-
Java多线程——CyclicBarrier 与 CountDownLatch 区别,如何线程间数据交换?

引出
Java多线程——CyclicBarrier 与 CountDownLatch 区别,如何线程间数据交换?
CyclicBarrier 与 CountDownLatch 区别
CyclicBarrier是 Java 中的一个同步工具类,用于在多线程环境下实现线程的同步和协调。它的作用在于,让一组线程在达到某个同步点时等待,直到所有线程都达到同步点后再继续执行。CyclicBarrier的名称中的 “Cyclic” 意味着它可以被重复使用,即当所有线程都达到同步点后,它会重新被重置,以便后续的同步。主要应用场景和作用包括:
- 多线程任务协同: 当一组线程需要相互等待,直到所有线程都到达某个共同点时再继续执行,可以使用
CyclicBarrier。它可以用于将多个线程的计算结果进行合并,或者在多个线程完成某个任务后再执行某个操作。 - 分阶段任务: 如果一个任务可以分为多个阶段,并且需要等待每个阶段的所有线程都完成后再进入下一阶段,
CyclicBarrier可以用于控制线程的同步,以确保每个阶段的所有线程都完成。 - 线程池任务的同步: 在一些并发框架中,例如 Fork/Join 框架,可以使用
CyclicBarrier来同步不同分支的任务执行。
要点:
- 1:CyclicBarrier(可重用屏障/栅栏) 类似于 CountDownLatch(倒计数闭锁),它能阻塞一组线程直到某个事件的发生。
- 2:与闭锁的关键区别在于,所有的线程必须同时到达屏障位置,才能继续执行。
- 3:闭锁用于等待事件,而屏障用于等待其他线程。
- 4:CyclicBarrier 可以使一定数量的线程反复地在屏障位置处汇集。当线程到达屏障位置时将调用 await() 方法,这个方法将阻塞直到所有线程都到达屏障位置。如果所有线程都到达屏障位置,那么屏障将打开,此时所有的线程都将被释放,而屏障将被重置以便下次使用。
- 5:CyclicBarrier 是一个同步辅助类,它允许一组线程相互等待直到所有线程都到达一个公共的屏障点。
- 6:在程序中有固定数量的线程,这些线程有时候必须等待彼此,这种情况下,使用 CyclicBarrier 很有帮助。
- 7:这个屏障之所以用循环修饰,是因为在所有的线程释放彼此之后,这个屏障是可以重新使用的。
public class App10 { /** * 1:`CyclicBarrier(可重用屏障/栅栏) 类似于 CountDownLatch(倒计数闭锁),它能阻塞一组线程直到某个事件的发生`。 * 2:与闭锁的关键区别在于,所有的线程必须同时到达屏障位置,才能继续执行。 * 3:闭锁用于等待事件,而屏障用于等待其他线程。 * 4:CyclicBarrier 可以使一定数量的线程反复地在屏障位置处汇集。当线程到达屏障位置时将调用 await() 方法,这个方法将阻塞直到所有线程都到达屏障位置。如果所有线程都到达屏障位置,那么屏障将打开,此时所有的线程都将被释放,而屏障将被重置以便下次使用。 * 5:CyclicBarrier 是一个同步辅助类,它允许一组线程相互等待直到所有线程都到达一个公共的屏障点。 * 6:在程序中有固定数量的线程,这些线程有时候必须等待彼此,这种情况下,使用 CyclicBarrier 很有帮助。 * 7:这个屏障之所以用循环修饰,是因为在所有的线程释放彼此之后,这个屏障是可以重新使用的。 */ public static void main(String[] args) throws InterruptedException { // CyclicBarrier的构造函数传入了线程数量和一个回调函数, // 当所有线程都到达屏障时会执行这个回调函数。 // 每个线程都调用 await() 方法等待其他线程到达屏障,然后在达到屏障后继续执行。 // 这个示例模拟了多个线程在屏障点同步的情况。 CyclicBarrier cyclicBarrier = new CyclicBarrier(10,new Thread(()->{ System.out.println("开始比赛!"); })); Runnable runnable = ()->{ System.out.println(Thread.currentThread().getName() + ":到达会篮球场"); try { // 到达屏障,阻塞当前线程 cyclicBarrier.await(); System.out.println(Thread.currentThread().getName() + ":到达会篮球场---之后"); } catch (Exception e) { e.printStackTrace(); } }; for (int i = 0; i < 10; i++) { new Thread(runnable).start(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
CountDownLatch 的计数器只能使用一次。而 CyclicBarrier的计数器可以多次使用。reset()方法重置;
CyclicBarrier能处理更为复杂的业务场景,比如如果计算发生错误,可以重置计数器,并让线程们重新执行一次。
CountDownLatch 采用减计数方式;CyclicBarrier 采用加计数方式。
线程间数据交换?
Exchange:Exchanger是一个用来进行线程之间的数据交换的工具类,它提供了一个同步点,在这个同步点,两个线程可以互相交换数据。
@Data @NoArgsConstructor @AllArgsConstructor @Builder class ResultData{ private String name; private String msg; } public class App12 { public static void main(String[] args) throws InterruptedException { Exchanger<ResultData> exchanger = new Exchanger<>(); new Thread(()->{ ResultData dataA = ResultData.builder().name("小张").msg("鸡腿").build(); try { ResultData dataB = exchanger.exchange(dataA); System.out.println("t1线程结果:" + dataB); } catch (InterruptedException e) { e.printStackTrace(); } },"t1").start(); new Thread(()->{ ResultData dataB = ResultData.builder().name("小丽").msg("汉堡").build(); try { ResultData dataA = exchanger.exchange(dataB); System.out.println("t2线程结果:" + dataA); } catch (InterruptedException e) { e.printStackTrace(); } },"t2").start(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
在上述示例中,
Exchanger用于交换字符串数据。当其中一个线程调用exchange方法时,它会等待另一个线程到达exchange方法,然后交换数据。在这个示例中,两个线程分别发送数据并接收对方发送的数据,实现了线程间的数据交换。需要注意的是,
Exchanger是一种点对点的数据交换机制,适用于两个线程之间交换数据。如果需要多个线程之间进行数据交换,可以使用其他的线程间数据交换方式,如阻塞队列等。Redis冲冲冲——缓存三兄弟:缓存击穿、穿透、雪崩
缓存击穿
缓存击穿:redis中没有,但是数据库有
顺序:先查缓存,判断缓存是否存在;如果缓存存在,直接返回数据;如果缓存不存在,則查询数据库,将数据库的数据存入到缓存

解决方案:将热点数据设置过期时间长一点;针对数据库的热点访问方法上分布式锁;
缓存穿透
缓存穿透:redis中没有,数据库也没有
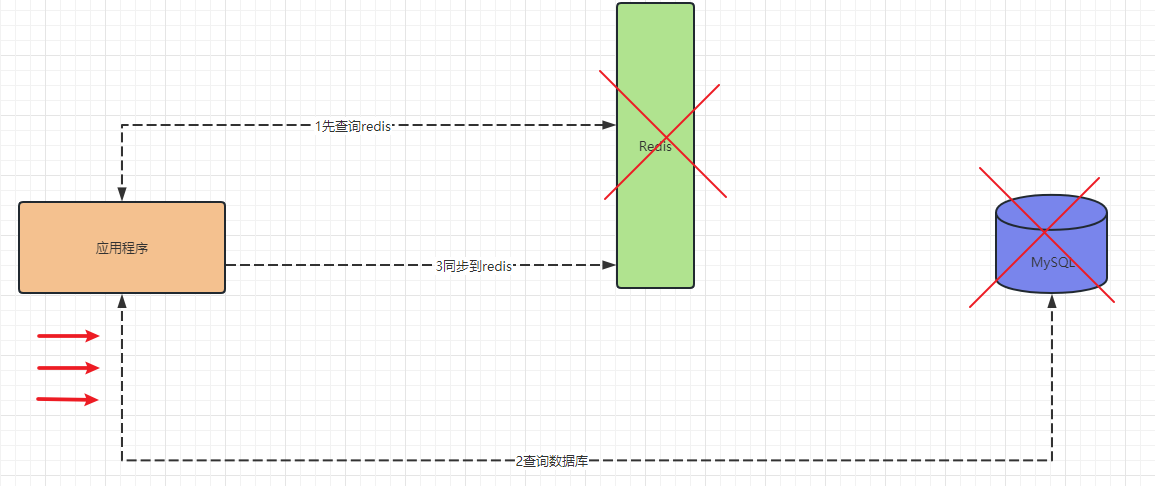
解决方案:
(1)将不存在的key,在redis设置值为null;
(2)使用布隆过滤器;
原理:https://zhuanlan.zhihu.com/p/616911933

布隆过滤器:
如果确认key不存在于redis中,那么就一定不存在;
它说key存在,就有可能存在,也可能不存在! (误差)

布隆过滤器
1、根据配置类中的 key的数量 ,误差率,计算位图数组【二维数组】
2、通过布隆过滤器存放key的时候,会计算出需要多少个hash函数,由hash函数算出多少个位图位置需要设定为1
3、查询时,根据对应的hash函数,判断对应的位置值是否都为1;如果有位置为0,则表示key一定不存在于该redis服务器中;如果全部位置都为1,则表示key可能存在于redis服务器中;
缓存雪崩
缓存雪崩:
Redis的缓存雪崩是指当Redis中大量缓存数据同时失效或者被清空时,大量的请求会直接打到数据库上,导致数据库瞬时压力过大,甚至宕机的情况。
造成缓存雪崩的原因主要有两个:
1.相同的过期时间:当Redis中大量的缓存数据设置相同的过期时间时,这些数据很可能会在同一时间点同时失效,导致大量请求直接打到数据库上。
2.缓存集中失效:当服务器重启、网络故障等因素导致Redis服务不可用,且缓存数据没有自动进行容错处理,当服务恢复时大量的数据同时被重新加载到缓存中,也会导致大量请求直接打到数据库上。
预防缓存雪崩的方法主要有以下几种:
1.设置不同的过期时间:可以将缓存数据的过期时间分散开,避免大量缓存数据在同一时间点失效。
2.使用加锁:可以将所有请求都先进行加锁操作,当某个请求去查询数据库时,如果还没有加载到缓存中,则只让单个线程去执行加载操作,其他线程等待该线程完成后再次进行判断,避免瞬间都去访问数据库从而引起雪崩。
3.提前加载预热:在系统低峰期,可以提前将部分热点数据加载到缓存中,这样可以避免在高峰期缓存数据失效时全部打到数据库上。
4.使用多级缓存:可以在Redis缓存之上再使用一层缓存,例如本地缓存等,当Redis缓存失效时,还能够从本地缓存中获取数据,避免直接打到数据库上。

本地缓存:ehcache oscache spring自带缓存 持久层框架的缓存
总结
Java多线程——CyclicBarrier 与 CountDownLatch 区别,如何线程间数据交换?
- 多线程任务协同: 当一组线程需要相互等待,直到所有线程都到达某个共同点时再继续执行,可以使用
-
相关阅读:
C语言框架FreeSwitch自定义事件介绍与使用示例
Golang通道(Channel)原理解析
二分算法笔记
万能的Python爬虫模板来了
基于PHP+MySQL的家教平台
AI基础软件:如何自主构建大+小模型?
Java面试题200+大全(合适各级Java人员)
Vue+element开发Simple Admin后端管理系统页面
谷歌数据中心尝试转向主线内核,发起新的项目Project Icebreaker
RPA案例|云扩助力保险行业开启超自动化运营新阶段
- 原文地址:https://blog.csdn.net/Pireley/article/details/136488055
