-
缺陷检测:PatchCore的代码解读
前言

该文章发表在2022的CVPR上,用于缺陷检测,继承自SPADE,背后的关键原理为:测试样本与训练样本之间进行特征匹配,将不匹配的点识别出来。该文章探究了深度特征的多尺度性质。
作者的汇报视频:
Youtube1
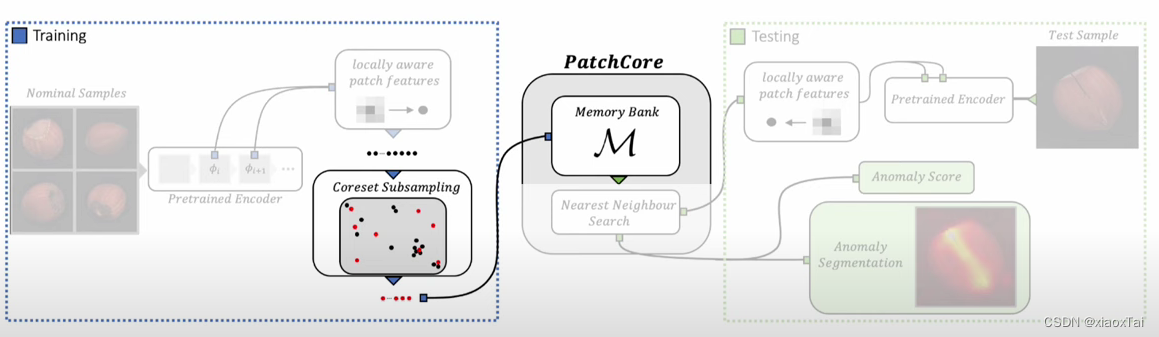
Youtube2PatchCore主要包含三个部分
- 创建特征的内存库
- 通过贪心策略减少内存块数据量
- 使用该内存块检测异常
下面本人先介绍一下整个工程的流程,代码见patchcore-inspection,后面再逐一详细介绍三个部分的代码
补充
使用其他数据集训练PatchCore见缺陷检测:使用PatchCore训练自己的数据集
代码流程
输入参数如下
run_patchcore.py --gpu 0 --seed 0 --save_patchcore_model --save_segmentation_images --log_group IM224_WR50_L2-3_P01_D1024-1024_PS-3_AN-1_S0 --log_project MVTecAD_Results results patch_core -b wideresnet50 -le layer2 -le layer3 --faiss_on_gpu --pretrain_embed_dimension 1024 --target_embed_dimension 1024 --anomaly_scorer_num_nn 1 --patchsize 3 sampler -p 0.1 approx_greedy_coreset dataset --resize 256 --imagesize 224 -d wood mvtec E:\datasets\mvtec- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
首先程序运行的是
run_patchcore.py的run(),先创建所需要的文件夹,再通过list_of_dataloaders = methods["get_dataloaders"](seed)来运行get_dataloaders()函数以获得训练数据和测试数据的dataloader。
上述是准备阶段,接着通过PatchCore.fit(dataloaders["training"])来将训练数据集,将图片转换为特征向量,再通过PatchCore.predict(dataloaders["testing"])对测试数据进行分数预测。接着就是是否保存预测结果和模型。Local Patch Features

这一部分主要代码如下:
def _image_to_features(input_image): with torch.no_grad(): input_image = input_image.to(torch.float).to(self.device) return self._embed(input_image)- 1
- 2
- 3
- 4
图片一开始会被reesize为(3, 224, 224),这个大小由
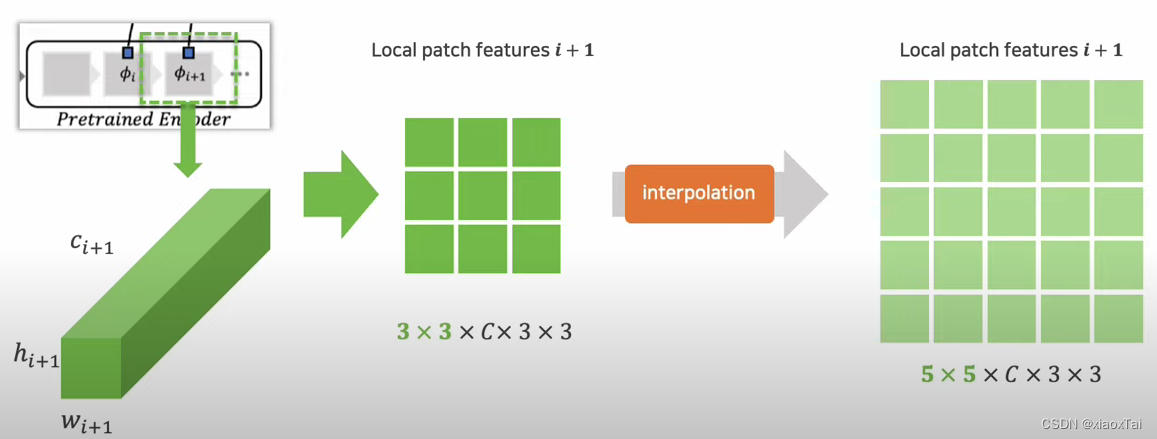
MVTecDataset.imageszie这个成员来管理,经过_embed(input_image)将特征提取出来,layer2的输出为(2, 512, 28, 28),layer3的输出为(2, 1024, 14, 14)。再对layer2征层进行裁切得到(2, 512, 3, 3, 28, 28),如下图所示(注意下面的蓝格子和绿格子都代表3×3的特征块),这里的2表示batch_size。

而layer3的特征层要进一步进行插值(通过_features = F.interpolate( _features.unsqueeze(1), size=(ref_num_patches[0], ref_num_patches[1]), mode="bilinear", align_corners=False, )和reshape)得到(2, 1024, 3, 3, 28, 28)的形状,如下图所示:
然后通过下面两句对特征进行自适应均匀池化,得到(1568, 1024)个特征值,所以一张图片得到的特征数量是784个。features = self.forward_modules["preprocessing"](features) features = self.forward_modules["preadapt_aggregator"](features)- 1
- 2

遍历完所有的测试图片,得到的features为(193648, 1024)即(784×247, 1024)
Coreset Subsampling
主要代码features = self.featuresampler.run(features)def run( self, features: Union[torch.Tensor, np.ndarray] ) -> Union[torch.Tensor, np.ndarray]: """Subsamples features using Greedy Coreset. Args: features: [N x D] """ if self.percentage == 1: return features self._store_type(features) if isinstance(features, np.ndarray): features = torch.from_numpy(features) reduced_features = self._reduce_features(features) # 经过一个全连接层 sample_indices = self._compute_greedy_coreset_indices(reduced_features) # 通过贪心策略减少数据量 features = features[sample_indices] return self._restore_type(features)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
经过一个全连接层将通道数减少至128,然后就是贪心策略的采样,具体如下:
初始阶段,随机选取10个index,通过如下代码计算所有特征点关于这十个点的欧式距离,得到集合D(193648, 10),接着取均值得到平均距离集合d1(193648, 1),选取值最大的那个值作为Mc的一个点x,接着计算x关于所有点的欧式距离d2(193648, 1),将d1和d2进行对应位运算,保留较小的值,从而得到d3,最后取d3中最大的值加入到Mc,并成为新的x,一直循环193648*0.1次。def _compute_batchwise_differences( matrix_a: torch.Tensor, matrix_b: torch.Tensor ) -> torch.Tensor: """Computes batchwise Euclidean distances using PyTorch.""" a_times_a = matrix_a.unsqueeze(1).bmm(matrix_a.unsqueeze(2)).reshape(-1, 1) b_times_b = matrix_b.unsqueeze(1).bmm(matrix_b.unsqueeze(2)).reshape(1, -1) a_times_b = matrix_a.mm(matrix_b.T) return (-2 * a_times_b + a_times_a + b_times_b).clamp(0, None).sqrt()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Detection and Localization
这里主要是使用faiss.GpuIndexFlatL2,具体原理本人也不太清楚。预测阶段主要代码如下def _predict_dataloader(self, dataloader): """This function provides anomaly scores/maps for full dataloaders.""" _ = self.forward_modules.eval() scores = [] masks = [] labels_gt = [] masks_gt = [] with tqdm.tqdm(dataloader, desc="Inferring...", leave=False) as data_iterator: for image in data_iterator: if isinstance(image, dict): labels_gt.extend(image["is_anomaly"].numpy().tolist()) masks_gt.extend(image["mask"].numpy().tolist()) image = image["image"] _scores, _masks = self._predict(image) for score, mask in zip(_scores, _masks): scores.append(score) masks.append(mask) return scores, masks, labels_gt, masks_gt- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
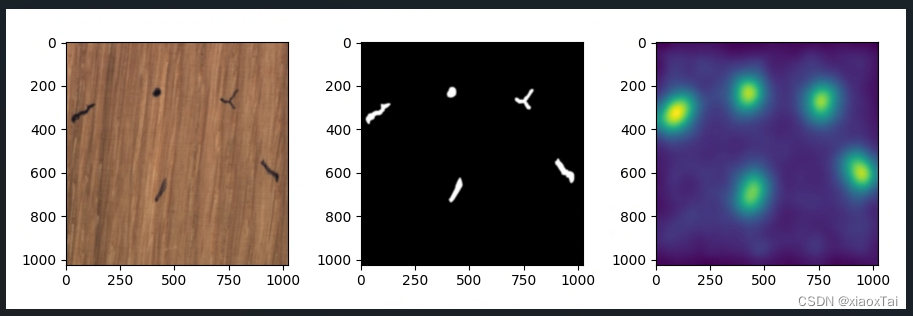
运行结果
运行结果会保存在
patchcore-inspection\bin\results\MVTecAD_Results下,结果如下图所示(大家应该图片都是256*256,我这里稍微修改了一点代码,以原尺寸大小输出图片)

-
相关阅读:
简单聊一聊一种很新的DCDC电源-BOB电源
【Modbus通讯】记粤西某电厂DCS通讯调试(基础篇)
Android——Theme和Style-由浅入深,全面讲解
面试官:设计模式中的桥接模式是什么?
【网络安全篇】--HTML基础(预计学习时间:30分钟)从此以后不迷糊~
个人博客项目中遇到的 mongodb 操作
生信豆芽菜-机器学习筛选特征基因
langchain教程-(1)Prompt模板
【01】区块链技术概述
毕业本科生涯回顾
- 原文地址:https://blog.csdn.net/xiao3_tai/article/details/136504813
