-
爬虫技术之正则提取静态页面数据
第一天
简单示例
在爬虫过程中,我们获取到了页面之后,通常需要做的就是解析数据,将数据持久化到数据库为我所用。如何又快又准确得提取有效数据?这是一门技术,看了我的博客之前可能略有难度,但各位大师看了我的博客之后,那只能说解析页面就像砍瓜切菜,喝水吃饭一般简单。
废话不说,直接搞示例,请看下面这个页面源码:
性別: 男 - 1
来来来,写个python代码提取性别?
分析一下,这不就是td标签内的数据嘛?写一个正则,提取男
正则得这么写,开头是中间是要提取的内容,使用()括起来,不管中间是啥,()内就写 .*?
最后以
看代码:# coding=utf-8 import re html_string = '''性別: 男 ''' regex = r' (.*?) ' result = re.findall(regex,html_string) print(result)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这个代码跑起来看看是牛还是马喽==>

果然是牛,🐂🐂🐂!
是不是感觉自己又行了,就是这么简单,后面慢慢试试复杂点页面,但都是解析方法从这个代码升级的,就是白开水,一眼望到底呀!今天懒得写了,我得去钓鱼了。已经空军16天,今天必须破龟,明天来继续搞代码。
第二天
贪婪与非贪婪模式
空军回来,又是新的一天,我们继续搞!
这里我们需要了解两种正则的匹配模式【贪婪模式鱼非贪婪模式】,主要掌握非贪婪模式,就能搞定市面上大部分页面解析需求,666!
看一眼贪婪模式,虽然不常用,但可能哪个面试狗(我从来不把面试官当人,因为我遇到的都很狗,🐕🐕🐕)问,傻冒!贪婪模式尽可能多地匹配所指定的字符。 在正则表达式中,默认情况下,大多数重复字符都是贪婪的,即它们尝试尽可能多次地匹配。 例如,.*将匹配尽可能长的字符串,即匹配到整个字符串,而不是仅仅匹配到第一个出现的子字符串。- 1
- 2
- 3
以下熟读并背诵,这个很重要!!!
非贪婪模式尽可能少地匹配所指定的字符。 非贪婪模式通常通过在重复字符后面加上一个?来实现。 例如,.*?将匹配尽可能短的字符串,即匹配到第一个出现的子字符串。- 1
- 2
- 3
我来找个字符串,搞个代码理解理解,不然说得太干!
字符串 “foobazquux”,我们想匹配两个尖括号< >之间的内容:
上代码瞧瞧:# coding=utf-8 import re # 原始字符串 text = "foobaz # 贪婪模式 greedy_pattern = re.compile(r'<.*>') # 创建了一个正则表达式对象,使用了贪婪模式,模式是 <.*>,表示匹配尖括号<和>之间的任意字符(包括零个字符或多个字符)。 greedy_match = greedy_pattern.search(text) # 使用 search() 方法在给定的文本字符串 text 中搜索与正则表达式 greedy_pattern 匹配的第一个子串。 print("贪婪模式匹配结果:", greedy_match.group()) # 使用 group() 方法返回与正则表达式模式匹配的文本。 # 非贪婪模式 non_greedy_pattern = re.compile(r'<.*?>') non_greedy_match = non_greedy_pattern.search(text) print("非贪婪模式匹配结果:", non_greedy_match.group())quux" - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
看看代码的运行结果,是牛还是马。
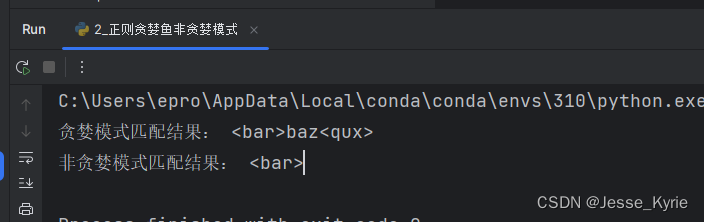
小小牛马,简单简单。了解了贪婪模式与非贪婪模式,我们基本上就可以搞定大部分的网页解析了,念在是初学者,又名菜鸡,还是多搞点案例来给大家修炼一下,顺便给大家一个匹配代码模板,以后只需要修改正则表达式即可,看完请说我牛b🐂🐂🐂
练习一
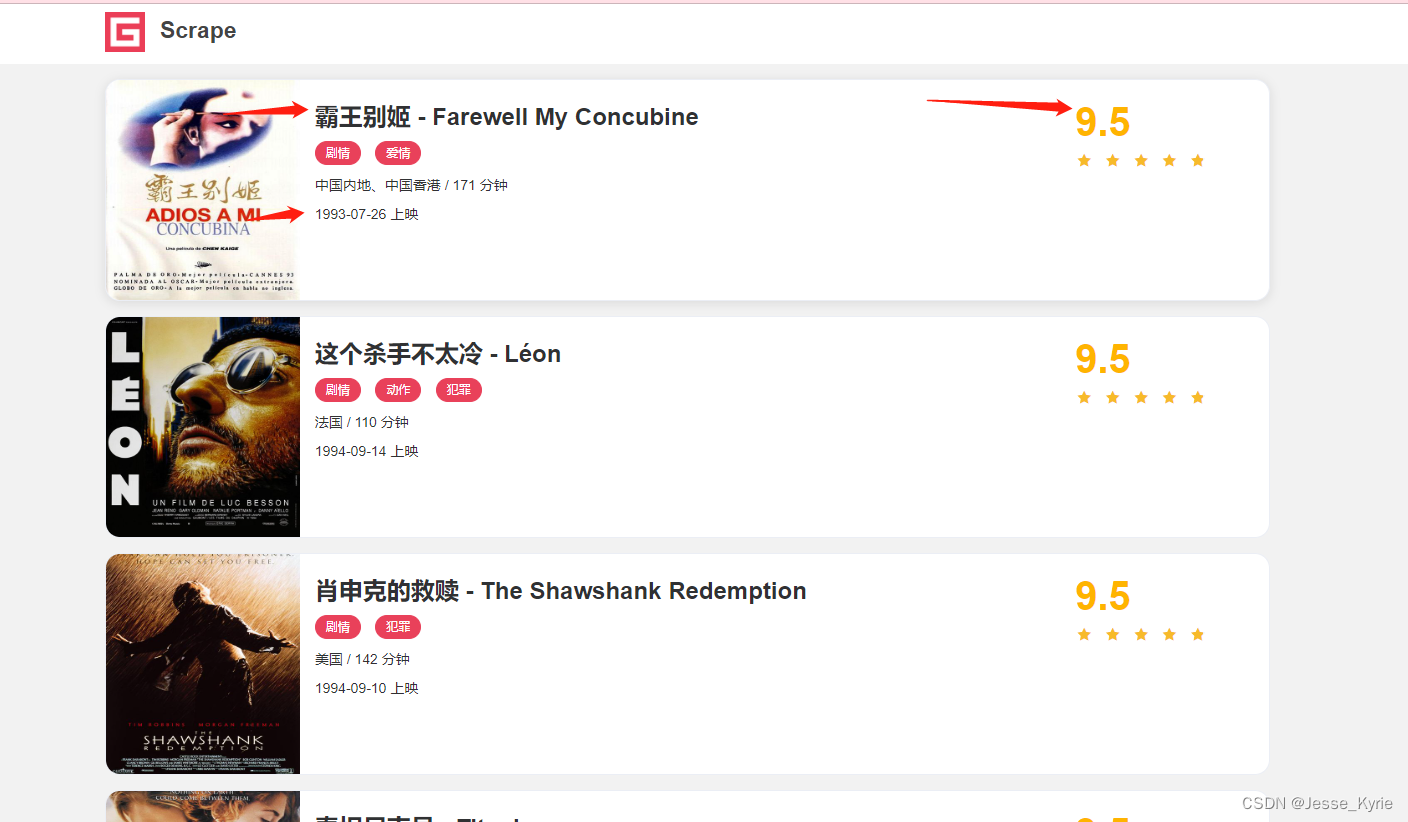
打开链接点我
,将电影名称,上映时间,评分采集并保存。
主要采集这三个数据
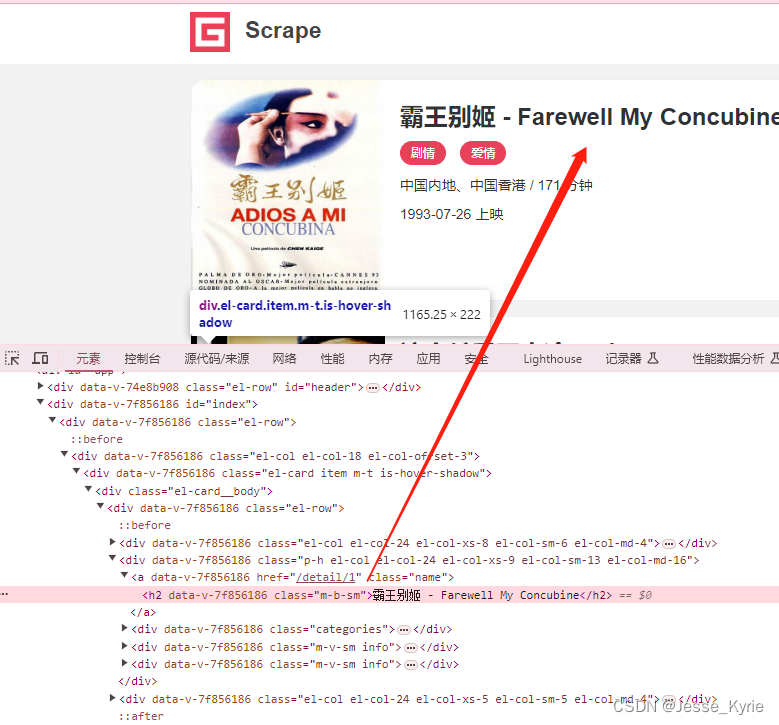
我们先来搞定标题的正则采集,标题长在这个里面,结果就下面这个b样
- 相关阅读:
京东API接口详情(各种API测试)
【无标题】
three.js 场景中如何彻底删除模型和性能优化
SpringBoot启动失败报错,spring.profiles.active:@env@中环境变量@无法识别报错_active: @env@
使用grabit分析mysql数据库中的数据血缘关系
锐捷网络C++开发实习有感
mac环境下搭建frida环境并连接网易mumu模拟器
RocketMQ——MQ基础知识
通俗易懂-OpenCV角点检测算法(Harris、Shi-Tomas算法实现)
令人心动的AI综述(1)
- 原文地址:https://blog.csdn.net/Jesse_Kyrie/article/details/136628421
