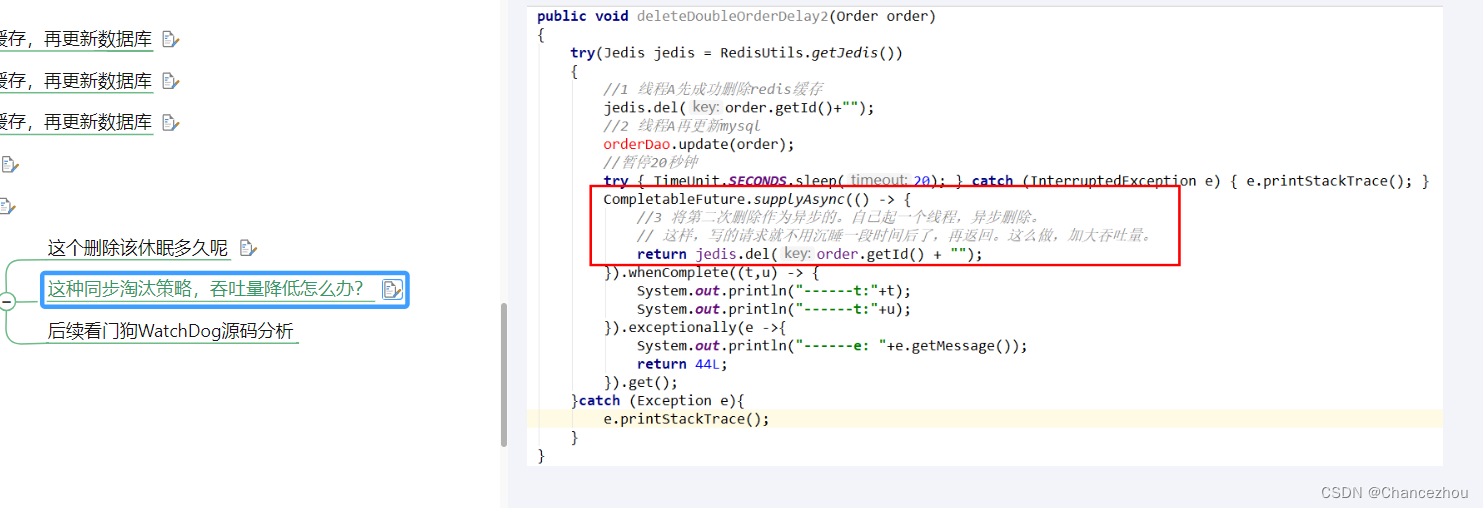
- 第二种方法:
新启动一个后台监控程序,比如后面要讲解的WatchDog监控程序,会加时
-
相关阅读:
html静态网站基于动漫网站网页设计与实现共计4个页面
java-php-python-绿色生活基于PS、DW的绿色环保宣传网站计算机毕业设计
UI设计都有哪些设计原则,分享三个给你
Android:使用命令行发现keytool不是内部命令解决办法
为什么要让员工入职流程实现自动化
100G以太网光模块解决方案
潮流来袭!中国首届虚拟艺术巡展NFS将在广州YCC!天宜盛大开启!
SQL—数据库查询语言,全面详解演示,入门进阶必会
树形结构-二叉树
【(数据结构)— 双向链表的实现】
- 原文地址:https://blog.csdn.net/weixin_46689011/article/details/136623477
