-
机器学习中的基础问题总结
介绍:总结面试经常问到的一些机器学习知识点(必会🌟)
模型评估
tips:准确率(A)、精确率(P)、召回率(R)、均方根误差、F1 score1、准确率:分类正确的样本占总样本个数的比例
局限:当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率低最主要因素。2、精确率:分类正确的正样本个数占分类器判定为正样本的样本个数的比例
Precision P = TP/(TP + FP)
3、召回率:分类正确的正样本个数占真正的样本个数的比例
Recall R = TP/(TP+FN)
4、F1 score:精准率和召回率低调和平均值
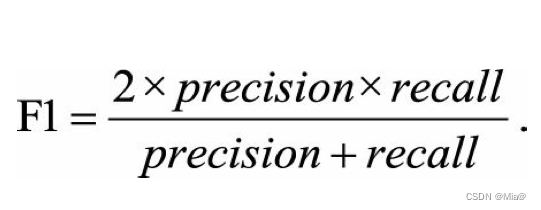
tips:ROC曲线、P-R曲线、AUC(曲线下的面积)ROC:当正负样本发生变化时,ROC形状基本不变,P-R曲线形状发生剧烈变化
AUC:表示预测的正例排在负例前面的概率 P-R曲线:比面积
提示:以下是本篇文章正文内容,下面案例可供参考一、L1、L2正则化
- y = wx + b(w决定模型曲线,b决定模型平移情况)
L1、L2正则化是针对w(权重)的正则化
L1、L2指的是范数1、L1正则与L2正则有何不同?
- L1是模型各个参数的绝对值之和,L2是各个参数平方和的开方
- L1:产生少量的特征,其他特征为0,最优的参数值大概率出现在坐标轴,进而导致产生稀疏的权重矩阵,
L2:选择更多的矩阵,这些矩阵趋向于0
2、为什么正则化可以防止过拟合?
通过为模型加一个正则化项可以防止过拟合
数学角度:
参数量角度:由于模型复杂度与参数个数正相关,令一些参数为0后,模型复杂度降低,进而可以防止过拟合3、为什么L1正则具有稀疏性?(为什么L1正则可以特征选择?)
从以下三个角度进行说明:
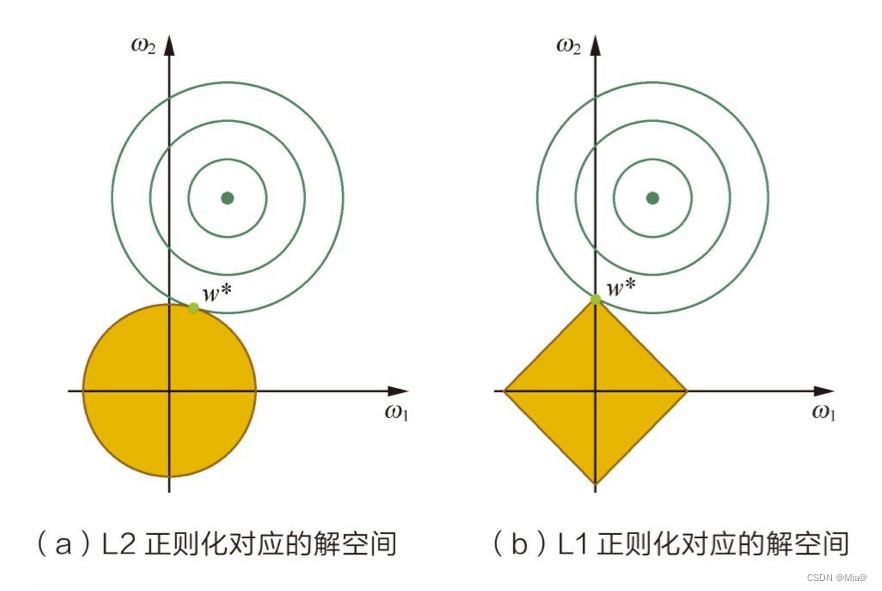
解空间形状带正则项等价于带约束条件,L2正则化相当于为参数定义了一个圆形的解空间,L1正则化相当于定义了一个圆形解空间,若原问题的最优解不在解空间内,“棱角分明”的L1解空间更容易与目标函数在角点相碰,从而产生稀疏解。
贝叶斯先验L1正则化相当于对参数w引入了拉普拉斯先验,L2正则化相当于引入了高斯先验,拉普拉斯先验使参数为0的可能性更大
二、损失函数
用来量化模型预测和真实标签之间的差异
常见损失函数
平方损失(预测问题)、交叉熵损失(分类问题)、hinge损失(SVM)、残差损失(CART回归树)
交叉熵
三、过拟合与欠拟合
过拟合:模型在训练数据上表现良好但在未见过的测试数据上表现不佳。【常发生在模型过于复杂或训练数据过少时】
欠拟合:模型无法在训练数据上学习到足够的信息,导致无法很好的拟合数据。【常发生在模型过于简单或者训练数据过于复杂时】1、如何降低过拟合
- 增加训练数据量 (数据增广)
- 使用正则化(L1、L2)
【L1产生更少的特征向量,其他特征的权值为0;L2选择更多的特征,每个特征权值都比较小】 - 简化模型结构,减少模型复杂度
- 在过拟合前提前结束训练
- Dropout(神经网络)
- 使用交叉验证等技术来评估模型等泛化能力
2、如何降低欠拟合
- 增加模型复杂度(增加模型的层数或参数数量)
- 对数据进行特征工程,提取更多的有效特征
- 减少(或移除)正则化的程度
- 增加训练时间,让模型有更多机会学习数据的规律
四、梯度爆炸和梯度消失
- 梯度消失成因:一是在深层网络中;二是采用了不适合的损失函数(如Sigmoid)
- 梯度爆炸一般出现在深层网络和权值初始化太大的情况下
解决方法
1、使用relu等激活函数,使得导数一直为1
2、残差结构
3、LSTM
4、 batchnorm:反向传播式子中有x xx的存在,所以x的大小影响了梯度的消失和爆炸,batchnorm就是通过对每一层的输出规范为均值和方差一致的方法,消除了x带来的放大缩小的影响五、激活函数
1.引入库
2.读入数据
优化算法
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。传统的机器学习模型
1、回归算法
LR(分类) 与线性回归(预测)
线性回归使用最小二乘法计算参数,LR用最大似然估计
线性回归更容易受到异常值的影响,LR、更稳定
2、决策树学习决策树根据问题属性采用树状结构建立决策模型,用于解决分类和回归问题
3、聚类算法(K-Means)
按照中心点或分层的方式对数据进行归并,试图找到数据结构的内在结构以便按照最大的共同点将数据进行归类
4、人工神经网络
是一种模式匹配算法,用于解决分类和回归问题。
5、集成算法(Boosting、Bootstrapped Aggregation(Bagging)、AdaBoost、随机森林)
用一些相对较弱的模型独立的对同样的样本进行训练,然后把结果整合起来进行整体预测。
6、基于核的算法(如SVM)
把输入数据映射到一个高阶的向量空间,进而解决在低阶向量空间无法解决的分类问题。
7、关联规则
通过寻找最能解释数据变量之间关系的规则,找出大量多元数据集中有用的关联规则
8、贝叶斯方法(朴素贝叶斯)
用于解决分类和回归。
9、降维算法(PCA、PLS、MDS)
以非监督学习的方式,试图用较少的信息解释或归纳数据。【有点像聚类】
10、基于实例的算法
-
相关阅读:
Nginx内存池:内存分配方案 | 小块内存分配方案
Java项目:ssm酒店管理系统
Unity SteamVR 开发教程:SteamVR Input 输入系统(2.x 以上版本)
gcc-linaro-7.5.0-2019.12-x86_64_aarch64-linux-gnu交叉编译Arm Linux环境下的身份证读卡器so库操作步骤
Blender批量修改名称
鸿蒙登录页面及页面跳转的设计
科技资讯杂志 科技资讯杂志社科技资讯编辑部2022年第17期目录
硬件开发笔记(二十一):外部搜索不到的元器件封装可尝试使用AD21软件的“ManufacturerPart Search”功能
集群创建(flannel)时候,没有自动创建出cni0网卡
包装类与数据类型
- 原文地址:https://blog.csdn.net/weixin_43008312/article/details/136607945