-
b站小土堆pytorch学习记录—— P18-P22 神经网络+小实战
理解神经网络:
一、卷积层 P18
1.卷积操作
推荐几个高赞博客:
卷积最容易理解的解释
卷积神经网络(CNN)详细介绍及其原理详解
还有pytorch官网的动态图:
pytorch卷积具体而言,假设有一个3X3的灰度图像矩阵:
[1, 1, 1] [0, 0, 0] [1, 1, 1]- 1
- 2
- 3
我们使用一个称为边缘检测的卷积核(滤波器):
[-1, -1, -1] [-1, 8, -1] [-1, -1, -1]- 1
- 2
- 3
接下来,我们将对这个3x3图像矩阵应用卷积操作。
步骤如下:
(1)将3x3的卷积核与图像的左上角3x3区域进行逐元素相乘,并将结果相加,得到新的像素值。
(2)滑动卷积核到下一个位置,再次进行相乘相加操作,得到另一个像素值。
(3)重复此过程直到覆盖整个图像。
应用以上步骤后,我们可以得到一个新的图像矩阵,其中包含了经过边缘检测卷积核处理后的结果。这种操作有助于检测图像中的边缘和轮廓。具体计算如下:
第一步,将卷积核与图像的左上角3x3区域进行逐元素相乘,并将结果相加,得到新的像素值:
1*(-1) + 1*(-1) + 1*(-1) + 0*(-1) + 0*8 + 0*(-1) + 1*(-1) + 1*(-1) + 1*(-1) = -3- 1
- 2
- 3
第二步,滑动卷积核到下一个位置,再次进行相乘相加操作,得到另一个像素值:
1*(-1) + 1*(-1) + 0*(-1) + 0*(-1) + 0*8 + 1*(-1) + 1*(-1) + 1*(-1) + 0*(-1) = -5- 1
- 2
- 3
以此类推,重复步骤直到覆盖整个图像。在这个例子中,我们得到了一个2x2的新图像矩阵,其像素值为-3和-5。
所以,经过边缘检测卷积核处理后的结果是:
[-3, -5] [ 0, 0]- 1
- 2
2.代码
import torch import torchvision from torch import nn from torch.nn import Conv2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter # 下载CIFAR10数据集并准备数据加载器 dataset = torchvision.datasets.CIFAR10("./dataset2", train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=64) # 定义一个简单的神经网络模型 class Guodong(nn.Module): def __init__(self): super(Guodong, self).__init__() # 定义一个卷积层 self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) def forward(self, x): x = self.conv1(x) return x guodong = Guodong() print(guodong) # 初始化TensorBoard的SummaryWriter writer = SummaryWriter("logs") step = 0 # 遍历数据加载器,处理数据并将结果写入TensorBoard for data in dataloader: imgs, target = data print(imgs.shape) # 打印输入图片的形状 output = guodong(imgs) # 将输入图片传入神经网络模型得到输出 print(output.shape) # 打印输出的形状 writer.add_images("input", imgs, step) # 将输入图片写入TensorBoard output = torch.reshape(output, (-1, 3, 30, 30)) # 调整输出的形状以便写入TensorBoard writer.add_images("output", output, step) # 将输出图片写入TensorBoard step = step + 1 # 更新步数- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
程序运行结果:
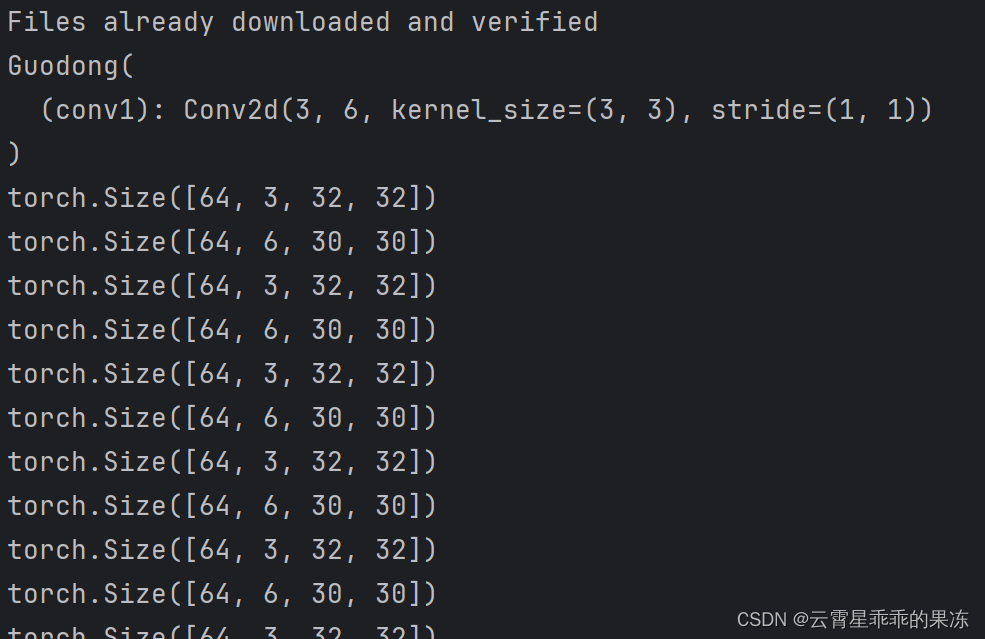
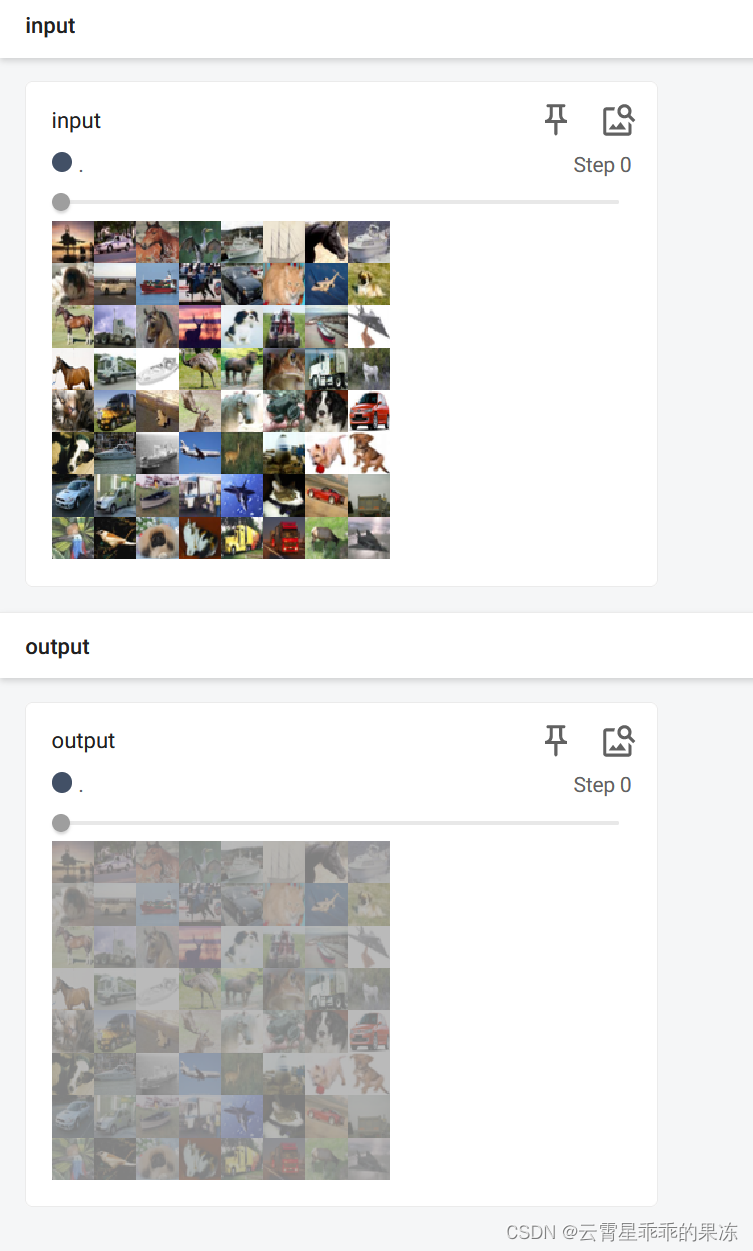
打开tensorboard后,结果如下:
二、池化层 P19
1.池化层简单介绍
池化层(Pooling Layer)是深度学习中常用的一种层,通常用于减少特征图的空间尺寸,降低计算复杂度,并且有助于防止过拟合。池化层在卷积神经网络(CNN)中被广泛应用。
池化层的作用是通过对输入数据进行池化操作来减少特征图的尺寸,从而减少网络参数和计算量。池化操作通常在每个独立的特征图上进行,它使用一个固定大小的窗口在特征图上滑动,并在窗口内部执行一个汇聚运算(如最大池化、平均池化等)来得到一个汇聚后的值作为输出。
常见的池化操作:
最大池化(Max Pooling):在池化窗口内取最大值作为汇聚后的值。
平均池化(Average Pooling):在池化窗口内取平均值作为汇聚后的值。
全局平均池化(Global Average Pooling):对整个特征图进行平均池化,将每个通道的特征图转换为一个标量值。池化层的主要优点:
减少特征图的维度,降低计算复杂度。
增加平移不变性,提高模型的鲁棒性。
减少过拟合,通过减少特征图维度,可以减少模型参数的数量。2.代码
(1)池化操作中数字的变化
import torch from torch import nn from torch.nn import MaxPool2d # 创建输入张量 input = torch.tensor([[1, 2, 0, 3, 1], [0, 1, 2, 3, 1], [1, 2, 1, 0, 0], [5, 2, 3, 1, 1], [2, 1, 0, 1, 1]], dtype=torch.float32) # 将输入张量reshape为(batch_size, channels, height, width) input = torch.reshape(input, (-1, 1, 5, 5)) # 定义第一个神经网络模型Guodong1,使用MaxPool2d进行最大池化操作,ceil_mode=True class Guodong1(nn.Module): def __init__(self): super(Guodong1, self).__init__() self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True) # 定义最大池化层,kernel_size为3,启用ceil_mode def forward(self, input): output = self.maxpool1(input) return output # 创建Guodong1模型实例并进行前向传播 guodong1 = Guodong1() output1 = guodong1(input) print("Output of Guodong1 with ceil_mode=True:") print(output1) # 定义第二个神经网络模型Guodong2,使用MaxPool2d进行最大池化操作,ceil_mode=False class Guodong2(nn.Module): def __init__(self): super(Guodong2, self).__init__() self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False) # 定义最大池化层,kernel_size为3,不启用ceil_mode def forward(self, input): output = self.maxpool1(input) return output # 创建Guodong2模型实例并进行前向传播 guodong2 = Guodong2() output2 = guodong2(input) print("\nOutput of Guodong2 with ceil_mode=False:") print(output2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
运行结果:

(2)池化操作对图片的影响
from torch import nn import torchvision from torch.nn import MaxPool2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter # 加载CIFAR10数据集 dataset = torchvision.datasets.CIFAR10("./dataset1", train=False, transform=torchvision.transforms.ToTensor(), download=True) # 创建数据加载器 dataloader = DataLoader(dataset, batch_size=64) # 定义神经网络模型Guodong,使用MaxPool2d进行最大池化操作,ceil_mode=True class Guodong(nn.Module): def __init__(self): super(Guodong, self).__init__() self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True) # 定义最大池化层,kernel_size为3,启用ceil_mode def forward(self, input): output = self.maxpool1(input) return output guodong = Guodong() # 创建TensorBoard的SummaryWriter实例 writer = SummaryWriter("./logs_maxpool") step = 0 # 遍历数据加载器,将输入图像和模型输出图像添加到TensorBoard中 for data in dataloader: imgs, target = data writer.add_images("input", imgs, step) # 将输入图像添加到TensorBoard output = guodong(imgs) # 通过模型前向传播得到输出 writer.add_images("output", output, step) # 将模型输出的图像添加到TensorBoard step = step + 1 writer.close() # 关闭SummaryWriter- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
运行结果:

可以看到,最后的结果就像给图片打了 “马赛克”三、非线性激活 P20
1.简要介绍
非线性激活函数是神经网络中用于引入非线性特性的函数。在神经网络中,每个神经元除了具有权重和偏置之外,还需要一个激活函数来引入非线性变换,从而使神经网络能够学习复杂的模式和关系。
在深度学习中,使用非线性激活函数的主要原因是为了让神经网络具备学习和表示更加复杂的函数的能力,从而提高模型的表达能力。如果没有非线性激活函数,多层神经网络就会退化为单层网络,无法表达复杂的非线性关系,限制了神经网络的表达能力和学习能力。
常见的非线性激活函数:
ReLU(Rectified Linear Unit):ReLU函数定义为f(x) = max(0, x),即将小于等于0的输入映射为0,大于0的输入保持不变。ReLU函数简单且计算高效,在实际应用中被广泛使用。
Sigmoid函数:Sigmoid函数定义为f(x) = 1 / (1 + exp(-x)),它将输入值映射到一个取值范围在[0, 1]之间的输出。Sigmoid函数常用于二分类问题或者需要将输出限制在一定范围内的任务。
Tanh函数:Tanh函数定义为f(x) = (exp(x) - exp(-x)) / (exp(x) + exp(-x)),它将输入值映射到一个取值范围在[-1, 1]之间的输出。Tanh函数在某些情况下比Sigmoid函数更适合使用,尤其是在中心化数据和对称性数据上。
Leaky ReLU:Leaky ReLU函数是对ReLU函数的改进,当输入小于0时,引入一个小的斜率来避免神经元“死亡”的问题。Leaky ReLU函数定义为f(x) = max(ax, x),其中a是一个小的正数。
ELU(Exponential Linear Unit):ELU函数在负数区域对输入进行指数级衰减,而在正数区域保持线性增长。ELU函数定义为f(x) = max(ax, x)(x >= 0)和f(x) = a * (exp(x) - 1)(x < 0),其中a是一个小的正数。
Softmax函数:Softmax函数常用于多分类问题中,将一组实数值映射到概率分布上,使得所有输出的总和等于1。Softmax函数定义为f(x_i) = exp(x_i) / sum(exp(x_j))。
2.代码
import torch import torchvision from torch import nn from torch.nn import ReLU, Sigmoid from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter # 创建输入张量并reshape为(batch_size, channels, height, width) input = torch.tensor([[1, 0.5], [-1, 3]]) input = torch.reshape(input, (-1, 1, 2, 2)) print(input.shape) # 加载CIFAR10数据集 dataset = torchvision.datasets.CIFAR10("./dataset1", train=False, download=True, transform=torchvision.transforms.ToTensor()) dataloader = DataLoader(dataset, batch_size=64) # 定义神经网络模型Guodong,包含ReLU和Sigmoid激活函数 class Guodong(nn.Module): def __init__(self): super(Guodong, self).__init__() self.relu1 = ReLU() # 定义ReLU激活函数 self.sigmoid1 = Sigmoid() # 定义Sigmoid激活函数 def forward(self, input): output = self.sigmoid1(input) # 将输入数据经过Sigmoid激活函数得到输出 return output guodong = Guodong() output = guodong(input) print(output) # 使用SummaryWriter创建TensorBoard日志 step = 0 writer = SummaryWriter("logs") for data in dataloader: imgs, target = data writer.add_images("input", imgs, step) # 将输入图像添加到TensorBoard output = guodong(imgs) # 通过模型前向传播得到输出 writer.add_images("output", output, step) # 将模型输出的图像添加到TensorBoard step += 1 writer.close() # 关闭SummaryWriter- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
代码运行结果:
四、线性层及其他层介绍 P21
1.线性层

2.代码
import torch import torchvision from torch import nn from torch.nn import Linear from torch.utils.data import DataLoader # 下载并加载 CIFAR10 数据集 dataset = torchvision.datasets.CIFAR10("./dataset1", train=False, transform=torchvision.transforms.ToTensor(), download=True) # 创建数据加载器 dataloader = DataLoader(dataset, batch_size=64) # 定义自定义模型 Guodong class Guodong(nn.Module): def __init__(self): super(Guodong, self).__init__() self.linear1 = Linear(196608, 10) # 线性层,将输入维度为 196608 转换为输出维度为 10 def forward(self, input): output = self.linear1(input) return output # 创建 Guodong 模型的实例 guodong = Guodong() # 遍历数据加载器 for data in dataloader: imgs, target = data # 打印图像张量的形状 print(imgs.shape) # 将图像展平为一维向量 output = torch.flatten(imgs) print(output.shape) # 将展平后的向量输入到 Guodong 模型中进行前向传播 output = guodong(output) print(output.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
五、搭建小实战和Sequential的使用 P22
1.要实现的模型
CIFAR10 结构:
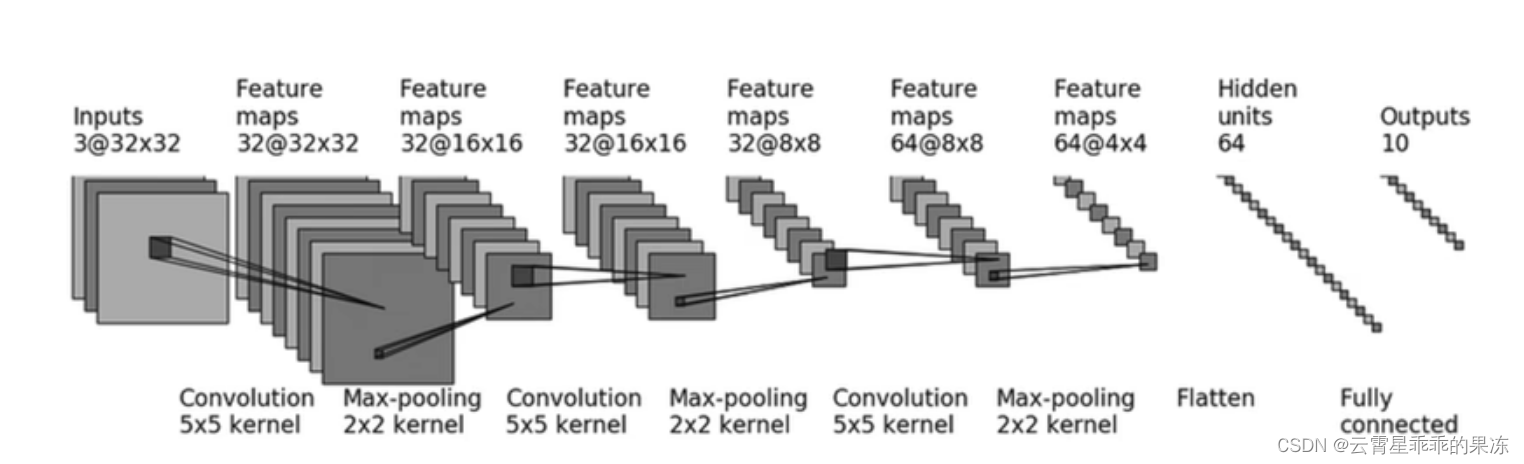
2.代码
import torch from torch import nn from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential from torch.utils.tensorboard import SummaryWriter class Guodong(nn.Module): def __init__(self): super(Guodong,self).__init__() self.module1 = Sequential( Conv2d(3, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 64, 5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self,input): output = self.module1(input) return output guodong = Guodong() input = torch.ones((64, 3, 32, 32)) print(input.shape) output = guodong(input) print(output.shape) writer = SummaryWriter("../seq_logs") writer.add_graph(guodong, input) writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
个人运行在tensorboard中显示异常,如下图,目前还不知道具体原因。
如果有大佬知道,可以在评论区指导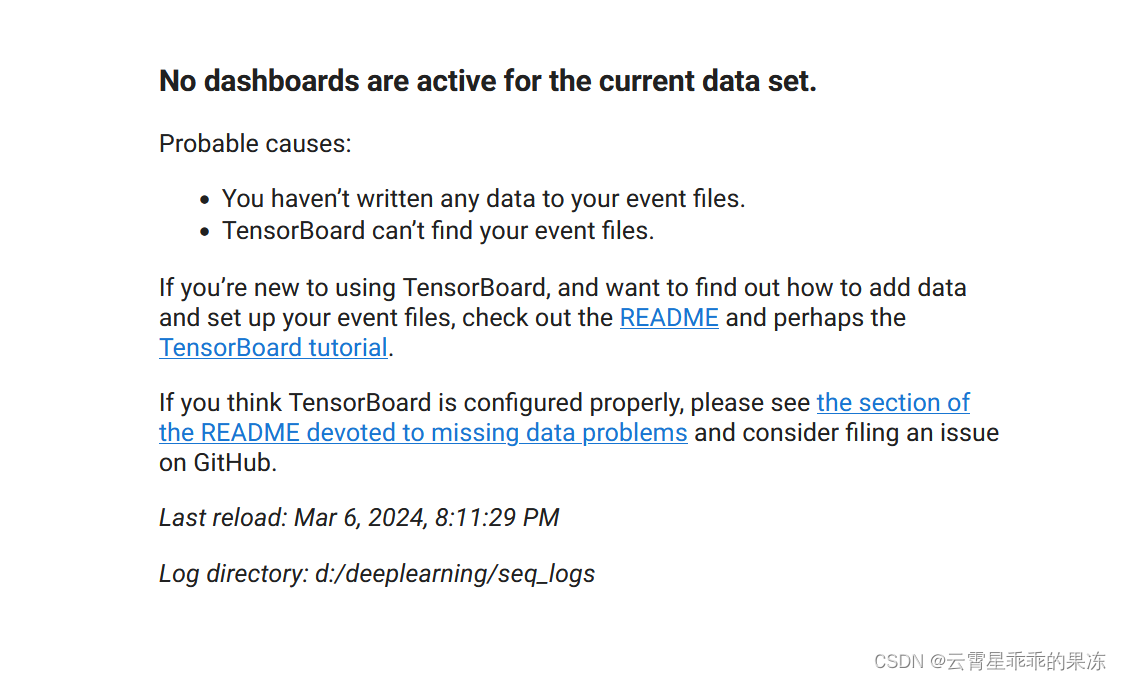
-
相关阅读:
《探索Stable Diffusion:AI绘画的创意之路与实战秘籍》
Unity ILRuntime热更新开发原则与接口如何绑定
GraphQL全面深度讲解
查看apk是否签名成功
Linux常用命令
ESP32C3 PWM输出
[译] kubernetes:kube-scheduler 调度器代码结构概述
echarts三柱图叠加三柱图解法
DECLARE_DYNAMIC提示缺少显示类型指定
生成带干扰线的验证码
- 原文地址:https://blog.csdn.net/qq_39991776/article/details/136464261
