-
stable diffusion的额外信息融入方式
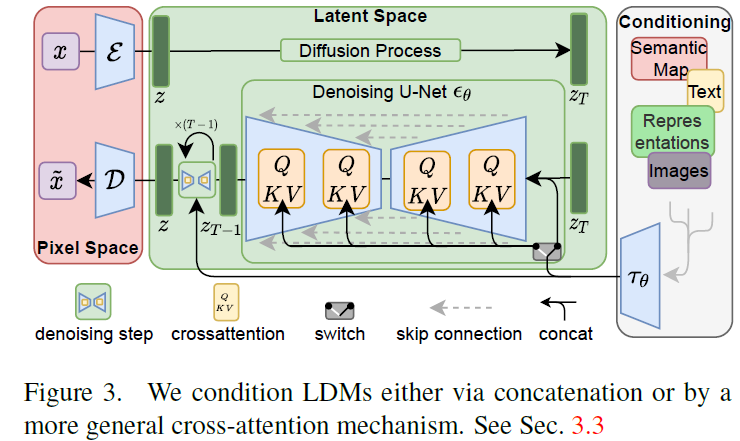

conditioning怎么往sd中添加,一般有三种,一种是直接和latent拼一下,另外很多是在unet结构Spatialtransformers上加,和文本特征一样,通过cross-attention往unet上加,这里还需要注意一点,在文本嵌入时,q是可学习的,k和v都是文本embedding。第三种就是类似controlnet这种,adapter设计。
1.sd img2img
sd的img2img的图像输入是通过VAE将图像转成image latent和latent一起拼的,将512x512的图转成64x64.
- init_latent = sd_model.get_first_stage_encoding(sd_model.encode_first_stage(image))
- image_conditioning = img2img_image_conditioning(image, init_latent, image_mask)
1.ip-adapter

通过解耦cross-attention的方式,clip提取图像特征,文本输入一个crossattention,图像输入一个cross-attention。
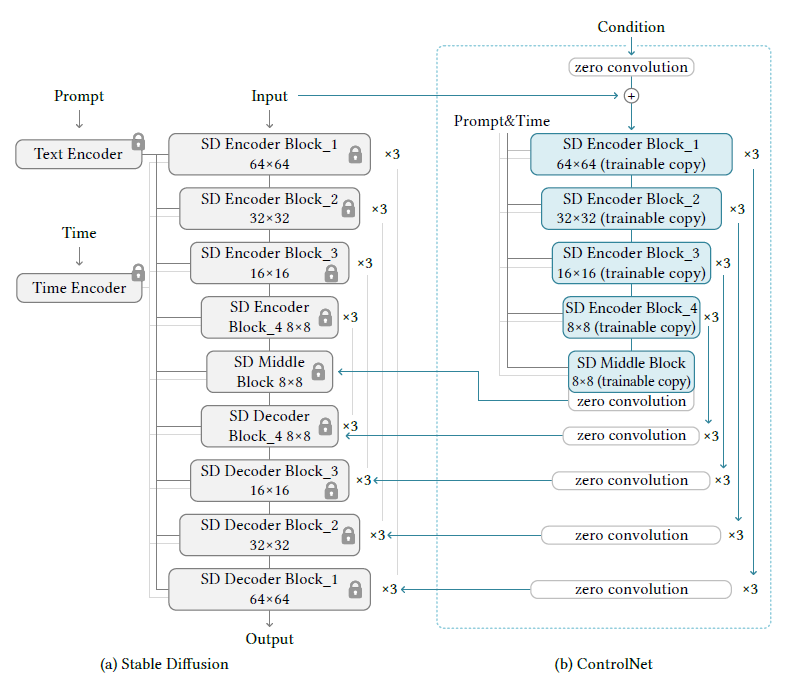
3.controlnet
stable diffusion使用和vq-gan相似的预处理方法,将512x512图像转成64x64的潜在图像,controlnet将image-based condition(就是从图像中获取线框图)转成64x64,我们使用4个4x4核和2x2strides的卷积层(后接relu,通常数分别是16,32,64,128,Guassian weights)将image-space condition转成特征图。
4.powerpaint
输入由latent+masked_image+mask concat组合,text侧还是clip编码之后送入unet进行cross-attention。

5.VideoComposer

-
相关阅读:
前端八股文-类型判断typeof,instanceof,类式,构造函数,组合,原型式,寄生式继承,手写new、bind、call、apply
事件派发触发以及自定义事件派发dispatchEvent-——————派发键盘事件
实验四:面向对象编程实验(2)—封装、继承和包
Linux——指令初识(二)
【Shiro】SpringBoot集成Shiro权限认证《上》
[附源码]计算机毕业设计springboot旅游度假村管理系统
超详细的商业智能BI知识分享,值得收藏
使用 PyQT 和 Qt 设计器进行 Python GUI 开发
Qt6远程连接MySQL数据库(简单易上手版)
【JavaSE】基础语法知识汇总
- 原文地址:https://blog.csdn.net/u012193416/article/details/136501420