-
【Redis】Redis 缓存重点解析
Redis 缓存重点解析
推荐文章:【Redis】Redis的特性和应用场景 · 数据类型 · 持久化 · 数据淘汰 · 事务 · 多机部署-CSDN博客
1. 我看你的项目都用到了 Redis,你在最近的项目的哪些场景下用到了 Redis 呢?
一定要结合业务场景来回答问题!要是没有不要硬讲,除非面试官问;

接下来面试官将深入发问。
- 你没用到的也可能会试探着去问;
2. 缓存三兄弟
正常的场景是这样的:

2.1 缓存穿透

缓存穿透:查询一个不存在的数据的时候,MySQL 查询不到数据也不会写入缓存,就会导致每次这样的查询请求都不会命中 Redis 的缓存,每次都穿过 Redis,查询 MySQL;
解决方案:
- 缓存 null 值
也就是查询出来的结果不存在,也将其缓存出来,例如:
{"id:1": null}- 1
优点:简单直接有效;
缺点:消耗内存比较大,可能会出现双写不一致的问题,需要去维护双写一致性;
- 布隆过滤器

也就是通过布隆过滤器判断键值是否存在,再判断是否读缓存,再决定是否读 MySQL:
- 布隆过滤器查询结果为不存在,则键值一定不存在;
- 布隆过滤器查询结果为存在,键值不一定存在(极小概率会误判);

布隆过滤器的底层主要是一个比较大的数组,里面存放的是 0 / 1,在一开始的时候都是 0,当一个 key 来之后,经过 3 次 hash 计算,模上数组长度找到数据的下标,然后把数组中原来的 0 改为 1(1 则还是 1),这样的话,数组的三个位置就能标明一个 key 是否存在;
当然,这里很明显的问题就是可能会出现误判,并且避免不了,我们一般可以控制这个误判率,数组越大,误判率就越小,性能也越差,最好就是 0.03 - 0.05 了,性能还算好一点,误差也是在接受范围内的,在实际业务可以大大降低 key 不存在而查 MySQL 的次数;
优点:内存占用小,没有多余的 key,布隆过滤器一般不会设置过期时间;
缺点:实现复杂,存在误判,删除不是很好删,可能会影响其他的数据;
如果出现误判,那么岂不是还是会出现缓存穿透?
是的,我觉得两种方法可以结合起来使用!
- 布隆过滤器查询结果:缓存存在(假设为误判结果);
- 查询 Redis,不存在;
- 查询 MySQL,不存在;
- 在 Redis 中设置值为 null 的 key(在布隆过滤器表示存在的时候,再设置这个 key,而不是每次表示不存在都设置 null);
- 下一次同样的请求;
- 布隆过滤器查询结果:缓存存在(假设为误判结果);
- 查询 Redis,结果为 null,返回 null;
同理,其实业务中删除了 Redis 的某个键,也没必要在布隆过滤器中删除,把之后的每一次都视作“误判”;
回答:
- 缓存穿透就是一个请求查询了一个不存在的数据,无命中 Redis 的缓存,直接访问 MySQL,如果大量的这样的请求,那么每次都会穿过 Redis 直接访问 MySQL,给 MySQL 较大的压力;
- 解决方案:
- 缓存 null 值;
- 布隆过滤器;
2.2 缓存击穿

缓存击穿:给某个 key 设置了过期时间,当 kye 过期的时候,恰好这个时间点对这个 key 有大量的并发请求过来,在 MySQL 读完并设置缓存这个间隙,MySQL 将瞬间收到大量的压力,甚至被搞垮;
解决方案:
- 互斥锁
- 强一致性,性能比较差;
- 逻辑过期
- 高可用性(允许特别小的一段时间的响应是过期数据),性能比较好;

回答:
- 缓存穿透就是给某个 key 设置了过期时间,当 kye 过期的时候,恰好这个时间点对这个 key 有大量的并发请求过来,在 MySQL 读完并设置缓存这个间隙,MySQL 将瞬间收到大量的压力,甚至被搞垮;
- 解决方案:
- 互斥锁,强一致,性能差;
- 逻辑过期,高可用,性能好,不能保证数据的绝对一致;
缓存穿透与缓存击穿的字面理解:
- 缓存穿透给我的感觉就像“洞”是本来就有的,大量的请求穿透过这个“洞”访问 MySQL,当然用缓存 null 值可以将洞堵上;
- 缓存击穿给我的感觉就是“洞”是突然出现的,强调其变化性,像被击穿了一样;当然,这里是 Redis 将过期键删除了,是 Redis 击穿的,但是感觉是被大量的并发请求冲出来个洞一样;
这里的“洞”指的是,某个 key 无命中 Redis 的缓存,直接穿过 Redis 访问 MySQL;
2.3 缓存雪崩
缓存雪崩:在同一段时间内,大量的缓存 key 同时失效或者 Redis 服务宕机,导致大量的请求直接数据库,带来巨大压力;
- 相较于缓存击穿,缓存雪崩更加严重,更加强调一下子出现很多的“洞”,或者 Redis 直接炸了,大量的不同的并发请求直接访问 MySQL;
解决方案:
- 给不同的 key 的 TTL 添加随机值(比如在原来的基础上延迟 1 - 5 分钟过期),尽可能错开过期时间;
- 利用 Redis 集群提高服务可用性(哨兵模式、集群模式);
- 保底策略: 给业务添加降级限流策略(nginx、spring cloud 的 gateway 网关);
- 这个策略适用于缓存穿透、缓存击穿、缓存雪崩;
- 给业务添加多级缓存(Guava 或 Caffeine)
一首打油诗,当作看了个乐就行🤣:

3. Redis 作为缓存,MySQL 的数据如何与 Redis 进行同步,也就是如何保证双写一致性的?
一定要先介绍自己的哪些业务背景维护了双写一致,或者可以去维护双写一致。

双写一致性:当修改了数据库的数据也要同时更新缓存的数据,保证缓存和数据库的数据要保持一致;
我们可能会想,更新的时候把缓存删了不就好了,那么我们是先更新后删除缓存,还是先删除缓存再更新数据库?
- 其实都是有问题的;

况且,对于 Redis 集群,主从库同步也需要时间,这个问题也会被扩大;
分为两个思路:
- 允许延迟一致
- 延迟双删;
- 一致性要求高
- Redis 读写锁;
3.1 延迟双删
-
读数据操作:缓存命中则返回,缓存未命中则查询数据库,写入缓存,设定超时时间;
-
写数据操作:

- 期间是可能出现脏数据的;
延时多久不太好确定,延时删除可以通过定时器任务、消息中间件异步通知删除等方式去实现;
3.2 Redis 读写锁
一般缓存的数据应该是**读多写少**,这样的数据才值得缓存,读多写少的场景下用读写锁可以尽可能的保持性能不会太差;
读写锁:
- 读锁:又称共享锁,别的线程读的话不阻塞,写的话则阻塞等待;
- 写锁:又称排他锁,别的线程读写都得阻塞等待;

用读写锁解决问题:

代码实例:

回答(示例):

- 如果业务允许延时一致,可以采用延时双删的策略,即先删除,再修改数据库,延时一段时间再删除一次,可以用计时器任务、消息中间件(例如 MQ),异步通知删除;
- 如果业务要求强一致性,可以采用读写锁保证双写一致性(共享锁:readLock,排他锁:writeLock)
4. Redis 作为缓存,数据的持久化是怎么做的?
- RDB;
- AOF;
4.1 RDB
RDB 全称 Redis Database Backup file(Redis 数据库备份文件,有压缩),也称为 Redis 数据快照。也就是把 Redis 内存中的所有数据都记录到磁盘中,当 Redis 实例故障重启,从磁盘中读取快照文件,恢复数据;

RDB 的执行原理:
- 由于 save 无非就是阻塞所有命令,把内存中的数据保存到 RDB 文件中,这种不可取;
- 而主要还是 bgsave 的执行原理:

4.2 AOF
AOF 全称 Append Only File(追加文件)。Redis 处理的每一个“写”命令都会记录在 AOF 文件,可以看做是命令日志/重做日志;

需要通过 redis.conf 来配置:

AOF 的执行频率策略:
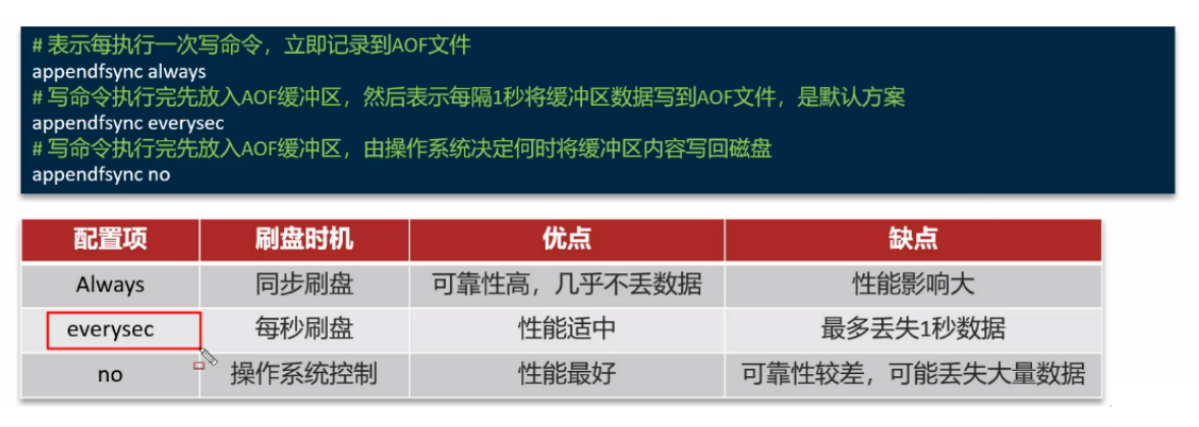
因为是记录命令,没有压缩,AOF 文件会比 RDB 文件大很多,而且 AOF 会记录对同一个 key 的多次写操作,但是可能最后一次写操作有效,我们可以通过 bgrewriteaof 命令(bg rewrite aof),可以让 AOF 文件执行重写操作,减少最少命令达到相同效果;

可以通过 redis.conf 配置触发自动重写的阈值:

4.3 RDB 与 AOF 对比

5. Redis 的 key 过期之后,会立即删除吗?
可能不会立即删除,要看 Redis 的数据过期策略;
-
Redis 对数据设置过期时间
-
set name macaku 10- 1
-
数据过期之后,就需要将数据从内存中删除,可以按照不同的规则进行删除,这种删除规则就是 Redis 的数据过期策略;
有两种:
- 惰性删除;
- 定期删除;
Redis 采用的是 惰性 + 定期;
- 勉强算第三种吧;
5.1 惰性删除
惰性删除:设置该 key 过期时间后,我们不去管它,当需要该 key 时,我们检查是否过期,如果过期,我们就删掉;

优点: 对 CPU 友好,只会在使用该 key 的时候进行删除,对于很多用不到的 key 就不用浪费时间删除了;
缺点: 对内存不友好,如果一个 key 已经过期,长期不用,就滞留在内存里不会被释放了;
5.2 定时删除
定时删除:每隔一段时间,我们就从 Redis 取出一定量的随机 key 进行检查,并删除其中过期的 key;
定期删除有两种模式:
- SLOW 模式是定时任务,执行频率默认是 10hz(每秒10次),每次不超过 25ms,以通过修改配置文件 redis.conf 和 hz 选项来调整这个次数;
- FAST 模式执行频率不限制,但限制两次间隔不低于 2ms,每次耗时不超过 1ms;
每次的删除程度,例如:
- 从过期字典中随机取出20个键
- 删除这20个键中过期得键
- 如果过期键的比例超过25%,重复此过程
(由于有时间限制,所以不会循环太多次,可能最终没达到 25%,不过没啥大碍,交给下次咯)
可以自己去配;
优点: 可以通过限制删除操作执行的时长和频率来避免一次性删除/删除的数据量太大对 CPU 的影响,另外定期删除,也能有效释放过期键占用的内存,避免过期数据滞留在内存里;
缺点: 难以确定删除操作执行的时长和频率,“没有轮到删除”的过期数据可能被访问到;
所以混搭组合技才是王道,当访问到定时删除下还没删除的数据,判断其为过期数据则删除;
回答:
- 惰性删除:设置该 key 过期时间后,我们不去管它,当需要该 key 时,我们检查是否过期,如果过期,我们就删掉;
- 定时删除:每隔一段时间,我们就从 Redis 取出一定量的随机 key 进行检查,并删除其中过期的 key;
- Redis 的过期删除策略:惰性删除 + 定期删除 两种策略进行配合使用;
6. 加入缓存过多,内存是有限的,内存被占满了怎么办?(数据淘汰策略是什么?)
6.1 内存淘汰策略
早期版本的Redis有以下六种内存淘汰策略:
- 报错
- noeviction,不驱赶数据,即不淘汰任何数据,内存不足就报错,默认
- 最久未用 LRU
- allkeys-lru,淘汰所有键值中最久未使用的键值
- volatile-lru,淘汰所有设置了过期时间的键值中最久未使用的键值
- 随机
- allkeys-random,随机淘汰所有键值中的任意键值
- volatile-random,随机淘汰所有设置了过期时间的键值中的任意键值
- 最先过期
- volatile-ttl,优先淘汰最先过期的键值
在Redis 4.0版本中又新增了两种淘汰策略:
- 最少使用 LFU
- allkeys-lfu,淘汰所有键值中最少使用的键值
- volatile-lfu,淘汰所有设置了过期时间的键值中,最少使用的键值
6.2 LRU和LFU有什么区别
侧重点不同
- LRU,Least Recently Used,最近最少使用,是基于时间的策略,理念为:最近被访问过的键值就可能再次被访问,因此应该淘汰最久未被访问的键值;LRU策略会维护一个访问顺序列表
- 每当一个键被访问的时候,它会被移动到列表的末尾,最近没有被访问的键值的位置会比较靠前,所以会被优先淘汰
- 关注键的访问顺序
- LFU,Least Frequently Used,最不常使用,是基于频率的策略,理念为:它认为被访问次数最少的键值最不常用,更不重要,因此在淘汰时会优先选择访问次数最少的键值;LFU策略会维护一个访问计数器
- 每当一个键被访问时,此计数器会增加,LFU策略会选择访问计数最低的键进行淘汰
- 关注键的访问频率
6.3 过期淘汰策略和内存淘汰策略有何不同
- 内存淘汰策略:解决Redis运行内存过大的问题;
- 过期淘汰策略:主要是为了删除过期数据的问题;
6.4 策略选择的建议
- 优先使用 allkeys-lru 策略。充分利用 LRU 算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的冷热数据区分,建议使用。
- 如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用 allkeys-random,随机选择淘汰,这样性能高。
- 如果业务中有置顶的需求,可以使用 volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据。
- 如果业务中有短时高频访问的数据,可以使用 allkeys-lfu 或 volatile-lfu 策略。
6.5 补充
Redis 的内存用完了会发生什么?
- 主要看数据淘汰策略是什么?如果是默认的配置(noeviction,不驱赶/不淘汰数据),会直接报错;
数据库有 1000w 数据,Redis 只能缓存 20w 数据,如何保证 Redis 中的数据都是热点数据?
- 也就是问,超额的数据 Redis 怎么缓存 => 数据淘汰策略 => 数据淘汰策略的选择;
- 使用 allkeys-lru ,留下来的都是经常访问的热点数据;
6.6 总结重点
- Redis 提供了 8 种不同的数据淘汰策略,默认是 noeviction 不淘汰,内存不足则直接报错;
- 其中,LRU:最久未用,以时间为衡量标准,用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高;LFU:最少使用,以频率为衡量标准,会统计每个 key 的访问频率,值越小淘汰优先级越高;
- 平时开发过程中用的比较多的是 allkeys-lru(结合自己的业务场景去说)
-
相关阅读:
张量的连续性、contiguous函数
1030:计算球的体积
软考2020高级架构师下午案例分析第4题:关于Redis数据类型、持久化、内存淘汰机制
【译】摇摆你的调试游戏:你需要知道的 Parallel Stack Window 小知识!
R语言ggplot2可视化:使用ggplot2可视化散点图、使用scale_color_viridis_d函数指定数据点的配色方案
正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-1.3
测试岗面试,一份好的简历总可以让人眼前一亮
GateWay实现负载均衡
二叉搜索树、红黑树详解、红黑树高的应用、TreeMap的应用(图文详解)-Kotlin版本代码
小文智能GPT助手介绍
- 原文地址:https://blog.csdn.net/Carefree_State/article/details/136492271