-
K倍区间(蓝桥杯)
K倍区间
题目描述
给定一个长度为 N的数列,A1,A2,…AN,如果其中一段连续的子序列 Ai,Ai+1,…Aj 之和是 K的倍数,我们就称这个区间 [i,j]是 K倍区间。
你能求出数列中总共有多少个 K倍区间吗?
输入格式
第一行包含两个整数 N和 K。以下 N行每行包含一个整数 Ai。
输出格式
输出一个整数,代表 K倍区间的数目。数据范围
1≤N,K≤100000,
1≤Ai≤100000输入样例:
5 2 1 2 3 4 5- 1
- 2
- 3
- 4
- 5
- 6
输出样例:
6- 1
前缀和+数学优化
#include// 包含所有标准库 using namespace std; const int z=1e5+10; // 定义常量z作为数组大小的上限 long long a[z],s[z],cnt[z]; // 定义三个数组,a存储输入的数列,s存储前缀和,cnt用于记录各个模数出现的次数 int main() { int n,k; // n代表数列的长度,k代表区间和的倍数 scanf("%d%d",&n,&k); // 读入n和k for(int i=1;i<=n;i++) { scanf("%lld",&a[i]); // 读入数列的每个数 s[i]=s[i-1]+a[i]; // 计算前缀和,s[i]表示数列前i个数的和 } long long res=0; // 存储最终结果,即总的K倍区间数目 cnt[0]=1; // 初始化cnt数组,cnt数组用来记录各个模k的值的出现次数,其中cnt[0]初始化为1表示和为0的情况 for(int r=1;r<=n;r++) { res+=cnt[s[r]%k]; // 对于每个r,累加s[r]模k后相同余数的次数,这代表之前有多少个前缀和与当前的s[r]模k得到相同结果 cnt[s[r]%k]++; // 更新当前余数出现的次数 } printf("%lld",res); // 输出结果 return 0; // 程序结束 } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
在这个代码中,
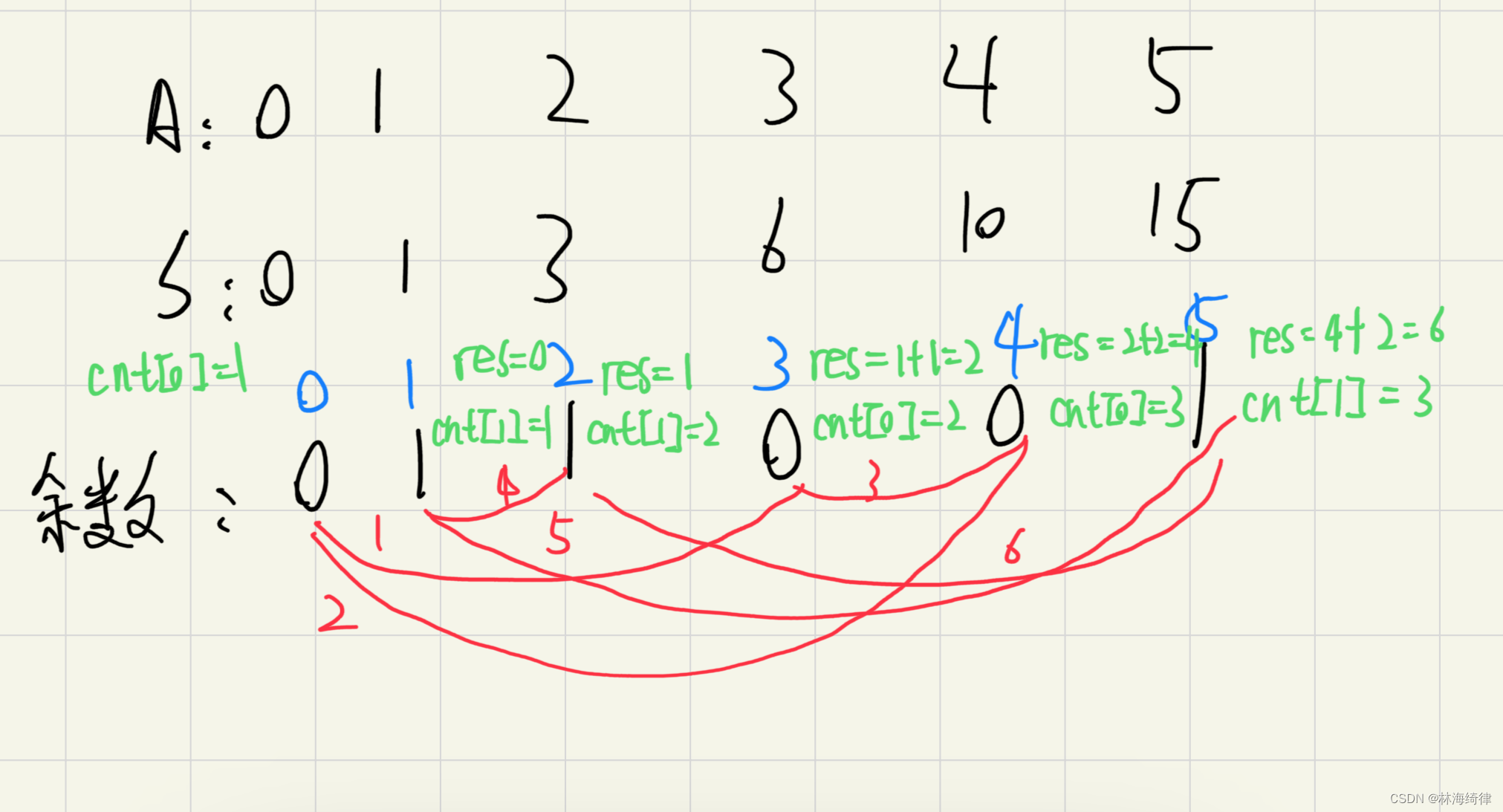
s[r] % k的含义是计算前缀和s[r]模上k的余数。当两个前缀和模k的余数相等时,它们之间的区间和是k的倍数。因此,通过记录和计算每个模k余数的出现次数,我们可以确定有多少个这样的子序列满足条件。例如,如果
s[i] % k == s[j] % k且i < j,那么(s[j] - s[i]) % k == 0,也就是说子序列[i + 1, j]的和是k的倍数。cnt[s[r]%k]就是用来记录到当前位置为止,模k余数相同的前缀和数量。res变量用来累加每次新增的K倍区间数量。这是一个非常典型的利用余数性质和前缀和技巧来解决子区间问题的示例。通过这种方法,我们可以将原本可能需要O(N^2)时间复杂度的问题优化到O(N)。
代码部分解释
long long res=0; // 存储最终结果,即总的K倍区间数目 cnt[0]=1; // 初始化cnt数组,cnt数组用来记录各个模k的值的出现次数,其中cnt[0]初始化为1表示和为0的情况 for(int r=1;r<=n;r++) { res+=cnt[s[r]%k]; // 对于每个r,累加s[r]模k后相同余数的次数,这代表之前有多少个前缀和与当前的s[r]模k得到相同结果 cnt[s[r]%k]++; // 更新当前余数出现的次数 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
当然,让我更详细地解释这个过程:
在这个问题中,我们要计算子序列和为K的倍数的区间数量。为了高效计算,我们使用了前缀和数组
s,以及一个计数数组cnt。前缀和
s[i]表示第一个元素A[1]到当前元素A[i]的总和。前缀和的有用之处在于,它允许我们快速计算任何子序列A[i...j]的和为s[j] - s[i-1]。接着,我们使用模运算来帮助我们找到K的倍数。对于任意整数x,如果
x % K == 0,那么x是K的倍数。对于两个数x和y,如果它们除以K的余数相同,那么x - y是K的倍数。我们利用这个性质来找到我们的K倍区间。在程序中,变量
res用于累计找到的K倍区间的总数。数组cnt用于存储对于前缀和数组s中每个元素取模K后得到的余数的出现次数。cnt[0] = 1;的目的是为了处理那些从A[1]开始的前缀和本身就是K的倍数的情况。因为前缀和数组是从下标1开始的,所以在没有任何元素的情况下,我们可以认为有一个和为0的前缀和(也就是说,我们从数组的开始处就有一个零长度的前缀和)。在主循环中,对于每个下标r(从1到n),我们做两件事:
-
res += cnt[s[r] % k];:
这一行是计算结果的核心。我们取当前前缀和s[r]除以K的余数,然后在cnt数组中查找这个余数之前出现了多少次。这个余数之前出现的次数,即表示有多少个之前的前缀和与s[r]除以K的余数相同。由于之前的前缀和与当前的s[r]有相同的余数,这意味着从那个前缀和的下一个位置到当前位置r的子序列和是K的倍数。所以,我们将这个数量加到res上。 -
cnt[s[r] % k]++;:
这一行更新计数数组。我们增加当前余数的出现次数,因为我们刚刚考虑了一个新的前缀和s[r]。
通过这种方式,我们可以在遍历数组的同时,累计找到的K倍区间的数量。这种方法是非常高效的,因为它只需要一次遍历(O(N)时间复杂度),而不是对每个可能的子序列都进行检查(这将需要O(N^2)时间复杂度)。
-
相关阅读:
一文拿捏SpringMVC的调用流程
7. 矢量图层数据查询选择和保存
神经网络优化图片大全,神经网络优化图片下载
国内各大安卓应用市场的不同ASO优化点
layui2.9.7-入门初学
Spring的配置Bean的方式
超简单理解冒泡排序
Beautiful Soup爬取数据html xml
Vue中常用的rules校验规则
分类预测 | Matlab实现基于PSO-SDAE粒子群优化算法优化堆叠去噪自编码器的数据分类预测
- 原文地址:https://blog.csdn.net/m0_73841621/article/details/136568338
