-
面试真经(运维工程师)
1.介绍一下ansible以及他的工作原理和框架
Ansible 架构由两种计算机组成,分别为:控制节点和受管主机。Ansible 在控制节点上安装和运行,该 计算机上也含有 Ansible 项目文件的副本。
受管主机列在清单中,清单还可以将这些系统组织到组中,以便于集中管理。你可以在文本中静态定义 清单,也可以通过从外部来来源获取群组和主机信息的脚本来动态确定。
Ansible 用户无需编写复杂的脚本,而只要创建高级别 play 即可确保主机或主机组处于特定状态。Play 按该 play 指定的顺序对主机执行一系列任务。这些 play 通过采用 YAML 格式的文本文件来表达。包含 一个或多个 play 的文件称为 playbook。
每个任务运行一个模块,即一小段代码。各个模块基本上是你的工具包中的一个工具。Ansible 随附了数 百个实用模块,它们能够执行许多不同的自动化任务。它们可以作用于系统文件,安装软件或者进行 API 调用。
在任务中使用时,模块通常确保计算机的某一特定方面处于特定的状态。例如,任务在使用某个模块时 可以确保文件存在并具有特定的权限和内容。任务使用不同模块可以确保已安装特定文件系统。如果系 统不处于指定的状态,任务应将其置于相应状态,但也可能什么都不做。如果任务失败,Ansible 默认会 对出错主机中止 playbook 的其余部分,其他主机不受影响。 任务、play 和 playbook 均具有幂等性。这意味着,你可以在相同的主机上多次安全地运行一个 playbook。当你的系统处于正确状态时,playbook 在运行时不会进行任何更改。有很多模块可供你用于 运行任意命令。但是,你必须小心使用这些模块,以确保其以幂等方式运行。 Ansible 也使用插件。插件时你可以添加到 Ansible 中的代码,以对它进行扩展并使它适合新的用途和平 台。
Ansible 架构是无代理。通常,当管理员运行 AnsiblePlaybook 时,控制节点会使用 SSH (默认)或 WinRM 连接受管主机。这意味着,你不需要在受管主机上安装 Ansible 专用代理,也不需要允许控制节 点和受管主机之间进行其他通信
工作原理
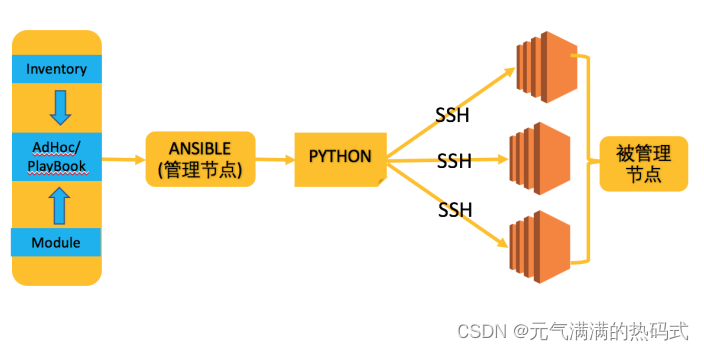
1、在ANSIBLE 管理体系中,存在"管理节点" 和 "被管理节点" 两 种⻆⾊。
2、被管理节点通常被称为"资产"
3、在管理节点上,Ansible将 AdHoc 或 PlayBook 转换为Python 脚本。
并通过SSH将这些Python 脚本传递到被管理服务器上。
在被管理服务器上依次执⾏,并实时的将结果返回给管理节点。
2.谈谈关于SQL优化
- 创建和使用索引:
- 为经常用于搜索、排序和连接的列创建索引。
- 使用复合索引时,要遵循最佳左前缀法则,即查询条件使用了复合索引的最左侧列时,索引才有效。
- 避免在索引列上使用函数或计算,这会导致索引失效。
- 定期审查和维护索引,删除不必要的索引以减少存储和维护成本。
- 优化查询语句:
- 尽量避免在
WHERE子句中使用!=或NOT IN,这些操作通常会导致全表扫描。 - 尽量减少子查询的使用,尤其是作为被驱动表的子查询,因为子查询可能导致额外的数据扫描。
- 尝试使用
JOIN替代子查询,当能够直接多表关联时,尽量直接关联。 - 在使用
LEFT JOIN时,尽量让实体表作为被驱动表,以减少不必要的数据扫描。 - 优化
WHERE子句中的连接顺序,先过滤出少量数据再进行连接操作。
- 尽量避免在
- 使用数据库特性:
- 利用数据库的查询缓存功能,对于相同的查询,可以直接从缓存中获取结果,避免重复计算。
- 使用数据库的分区功能,将数据分散到不同的物理存储上,提高查询性能。
- 调整数据库配置:
- 根据硬件和负载情况,调整数据库的缓存大小、连接数等配置参数。
- 启用慢查询日志,分析并优化那些执行时间较长的查询。
- 避免全表扫描:
- 尽量通过索引来访问数据,减少全表扫描的次数。
- 在可能的情况下,使用
LIMIT子句限制返回的数据量。
- 优化数据结构:
- 正规化数据库设计,避免数据冗余和不一致。
- 在某些情况下,可以考虑使用反规范化来提高查询性能。
- 使用预编译查询:
- 对于经常执行的查询,可以使用预编译查询来提高性能。
- 考虑使用临时表:
- 对于复杂的查询,可以考虑使用临时表暂存中间结果,以减少重复计算和数据扫描。
- 监控和分析:
- 使用数据库的监控工具分析查询性能瓶颈。
- 定期检查执行计划,确保查询使用了正确的索引和策略。
- 硬件和基础设施优化:
- 根据数据库负载情况,考虑升级硬件或优化存储、网络等基础设施。
3.什么情况下会使用MySQL中的锁:
- 读写锁(共享锁和排他锁):
- 当多个事务需要读取同一行数据时,可以使用共享锁(读锁),允许多个事务同时读取该行数据。
- 当一个事务需要修改某行数据时,它会先获得该行的排他锁(写锁),防止其他事务同时读取或修改该行数据。
- 表锁:
- 在某些情况下,为了简化锁的管理或提高性能,可能会使用表锁。表锁会锁定整个表,阻止其他事务对该表进行读写操作。
- 行级锁和页级锁:
- 行级锁是MySQL InnoDB存储引擎提供的一种锁策略,它只锁定需要操作的行,而不是整个表。这可以提高并发性能,减少锁冲突。
- 页级锁是介于行级锁和表级锁之间的一种锁策略,它锁定的是数据页而不是单个行。在某些场景下,页级锁可以在性能和并发之间取得一个较好的平衡。
4.什么情况下会使用多进程与多线程:
- 多进程:
- 当需要充分利用多核CPU资源时,可以使用多进程。每个进程可以在独立的CPU核心上运行,实现真正的并行计算。
- 当应用需要较高的稳定性和隔离性时,可以使用多进程。每个进程有自己的内存空间和系统资源,一个进程的崩溃不会影响其他进程。
- 多线程:
- 当应用中存在大量的IO操作(如文件读写、网络通信)时,使用多线程可以提高并发性能。线程之间的切换成本比进程低,适合处理高并发的场景。
- 当需要共享数据或资源时,多线程是一个更好的选择。因为所有线程都在同一个进程内,可以方便地访问和修改共享数据
5.docker如何解决CPU占用率高的情况:
- 限制容器的CPU使用:使用Docker的
--cpus参数来限制容器可以使用的CPU核心数或百分比。 - 优化应用:对运行在容器内的应用进行性能优化,减少不必要的计算或资源消耗。
- 垂直或水平扩展:如果单个容器或主机无法满足需求,可以考虑增加更多的主机进行水平扩展,或者升级主机硬件进行垂直扩展。
- 使用容器编排工具:如Kubernetes等,可以更有效地管理容器资源,实现资源的动态分配和调度
- 创建和使用索引:
-
相关阅读:
Git实操图文详解系列教程(4)——IDEA集成GitHub
【Overload游戏引擎细节分析】视图投影矩阵计算与摄像机
yarn 设置淘宝镜像配置
中兴面试-Java开发
Redis分布式锁实现Redisson 15问
3.1 FiRa标准——UCI通用规范(一)
【图像分割】距离正则化水平集演化及其在图像分割中的应用(Matlab代码实现)
RT-Thread内核学习记录
音视频基础知识
计算机毕业设计(附源码)python迎新管理系统
- 原文地址:https://blog.csdn.net/m0_66011019/article/details/136736997