-
使用Julia语言和R语言实现K-均值
K-均值算法基础
K-均值聚类算法属于一种无监督学习的方法,通过迭代的方式将数据划分为K个不重叠的子集(簇),每个子集由其内部数据点的平均值来表示。计算方法大体如下:
1.初始化簇中心
选择K个数据点作为初始的簇中心,簇中心可以随机选择的,也可以基于某种启发式方法选择,初始簇中心的选择对算法的最终结果有很大影响,不同的初始选择可能会导致完全不同的聚类结果
2.计算欧几里得距离
对于数据集中的每个点
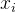 ,计算它到各个簇中心
,计算它到各个簇中心 的距离
的距离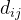 ,通常使用欧几里得距离来计算。欧几里得距离衡量了数据点在多维空间中的实际距离,在K-均值算法中,数据点被分配给距离其最近的簇中心所在的簇。
,通常使用欧几里得距离来计算。欧几里得距离衡量了数据点在多维空间中的实际距离,在K-均值算法中,数据点被分配给距离其最近的簇中心所在的簇。
3.分配数据点
根据计算出的距离,将数据点分配给最近的簇。对于每个数据点
,找到距离它最近的簇中心 ,并将其分配给该簇。
,并将其分配给该簇。
4.更新簇中心
重新计算每个簇中所有数据点的平均值,并将该平均值设置为新的簇中心。对于每个簇
 ,新的簇中心
,新的簇中心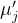 计算如下:
计算如下:
5.终止迭代
重复步骤2、3和4,直到簇中心不再发生显著变化,或者达到预定的迭代次数。迭代终止条件可以表示为:

R语言数据集iris
iris数据集是 R 语言的内置数据集,其中包含了 3 种不同类型的鸢尾花(Iris flower)的观测数据,每种鸢尾花有 50 个样本,总共有 150 个样本。每个样本都包含了 4 个关于花萼(sepal)和花瓣(petal)的测量数据,以及鸢尾花的种类信息。iris数据集中的每个样本都包含以下 4 个数值型特征:Sepal.Length(花萼长度,单位是厘米)Sepal.Width(花萼宽度,单位是厘米)Petal.Length(花瓣长度,单位是厘米)Petal.Width(花瓣宽度,单位是厘米)
此外还有一个分类变量
Species,表示鸢尾花的种类,包含三个水平:setosa、versicolor和virginica,分别对应山鸢尾、杂色鸢尾和维吉尼亚鸢尾。在RStudio里可以输入
iris来查看这个数据集的内容。iris数据集内容:
Julia语言实现
先进入Julia REPL导入需要的Julia包:
] # 进入包管理模式- add RDatasets # R语言的数据集
- add DataFrames # 数据处理包
- add Clustering # 提供 K-均值 功能包
- add Gadfly #绘图包
Julia语言实现K-均值代码:
- using RDatasets
- using DataFrames
- using Clustering
- using Gadfly
- # 使用的R语言的iris 数据集
- iris = dataset("datasets", "iris")
- # 提取数据集的前四列作为特征矩阵,使用Matrix()函数把DataFrame的子集进行矩阵转换
- features = Matrix(iris[:, 1:4])
- # 执行 K-means 聚类, 分成 3 个簇
- k = 3
- results = kmeans(features, k)
- # 提取聚类分配结果
- assignments = results.assignments
- plot = Gadfly.plot(iris, x=:SepalLength, y=:SepalWidth, color=assignments, Geom.point)
- display(plot)
代码运行后生成HTML图像

教材中旧版本代码
- # GGboy版本再次之上增加了数据集转换
- using RDatasets
- using Clustering
- using Gadfly
- mydata1 = dataset("datasets", "iris")
- myf = convert(Array, mydata1[:,1:4])
- myl = convert(Array, mydata1[:,5])
- x = initseeds(:rand, convert(Matrix, myf'), 3)
- myres = kmeans(myf, 3)
- Gadfly.plot(mydata1, x = :PetalLength, y = PetalWidth, color = myres.assignments,
- Geom.point)
R语言实现
先导入 ggplot2包用于绘图
install.packages("ggplot2")R语言实现K-均值代码:
- library(ggplot2)
- data(iris)
- # 提取前四列特征矩阵
- features <- iris[, 1:4]
- k <- 3 # 执行 K-means 聚类, 分成 3 个簇
- set.seed(123) # 设置随机种子以获得可重复的结果
- results <- kmeans(features, centers = k)
- iris$cluster <- as.factor(results$cluster)
- ggplot(iris, aes(x = Sepal.Length, y = Sepal.Width, color = cluster)) +
- geom_point(size = 3, alpha = 0.8) +
- theme_minimal() +
- labs(title = "K-means Clustering",
- x = "Sepal Length",
- y = "Sepal Width",
- color = "Cluster")
生成图像:

Markdown版本计算公式及说明
- # K-均值算法公式
- ## 1. 初始化簇中心
- 选择K个数据点作为初始的簇中心(质心)。这些点可以是随机选择的,也可以是基于某种启发式方法选择的。
- 初始簇中心的选择对算法的最终结果有很大影响。不同的初始选择可能会导致完全不同的聚类结果。因此,在实际应用中,通常会多次运行算法并使用不同的初始簇中心,然后选择其中最好的结果。
- ## 2. 计算欧几里得距离
- 对于数据集中的每个点\(x_i\),计算它到各个簇中心\(\mu_j\)的距离\(d_{ij}\)。通常使用欧几里得距离来计算。
- \[d_{ij} = \sqrt{(x_i - \mu_j)^T(x_i - \mu_j)}\]
- 欧几里得距离是最常用的距离度量方法之一,它衡量了数据点在多维空间中的实际距离。在K-均值算法中,数据点被分配给距离其最近的簇中心所在的簇。
- ## 3. 分配数据点
- 根据计算出的距离,将数据点分配给最近的簇。对于每个数据点\(x_i\),找到距离它最近的簇中心\(\mu_{j^*}\),并将其分配给该簇。
- \[j^* = \arg\min_{j=1,2,...,K} d_{ij}\]
- 这一步是根据距离度量将数据点划分到不同的簇中。每个数据点都被分配给距离其最近的簇中心所在的簇。这样,数据集就被划分成了K个不重叠的子集。
- ## 4. 更新簇中心
- 重新计算每个簇中所有数据点的平均值,并将该平均值设置为新的簇中心。对于每个簇\(C_j\),新的簇中心\(\mu_j'\)计算如下:
- \[\mu_j' = \frac{1}{|C_j|} \sum_{x_i \in C_j} x_i\]
- 这一步是更新簇中心的过程。通过计算每个簇中所有数据点的平均值来得到新的簇中心。这些新的簇中心将用于下一轮的迭代计算中。
- ## 5. 终止迭代
- 重复步骤2、3和4,直到簇中心不再发生显著变化,或者达到预定的迭代次数。迭代终止条件可以表示为:
- \[\|\mu_j' - \mu_j\| < \epsilon\]
- 其中,\(\epsilon\)是一个很小的正数,表示簇中心变化的阈值。当簇中心的变化小于该阈值时,算法停止迭代。
-
相关阅读:
报表控件Stimulsoft Report中的 自定义QR 码教程
day03_python基础
[Ansible专栏]Ansible安装和基本使用
【Computer Vision】基于卷积神经网络实现美食分类
组合控件——增强型列表——循环视图RecyclerView——布局管理器LayoutManager
软件测试的方法详细介绍
Java小技巧:巧用函数方法实现二维数组遍历
take和 drop功能还有takewhile 和 dropwhile 功能主要用于分开list
vue实现预览编辑ppt、word、pdf、excel、等功能的解决方案(内网-前端)
CSAPP 之 BombLab 详解
- 原文地址:https://blog.csdn.net/m0_73500130/article/details/136585338
