-
如何保证Redis和数据库数据一致性
缓存可以提升性能,减轻数据库压力,在获取这部分好处的同时,它却带来了一些新的问题,缓存和数据库之间的数据一致性问题。
想必大家在工作中只要用了咱们缓存势必就会遇到过此类问题
首先我们来看看一致性:
- 强一致性:任何一次读都能读到某个数据的最近一次写的数据。
- 弱一致性:数据更新后,如果能容忍后续的访问只能访问到部分或者全部访问不到,则是弱一致性。
1.读取数据
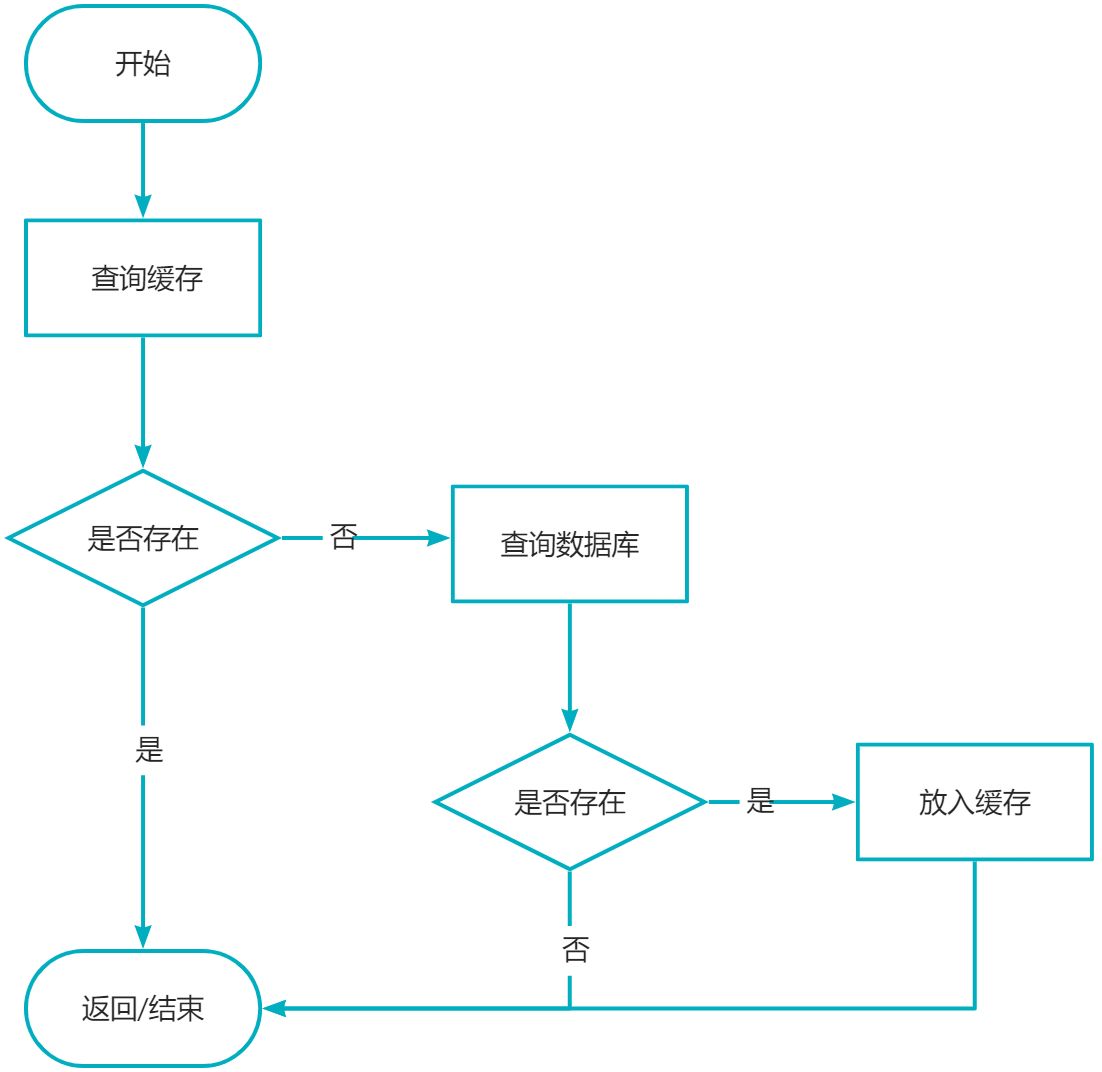
- 当应用程序需要从数据库读取数据时,先检查缓存数据是否命中。
- 如果缓存未命中,则查询数据库获取数据,同时将数据写到缓存中,以便后续读取相同数据会命中缓存,最后再把数据返回给调用者。
- 如果缓存命中,直接返回。
单独的只读取数据场景是不会出现不一致。 只有读和写一起才会出现 , 那我们再来说下写数据的场景
问题:如果数据库中的某条数据放入缓存后,又马上被更新了,那我们应该如何更新缓存
2.写数据
当我们对数据进行修改的时候,到底是先删缓存,还是先写数据库?
- 先更新缓存再更新数据库
- 先删除缓存再更新数据库
- 先更新数据库再更新缓存
- 先更新数据库再删除缓存
无非就是缓存用更新或用删除?推荐直接删除
为什么不更新?而直接删, 因为缓存的更新成本更高(因为你写入数据库的值,很多情况并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是浪费性能的。显然,删除缓存更为适合。)删除缓存操作简单,副作用只是增加了一次 chache miss,建议大家使用该策略。
先操作数据库还是先操作缓存?
2.先操作缓存
2.1先更新缓存,再更新数据库

缺点:如果先更新缓存成功,在更新数据库的时候失败,这时候会导致数据不一致;缓存的作用是不是临时将我们数据保存在内存,便于提高查询速度;但是如果某条数据在数据库中都不存在,缓存这种数据没有一点意义
2.2.先删除缓存,再更新数据库

缺点:高并发场景下,如果多个线程同时执行更新数据库再写缓存操作可能会出现数据库是新值,而缓存中是旧值

2.3.先删缓存再删数据库

先删缓存再删数据库:在多线程环境下,当一个线程把缓存删掉之后,另一个线程读缓存,读不到缓存就会直接读库,读到数据后就会更新缓存,先前的线程呢,才更新数据库,会造成缓存脏读的情况,很容易产生缓存脏读。
而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
3.先操作数据库
3.1.先更新数据库,再更新缓存

优点:可以解决先更新缓存,再更新数据库带来的假数据问题
缺点:高并发场景下,如果多个线程同时执行更新数据库再写缓存操作可能会出现数据库是新值,而缓存中是旧值

3.2.先更新数据库,再删除缓存
在高可用的系统系统里面,我们追求数据最终一致性的话,我们可以考虑先更新数据库,再去删除缓存
也算是常用的方案,这里介绍一下,这个叫 Cache Aside Pattern。如果先更新数据库,再删除缓存,那么就会出现更新数据库之前有瞬间数据不是很及时。
同时,如果在更新之前,缓存刚好失效了,读客户端有可能读到旧值,然后在写客户端删除结束后再次设置了旧值,非常巧合的情况。
有 2 个前提条件:缓存在写之前的时候失效,同时,在写客户度删除操作结束后,放置旧数据 — 也就是读比写慢。设置有的写操作还会锁表。
这个很难出现,但是如果出现了怎么办?使用双删!!!



3.3先删数据库再删缓存

先删数据库再删缓存,在多线程情况下,当一个线程删除数据库,另一个线程读取缓存数据,读到的是缓存的数据,当先前一个线程删完数据库后就会更新缓存,这是缓存就正常了,产生了一次脏读。
5.解决
5.1.强一致性?
在强一致性系统中,通过2PC、Paxos或分布式锁保持一致性可能会成为影响系统吞吐量、响应时间和可伸缩性的昂贵开销, 因此通常采用一种相当宽松的一致性方法,称为最终一致性。
5.2.最终一致性:延时双删

关键:间隔一段时间再删除是为了保证并发读请求写入的旧值最终能够被第二次删除删除掉
缺点:延时双删可能对我们性能要求方面不能有太高的要求
注意:我们需要自行评估项目的读数据业务逻辑的耗时(即线程二从数据库读取数据 写入缓存完成), 防止线程二覆盖掉新数据
如果第二次删除缓存失败怎么办?
4.为了防止删除缓存失败,可以进行重试机制
- 同步重试,如果并发量高的时候可能会影响接口性能
- 异步重试:
- 创建单独的一个线程,进行重试;但是在高并发的场景下,可能会因为创建线程太多,导致OOM
- 交给线程池处理;但是如果服务重启,会导致数据丢失
- 重试数据写入表,通过定时任务重试(可以保证数据不丢失,但是对于实时性要求较高的该场景不太适用)
- 利用MQ消息中间件进行重试,在消费者中处理

- 订阅mysql的binlong,在订阅者中,如果发现更新数据请求,则删除响应的缓存,比如使用canal中间件;为了保证删除缓存成功,可以增加MQ

6.总结缓存策略的最佳实践是 **Cache Aside Pattern。**分别分为读缓存最佳实践和写缓存最佳实践。
读缓存最佳实践:先读缓存,命中则返回;未命中则查询数据库,再写到数据库。
写缓存最佳实践:
- 先写数据库,再操作缓存;
- 直接删除缓存,而不是修改,因为缓存的更新成本很高,删除缓存操作简单,副作用只是增加了一次 chache miss,建议大家使用该策略。
在以上最佳实践下,为了尽可能保证缓存与数据库的一致性,我们可以采用延迟双删。
防止删除失败,我们采用异步重试机制保证能正确删除,异步机制我们可以发送删除消息到 mq 消息中间件,或者利用 canal 订阅 MySQL binlog 日志监听写请求删除对应缓存。
那么,如果我非要保证绝对一致性怎么办,先给出结论:
没有办法做到绝对的一致性,这是由 CAP 理论决定的,缓存系统适用的场景就是非强一致性的场景,所以它属于 CAP 中的 AP。
所以,我们得委曲求全,可以去做到 BASE 理论中说的最终一致性。
其实一旦在方案中使用了缓存,那往往也就意味着我们放弃了数据的强一致性,但这也意味着我们的系统在性能上能够得到一些提升。
-
相关阅读:
ElasticSearch--分片的路由原理
真香:Alibaba开源GitHub星标100K微服务架构全彩进阶手册
Vue 忽略自定义标签名&插件开发&组件数据传递和共享—>父传子
MapStruct的使用
算法竞赛进阶指南 搜索 0x28 IDA*
【pen200-lab】10.11.1.50
BUUCTF Basic 解题记录--BUU XXE COURSE
C++ 指针调用
【makedown使用介绍】
django 实现:闭包表—树状结构
- 原文地址:https://blog.csdn.net/qq_20957669/article/details/136711239