-
Kosmos-2: 在多模态大语言模型中引入基准和指代能力
Kosmos-2: 在多模态大语言模型中引入基准和指代能力FesianXu 20240304 at Baidu Search Team前言
之前笔者在博文中介绍过kosmos-1模型 [1],该模型脱胎于MetaLM采用『因果语言模型作为通用任务接口』的思想,采用了多种形式的多模态数据进行训练得到。而在本文将要介绍的kosmos-2中,作者则尝试引入了基准(grounding)和指代(referring)能力,使得多模态大语言模型的人机交互形式更加友好、灵活和多样。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
∇ \nabla ∇ 联系方式:
e-mail: FesianXu@gmail.com
github: https://github.com/FesianXu
github page: https://fesianxu.github.io/
知乎专栏: 计算机视觉/计算机图形理论与应用
微信公众号:机器学习杂货铺3号店
在我们正式介绍kosmos-2之前,我们首先了解下什么是指代(referring)功能和基准(grounding)功能,如Fig 1所示,这是百度app中的以图搜图功能,用户拍摄一张图片,此时用户可以对图中的多种物体进行画框,随后用户可以选择对被框框中的物体进行识别、提问或者发起搜索等。这个功能使得用户在以图搜图的场景中,可以更加灵活地和场景中的物体进行交互,这便是所谓的指代功能。各位读者有兴趣可以自行在手机百度App上体验这个功能。
 Fig 1. 百度搜索的以图搜图功能,支持一定程度的指代功能,通过画框显式筛选用户感兴趣的物体进行提问或者发起搜索。
Fig 1. 百度搜索的以图搜图功能,支持一定程度的指代功能,通过画框显式筛选用户感兴趣的物体进行提问或者发起搜索。当然,这种功能的一种最简单的实现思路就是对被框中的物体进行图片裁剪,直接对裁剪后的图片进行处理,显然这种方法将会丢失该框中物体和图片中其他物体的上下文关系。让我们举个例子,如Fig 2 (a)所示,如果对蓝色框中的物体进行提问,如果只是对蓝色框中的雪人进行裁剪后喂到模型中处理,就难以获得图片全局和被框中物体的上下文关联,因此很难分析出『他身上的微光是篝火倒映的结果』这个结论。在这个过程中,从原图中框定一些包围盒(Bounding box, bbox),通过提供这个包围盒的左上顶点坐标 ( x 0 , y 0 ) (x_0, y_0) (x0,y0)和右下角坐标 ( x 1 , y 1 ) (x_1, y_1) (x1,y1)即可。如Fig 2 (b)所示,这个过程称之为指代 (Referring),而所谓的基准(Grounding)1,则指的是模型的输出中,会对不同实体同时输出其在图中的包围盒的坐标。Grounding也可以翻译成『接地』,这让我们联想到了电子工程中的『地线』,电压的大小都是针对于地线而言的,因此『接地』『基准』可以理解为是为文本概念和视觉概念的对齐,而这个对齐更为显式,因为其要求模型提供了对应实体的包围盒坐标,此时的『地线』就是图片中特定的包围盒了。
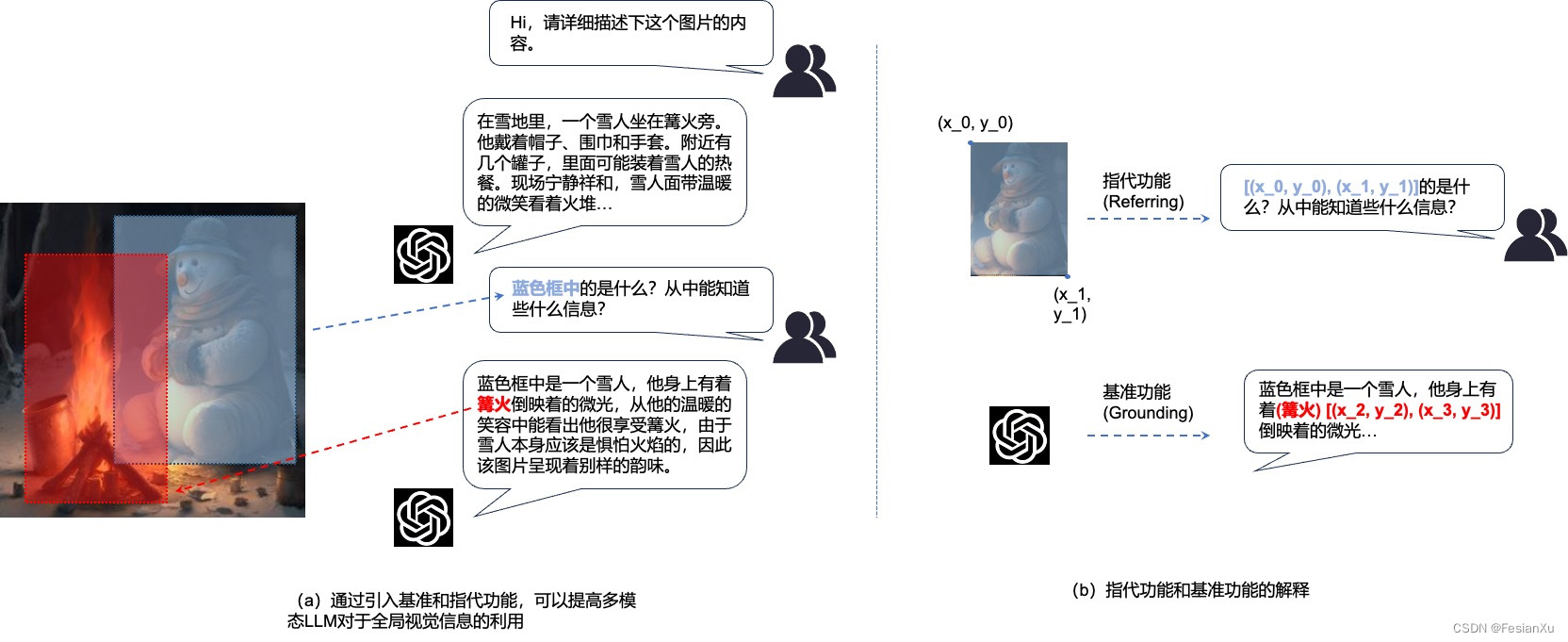 Fig 2. 基准功能和指代功能的解释和示例,可以使得多模态大语言模型具有全局的视觉理解和更灵活的人机交互能力。
Fig 2. 基准功能和指代功能的解释和示例,可以使得多模态大语言模型具有全局的视觉理解和更灵活的人机交互能力。如Fig 3所示,本文要介绍的kosmos-2 [2] 正是一种通过构建特定的多模态数据,引入了指代和基准能力的多模态大语言模型。作者在LAION-2B和COYO-700M数据集的基础上构建了基准图文对数据集(GRounded Image-Text pairs, GRIT),这种数据集是在<图片, 图片文本描述>成对数据的基础上,拆解和重组图片的文本描述,使得产生了不同粒度的文本片段(如名词片段、指代表述等),并通过基准物体识别模型(如GLIP [3])产出不同粒度文本片段的包围盒,通过这种方法形成了约9100万图片,1.15亿文本片段,1.37亿包围盒的GRIT数据集。将GRIT数据和Kosmos-1采用的多模态数据融合在一起训练得到了kosmos-2模型。
 Fig 3. Kosmos-2的示意图,其主要特点是引入了指代和基准能力。
Fig 3. Kosmos-2的示意图,其主要特点是引入了指代和基准能力。因此kosmos-2的主要升级点其实是GRIT数据集的构建,我们着重关注下数据的构建细节。如Fig 4所示,GRIT数据的构建主要包括两大步骤:
- 创建名词片段-包围盒成对样本:给定一个图片-文本描述样本,对文本描述样本进行名词片段提取,同时采用物体识别模型对图片进行处理得到所有包围盒,对提取好的名词片段和包围盒进行组建,得到名词片段-包围盒成对样本。注意到作者舍弃了抽象的名词片段,如"love", “time”, "freedom"等,这些抽象的概念容易带了噪声。
- 产出指代表述-包围盒成对样本:只是名词片段无法对一些复杂、组合概念进行描述,因此可以考虑对名词进行一些组合,构建出所谓的指代表述(referring expression)文本,本文通过SpaCy对文本进行依存关系树(dependency tree)解析,然后依次递归每个名词片段的子节点,然后将递归的子节点的词和该名词进行拼接得到扩展。举个具体的例子如下所示。
a dog in a field of flowers的依存关系树,由SpaCy 3.6.1生成。 dog ___|____ | in | | | field | ____|______ | | of | | | a a flowers 1. 以dog为中心进行扩展: a dog in a field of flowers 2. 以field为中心进行扩展: a field of flowers 3. 以flowers为中心进行扩展:flowers- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
为了减少冗余,作者只保留了那些不被其他指代表述或者名词片段包含的部分,以刚才的扩展为例子,作者保留了"a dog in a field of flowers",而舍弃了"a field of flowers"和"a field of flowers"。然后将"a dog"的包围盒赋值给了最终保留下的"a dog in a field of flowers"。整个过程如Fig 4所示。
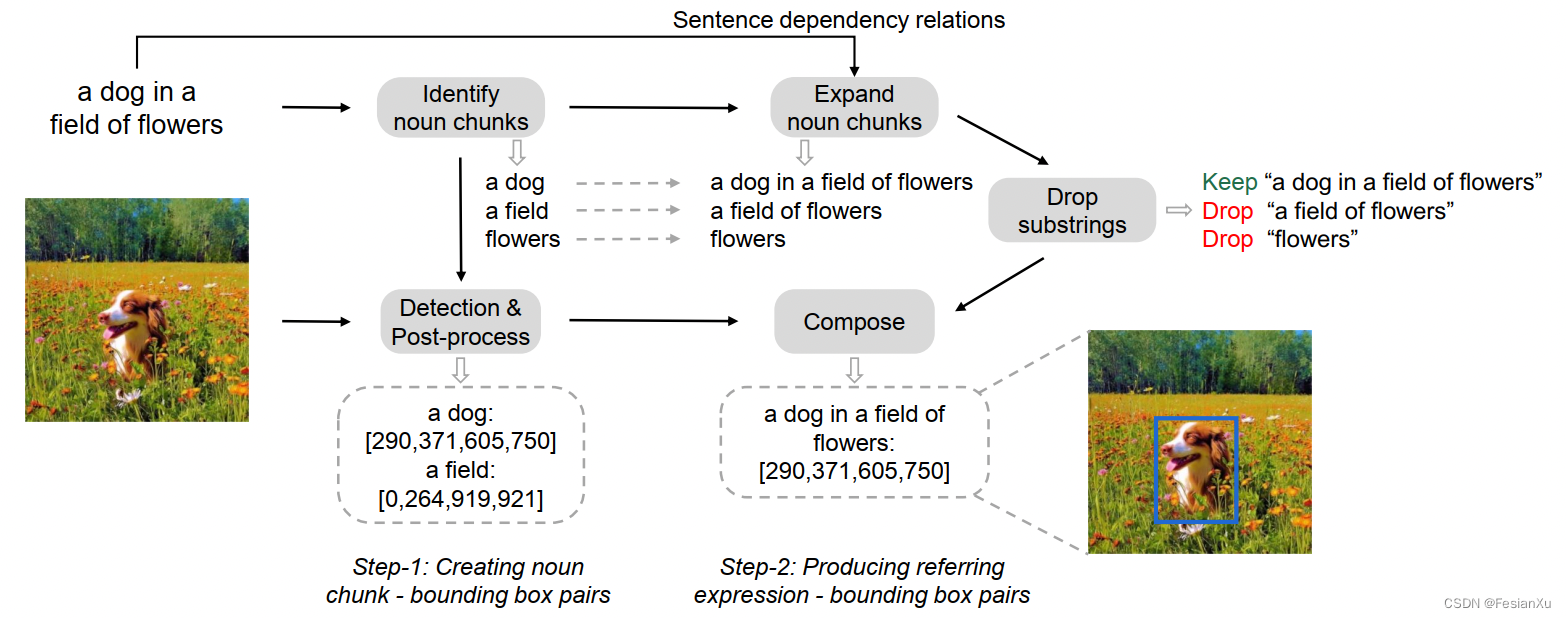 Fig 4. GRIT数据集构建流程,主要由两大步骤构成:名词片段-包围盒成对数据提取、指代表述-包围盒成对数据组建。
Fig 4. GRIT数据集构建流程,主要由两大步骤构成:名词片段-包围盒成对数据提取、指代表述-包围盒成对数据组建。在模型方面,kosmos-2沿用了kosmos-1的模型结构和训练范式,但是可以提供视觉回答(以输出图片中包围盒坐标的形式提供),也可以提供视觉输入和包围盒输入。此处的包围盒输入和输出都是左上角坐标和右下角坐标的形式,为了将训练目标统一到自回归生成,有必要将连续的坐标离散化到离散的token形式。一种可行的方法是将一个长宽分别为 W W W和 H H H的图片均匀划分到 P × P P \times P P×P的分块(patch)中,每一个分块大小为 ( W / P ) × ( H / P ) (W / P) \times (H / P) (W/P)×(H/P)像素。对于每个分块而言给它赋予一个唯一的token id,采用每个分块的中心像素的坐标代表整个分块的左边。最终在整个词表中将会新增 P × P P \times P P×P个新的包围盒『词』,至此包围盒的输入输出和文本输入输出便是打平了。
此时一个包围盒的输入或输出如
loc1和loc2表示左上角和右下角分块的token id,而则是特殊标记,表示了包围盒的开始和结束。如果一个文本片段包含了多个包围盒,则通过... 然后以类似于书写markdown文档超链接的形式,给文本片段添加包围盒,如
是特殊标记,表示了需要提供基准的文本片段。最终一个完整的输入如下所示,其中的text span
和表示整个序列的开始和结束,而则表示了提供的视觉向量的开始和结束,<s> <image> Image Embedding image> <grounding> <p> It p> <box> <loc44> <loc863> box> seats next to <p> a campfire p> <box> <loc4> <loc1007> box> s>- 1
- 2
在kosmos-1的纯文本数据、图文交织数据、图文对数据的基础上,作者引入了GRIT基准图文数据,损失计算只对离散的token进行,如文本token和包围盒位置token,而略过特殊标记。在实验中,作者将 P = 32 P=32 P=32,因此一共新增有 32 × 32 = 1024 32 \times 32=1024 32×32=1024个包围盒位置token,一个训练batch size包含了419k个token,其中185k个token来自于文本数据集,215k来自于原始图文对数据和基准图文数据,19k个来自于图文交织数据。
作者在实验部分验证了模型的基准和指代能力,同时给出了不少测试结果,笔者没看到有需要特别注意的,就不在这里贴出来了,有兴趣的读者自行去翻阅原文即可。笔者看来,从MetaLM到kosmos-1,再到kosmos-2,其实模型结构和训练范式并没有变化,优化的点主要还是各种多模态数据的构建上,这其实也启示我们在大模型年代,如何构建更好更合适的数据可能比魔改模型结构更有收益,数据采集和清洗是一种艺术,也许我们应该给予数据更多的关注和研究。
Reference
[1]. https://blog.csdn.net/LoseInVain/article/details/136428429, 《Kosmos-1: 通用接口架构下的多模态大语言模型》
[2]. Peng, Zhiliang, et al. “Kosmos-2: Grounding Multimodal Large Language Models to the World.” arXiv preprint arXiv:2306.14824 (2023). aka Kosmos-2.
[3]. Li, Liunian Harold, et al. “Grounded language-image pre-training.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022. aka GLIP.
在深度学习领域,“grounded” 通常指的是将模型的输出或表示与真实世界中的某些实体或概念相关联或对齐。这种关联可以为模型提供更丰富、更具解释性的信息,并有助于提高其性能。 当谈到“video grounded”时,这通常意味着视频数据中的某些内容与模型的输出或中间表示之间存在某种形式的对齐或关联。例如,在视频描述生成任务中,模型可能会生成描述视频内容的文本。如果这些描述确实与视频中的实际事件、物体或动作相对应,那么可以说模型在这方面是"grounded"的。简而言之,“grounded” 在这里意味着模型不仅仅是生成一些看似合理但与真实内容无关的输出,而是能够捕捉并与真实世界中的实体或事件建立联系。 ↩︎
-
相关阅读:
2000-2018年286个地级市PM2.5数据
始祖双碳新闻 | 2022年7月21日碳中和行业早知道
python系列26:numpy稀疏矩阵笔记
Apache Doris 基础 -- 数据表设计(数据模型)
linux中常用的文件处理命令
WDT实验
超参数黑盒(Black-box)优化的Python代码示例
Http和websocket(用Nodejs简单实现websocket通信)
C++--哈希表--散列--冲突--哈希闭散列模拟实现
亚马逊测评关于IP和DNS的问题
- 原文地址:https://blog.csdn.net/LoseInVain/article/details/136459707