-
【RabbitMQ】WorkQueue

📝个人主页:五敷有你
🔥系列专栏:MQ
⛺️稳中求进,晒太阳

Work Queues
Work queues任务模型,简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息

当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高了。
消息发送
这次我们循环发送,模拟大量消息堆积现象。
在publisher服务中的SpringAmqpTest类中添加一个测试方法:
- @Autowired
- private RabbitTemplate rabbitTemplate;
- @Test
- void testSendMessage2Queue() throws InterruptedException {
- String queueName1 = "work.queue";
- for(int i=0;i<50;i++){
- String msg = "Hello Work.Queue 编号:"+i;
- rabbitTemplate.convertAndSend(queueName1, msg);
- Thread.sleep(20);
- }
- }
消息接收
要模拟多个消费者绑定同一个队列,我们在consumer服务的SpringRabbitListener中添加2个新的方法
- @RabbitListener(queues = "work.queue")
- public void listenWorkQueue1(String msg) throws InterruptedException {
- System.out.println("消费者1收到了work.queue的消息:【" + msg +"】");
- Thread.sleep(5);
- }
- @RabbitListener(queues = "work.queue")
- public void listenWorkQueue2(String msg) throws InterruptedException {
- System.err.println("消费者1收到了work.queue的消息:【" + msg +"】");
- Thread.sleep(50);
- }
注意到这两消费者,都设置了Thead.sleep,模拟任务耗时:
- 消费者1 sleep了5毫秒,相当于每秒钟处理200个消息
- 消费者2 sleep了50毫秒,相当于每秒处理20个消息

消息是平均分配给每个消费者,并没有考虑到消费者的处理能力。导致1个消费者空闲,另一个消费者忙的不可开交。没有充分利用每一个消费者的能力,最终消息处理的耗时远远超过了1秒。这样显然是有问题的。
能者多劳
- spring:
- rabbitmq:
- listener:
- simple:
- prefetch: 1 # 每次只能获取一条消息,处理完成才能获取下一个消息
再次测试,发现结果如下:.
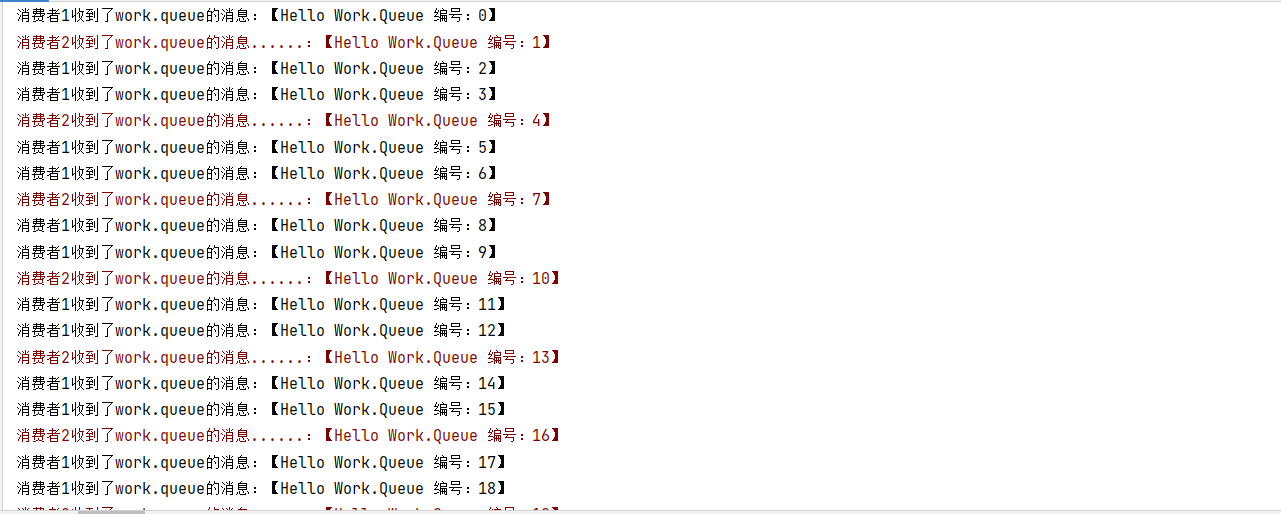
可以发现,由于消费者1处理速度较快,所以处理了更多的消息;消费者2处理速度较慢,只处理了6条消息。而最终总的执行耗时也在1秒左右,大大提升。
正所谓能者多劳,这样充分利用了每一个消费者的处理能力,可以有效避免消息积压问题。
总结
Work模型的使用:
- 多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预取的消息数量
-
相关阅读:
FREERTOS内容解惑与综合应用(基于STM32F103)
MATLAB | 如何绘制二维散点主方向直方图
Oracle Audit Vault部署
深入理解Prompt Engineering:Transformers与OpenAI的实践启示
记一次.net加密神器 Eazfuscator.NET 2023.2 最新版 使用尝试
(Python高级编程)第一章:Python面向对象深刻认识
【网络安全】「漏洞原理」(二)SQL 注入漏洞之理论讲解
【Tools】i1Profiler1.7安装教程详解
Kotlin高仿微信-第3篇-主页
leetcode题刷250天(87)——654. 最大二叉树(DFS)
- 原文地址:https://blog.csdn.net/m0_62645012/article/details/136547299