-
论文笔记:Lost in the Middle: How Language Models Use Long Contexts
Transactions of the Association for Computational Linguistics 2024
1 intro
- 论文对大模型在长文本情况下的性能做了一系列实验研究,发现了一个有趣的“Lost in the middle”现象:
- 在处理需要识别相关上下文的信息的任务(文档问答、键值对索引)时,大模型对相关信息的位置很敏感
- 当相关的信息在输入prompt的开头或者结尾时,能够取得较好的效果
- 而当相关的信息在prompt中间部分时,性能会显著下降。

2 实验
2.1 多文档问答实验
2.1.1 输入prompt格式

- 对于每个问题,主要包含1个能回答该问题的相关文档以及其他一些不相关的文档,这个相关文档被插入在不同的位置来测试大模型的稳定性
2.1.2 结果

- 在总文档数分别为10、20、30,对应token数约为2K、4K、6K时,均发现相关文档位于prompt的开始或者结尾时,能够取得更好的效果,而相关文档位于中间时,性能下降
- 那么,如果使用支持更长上下文的模型呢?(gpt-3.5-turbo-16K-0613 VS gpt-3.5-turbo-0613)
- 在这个任务上并未获得显著更优的结果
2.2 键值对查询实验
2.1.1 输入prompt格式

2.1.2 结果

- 对于比较优秀的模型,如claude-1.3-100k、claude-1.3,它们在4k、8k、16k的上下文长度下,不管目标key在哪个位置,都能取得接近100%的准确率;
- 对于差一些的模型,仍然有相似的现象,目标key位于中间位置时,取得较差的结果
3 讨论
3.1 模型架构的影响
- 是否和LLM的模型架构相关?Decoder-only/Encoder-Decoder等架构的LLM是否会有不同的表现?
- ——>之前的实验用的模型都是Decoder-only的架构,于是论文增加了两种Encoder-Decoder模型(flan-t5-xxl、flan-ul2)
- 发现还是类似的现象
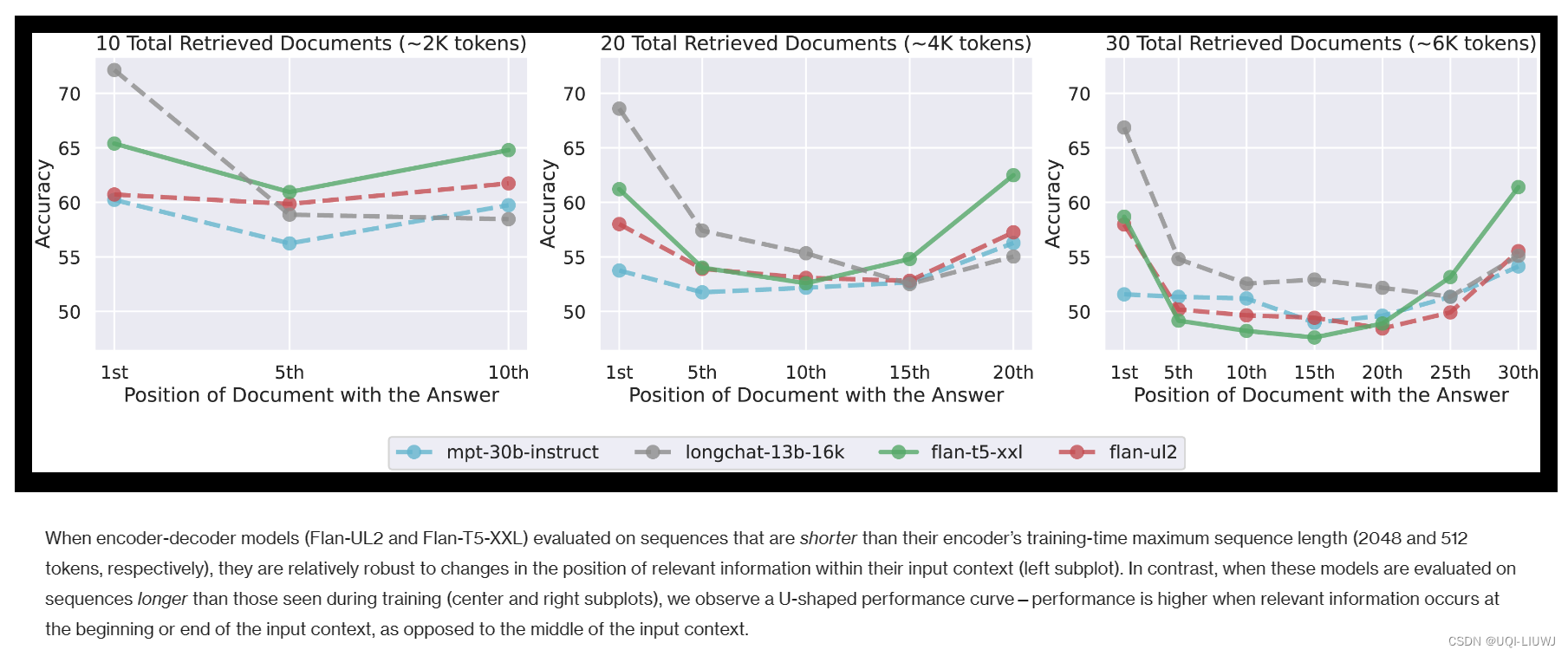
3.2 query和文档的相对位置
前面的实验都是将query放在文档之后进行的,那么将query放在文档之前,会有什么样的结果呢?
——>将query放在文档之前同样有“Lost in the middle”的现象

3.3 有监督finetune 的影响
- 之前的模型都是带finetune的,于是论文比较了没有finetune情况下的差异
- 发现及时没有指令微调,仍然会出现lost in the middle的现象

- 论文对大模型在长文本情况下的性能做了一系列实验研究,发现了一个有趣的“Lost in the middle”现象:
-
相关阅读:
奖补来啦!2022年新洲区科技企业梯次培育专项资金申报条件、材料和补贴标准
【机器学习】基于CNN-RNN模型的验证码图片识别
Spring Cloud Alibaba(四)
深度解析服务细分赛道公链
.NET MVC Spring配置及常见问题处理
Discord将切换到临时文件链接以阻止恶意软件传播
HyperLynx(三十二)高速串行总线仿真(四)
用趋动云GPU部署自己的Stable Diffusion
jenkins配置用户权限分配角色和视图(三)
Python基础
- 原文地址:https://blog.csdn.net/qq_40206371/article/details/136644954