-
基于ERNIR3.0的文本多分类
还在用BERT做文本分类?分享一套基于预训练模型ERNIR3.0的文本多分类全流程实例【文本分类】_ernir 文本分类-CSDN博客
/usr/bin/python3 -m pip install --upgrade pip
python3-c"import platform;print(platform.architecture()[0]);print(platform.machine())"
python3 -m pip install paddlepaddle==2.5.2 -i https://mirror.baidu.com/pypi/simple
python3 -m pip install --upgrade paddlenlp -i https://mirror.baidu.com/pypi/simple
echo 'export PATH="/usr/local/python3/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
pip3 install --upgrade paddlenlp -i https://mirror.baidu.com/pypi/simple
echo 'export PATH="/usr/local/python3/bin:$PATH"' >> ~/.bashrc
source ~/.bashrc
pip3 install scikit-learn==1.0.2
3.2 文心ERNIE系列模型介绍
最新开源ERNIE 3.0系列预训练模型:
- 110M参数通用模型ERNIE 3.0 Base
- 280M参数重量级通用模型ERNIE 3.0 XBase
- 74M轻量级通用模型ERNIE 3.0 Medium
文档链接: https://github.com/PaddlePaddle/ERNIE
ERNIE模型汇总
ERNIE模型汇总3.3 预训练模型加载
PaddleNLP内置了ERNIE、BERT、RoBERTa、Electra等40多个的预训练模型,并且内置了各种预训练模型对于不同下游任务的Fine-tune网络。用户可以使用PaddleNLP提供的模型,完成问答、序列分类、token分类等任务。
这里以ERNIE 3.0模型为例,介绍如何将预训练模型Fine-tune完成文本分类任务。
PaddleNLP采用AutoModelForSequenceClassification,AutoTokenizer提供了简单易用的接口,可以用过from_pretrained() 方法来加载不同的预训练模型,在输出层上叠加一层线性层,且相应预训练模型权重下载速度快、稳定。
下面以ERNIE 3.0中文base模型为基础,演示如何添加预训练语言模型和分词器:
-------------------------------------------------------------------------------------------------------------------------
sudo yum install git
git clone https://github.com/PaddlePaddle/PaddleNLP.git
pip3 install --upgrade paddlenlp
pip install paddlepaddle


参考:
PaddleNLP/applications/text_classification at develop · PaddlePaddle/PaddleNLP · GitHub
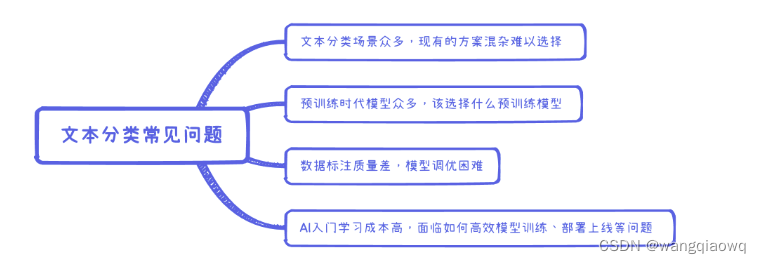
如何选择合适的方案和预训练模型、数据标注质量差、效果调优困难、AI入门成本高、如何高效训练部署等问题使部分开发者望而却步
文本分类应用针对多分类、多标签、层次分类等高频场景开源了产业级分类应用方案,打通数据标注-模型训练-模型调优-模型压缩-预测部署全流程,旨在解决细分场景应用的痛点和难点,快速实现文本分类产品落地。
- 方案全面🎓: 涵盖多分类、多标签、层次分类等高频分类场景,提供预训练模型微调、提示学习(小样本学习)、语义索引三种端到端全流程分类方案,满足开发者多样文本分类落地需求。
- 高效调优✊: 文本分类应用依托TrustAI可信增强能力和数据增强API,提供模型分析模块助力开发者实现模型分析,并提供稀疏数据筛选、脏数据清洗、数据增强等多种解决方案。
2.1 文本分类方案全覆盖
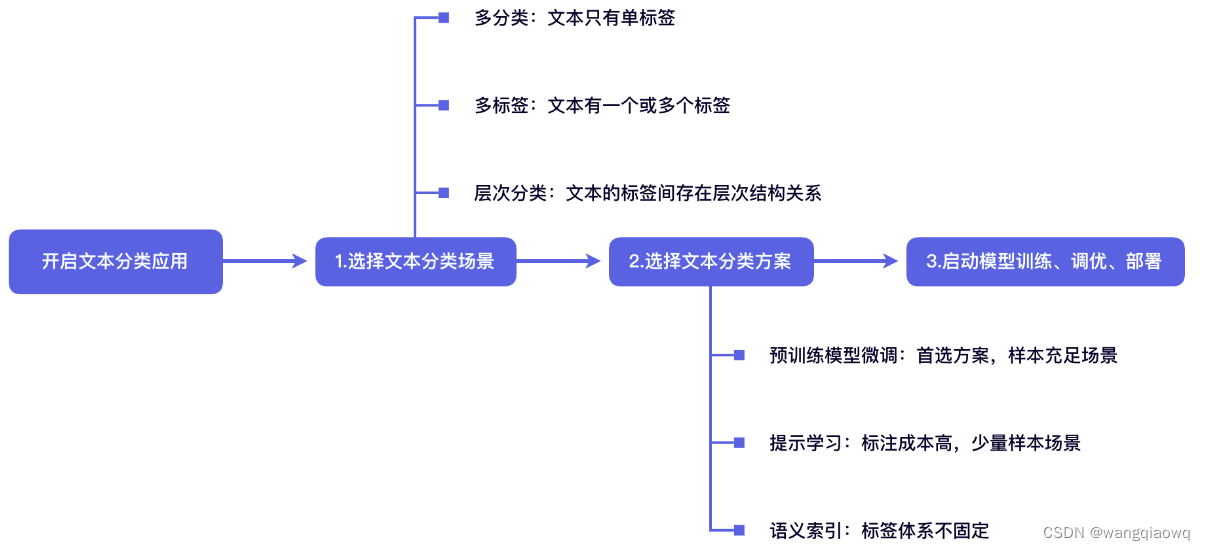
文本分类应用涵盖多分类(multi class)、多标签(multi label)、层次分类(hierarchical)三种场景

多分类🚶: 数据集的标签集含有两个或两个以上的类别,所有输入句子/文本有且只有一个标签。在文本多分类场景中,我们需要预测输入句子/文本最可能来自
n个标签类别中的哪一个类别。以上图多分类中新闻文本为例,该新闻文本的标签为娱乐。二分类/多分类数据集的标签集含有两个或两个以上的类别,所有输入句子/文本有且只有一个标签。在文本多分类场景中,我们需要预测输入句子/文本最可能来自
n个标签类别中的哪一个类别。在本项目中二分类任务被视为多分类任务中标签集包含两个类别的情况,以下统一称为多分类任务。。多分类任务在商品分类、网页标签、新闻分类、医疗文本分类等各种现实场景中具有广泛的适用性。问题 ---- lable --- {新闻,娱乐}
问题 lable 分类
-------------------------------

多分类数据标注-模型训练-模型分析-模型压缩-预测部署流程图
参考:PaddleNLP/applications/text_classification/multi_class at develop · PaddlePaddle/PaddleNLP · GitHub二分类/多分类任务指南
参考:PaddleNLP/applications/text_classification/multi_class at develop · PaddlePaddle/PaddleNLP · GitHub
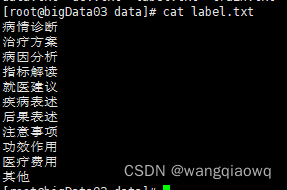
接下来我们将以CBLUE公开数据集KUAKE-QIC任务为示例,演示多分类全流程方案使用。下载数据集:wget https://paddlenlp.bj.bcebos.com/datasets/KUAKE_QIC.tar.gz
tar -zxvf KUAKE_QIC.tar.gz
mv KUAKE_QIC data rm -rf KUAKE_QIC.tar.gz

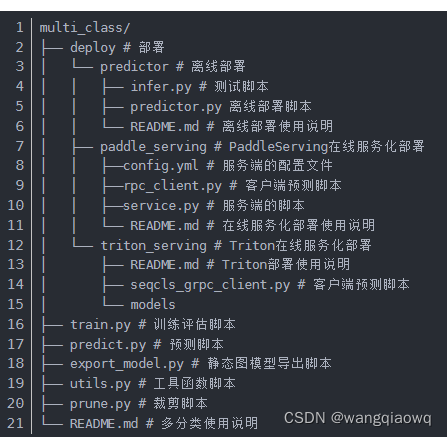
训练需要准备指定格式的本地数据集,如果没有已标注的数据集,可以参考文本分类任务doccano数据标注使用指南进行文本分类数据标注。指定格式本地数据集目录结构:
训练、开发、测试数据集 文件中文本与标签类别名用tab符
'\t'分隔开,文本中避免出现tab符'\t'。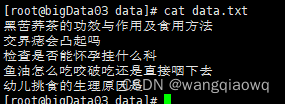



2.4 模型训练
推荐使用 Trainer API 对模型进行微调。只需输入模型、数据集等就可以使用 Trainer API 高效快速地进行预训练、微调和模型压缩等任务,可以一键启动多卡训练、混合精度训练、梯度累积、断点重启、日志显示等功能,Trainer API 还针对训练过程的通用训练配置做了封装,比如:优化器、学习率调度等。
2.4.1 预训练模型微调
使用CPU训练只需将设备参数配置改为
--device cpu,可以使用--device gpu:0指定GPU卡号:cpu命令未验证:有问题
python3 train.py --do_train --do_eval --do_export --model_name_or_path ernie-3.0-tiny-medium-v2-zh --output_dir checkpoint --device cpu --num_train_epochs 100 --early_stopping True --early_stopping_patience 5 --learning_rate 3e-5 --max_length 128 --per_device_eval_batch_size 32 --per_device_train_batch_size 32 --metric_for_best_model accuracy --load_best_model_at_end --logging_steps 5 --evaluation_strategy epoch --save_strategy epoch --save_total_limit 1
gpu的命令:有问题
python3 train.py --do_train --do_eval --do_export --model_name_or_path ernie-3.0-tiny-medium-v2-zh --output_dir checkpoint --device gpu:0 --early_stopping True --early_stopping_patience 5 --learning_rate 3e-5 --max_length 128 --per_device_eval_batch_size 32 --per_device_train_batch_size 32 --metric_for_best_model accuracy --load_best_model_at_end --logging_steps 5 --evaluation_strategy epoch --save_strategy epoch --save_total_limit 1

train
paddle.device.set_device('cpu')
找个gpu的服务
https://aistudio.baidu.com/bd-cpu-01/user/7541663/7506482/lab
conda install cudatoolkit=10.2
参考:安装paddlepadddle-gpu的正确方式_please use paddlepaddle with gpu version-CSDN博客
python -m pip install paddlepaddle-gpu==2.5.2.post102 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
python -m pip install paddlepaddle-gpu==2.5.2.post102 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
这个是好事gpu的,

find . -name "libcudart.so.10.2"
参考:https://blog.csdn.net/weixin_45742602/article/details/129386113


有问题:
python3 train.py --do_train --do_eval --do_export --model_name_or_path ernie-3.0-tiny-medium-v2-zh --output_dir checkpoint --device gpu:0 --early_stopping True --early_stopping_patience 5 --learning_rate 3e-5 --max_length 128 --per_device_eval_batch_size 32 --per_device_train_batch_size 32 --metric_for_best_model accuracy --load_best_model_at_end --logging_steps 5 --evaluation_strategy epoch --save_strategy epoch --save_total_limit 1
有问题:
python3 train.py --do_train --do_eval --do_export --model_name_or_path ernie-3.0-tiny-medium-v2-zh --output_dir checkpoint --device gpu:0 --early_stopping_patience 5 --learning_rate 3e-5 --max_length 128 --per_device_eval_batch_size 16 --per_device_train_batch_size 16 --metric_for_best_model accuracy --load_best_model_at_end --logging_steps 5 --evaluation_strategy epoch --save_strategy epoch --save_total_limit 1
最后成功的命令:
python3 train.py --do_train --do_eval --do_export --model_name_or_path ernie-3.0-tiny-medium-v2-zh --output_dir checkpoint --device gpu:0 --early_stopping_patience 5 --learning_rate 3e-5 --max_length 128 --metric_for_best_model accuracy --load_best_model_at_end --logging_steps 5 --evaluation_strategy epoch --save_strategy epoch --save_total_limit 1

终于跑成功了 要吐血了。。。!
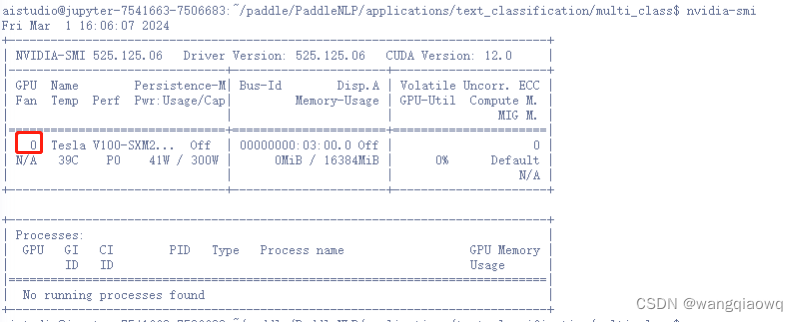
nvidia-smi命令查看GPU使用情况:主要的配置的参数为:
do_train: 是否进行训练。do_eval: 是否进行评估。debug: 与do_eval配合使用,是否开启debug模型,对每一个类别进行评估。do_export: 训练结束后是否导出静态图。do_compress: 训练结束后是否进行模型裁剪。model_name_or_path: 内置模型名,或者模型参数配置目录路径。默认为ernie-3.0-tiny-medium-v2-zh。output_dir: 模型参数、训练日志和静态图导出的保存目录。device: 使用的设备,默认为gpu。num_train_epochs: 训练轮次,使用早停法时可以选择100。early_stopping: 是否使用早停法,也即一定轮次后评估指标不再增长则停止训练。early_stopping_patience: 在设定的早停训练轮次内,模型在开发集上表现不再上升,训练终止;默认为4。learning_rate: 预训练语言模型参数基础学习率大小,将与learning rate scheduler产生的值相乘作为当前学习率。max_length: 最大句子长度,超过该长度的文本将被截断,不足的以Pad补全。提示文本不会被截断。per_device_train_batch_size: 每次训练每张卡上的样本数量。可根据实际GPU显存适当调小/调大此配置。per_device_eval_batch_size: 每次评估每张卡上的样本数量。可根据实际GPU显存适当调小/调大此配置。max_length: 最大句子长度,超过该长度的文本将被截断,不足的以Pad补全。提示文本不会被截断。train_path: 训练集路径,默认为"./data/train.txt"。dev_path: 开发集集路径,默认为"./data/dev.txt"。test_path: 测试集路径,默认为"./data/dev.txt"。label_path: 标签路径,默认为"./data/label.txt"。bad_case_path: 错误样本保存路径,默认为"./data/bad_case.txt"。width_mult_list:裁剪宽度(multi head)保留的比例列表,表示对self_attention中的q、k、v以及ffn权重宽度的保留比例,保留比例乘以宽度(multi haed数量)应为整数;默认是None。 训练脚本支持所有TrainingArguments的参数,更多参数介绍可参考
程序运行时将会自动进行训练,评估。同时训练过程中会自动保存开发集上最佳模型在指定的
output_dir中,保存模型文件结构如下所示:

- 中文训练任务(文本支持含部分英文)推荐使用"ernie-1.0-large-zh-cw"、"ernie-3.0-tiny-base-v2-zh"、"ernie-3.0-tiny-medium-v2-zh"、"ernie-3.0-tiny-micro-v2-zh"、"ernie-3.0-tiny-mini-v2-zh"、"ernie-3.0-tiny-nano-v2-zh"、"ernie-3.0-tiny-pico-v2-zh"。
2.4.2 训练评估
训练后的模型我们可以开启
debug模式,对每个类别分别进行评估,并打印错误预测样本保存在bad_case.txt。python train.py \
--do_eval \
--debug True \
--device gpu \
--model_name_or_path checkpoint \
--output_dir checkpoint \
--per_device_eval_batch_size 32 \
--max_length 128 \
--test_path './data/dev.txt'python train.py --do_eval --debug --device gpu:0 --model_name_or_path checkpoint --output_dir checkpoint --per_device_eval_batch_size 32 --max_length 128 --test_path './data/dev.txt'

文本分类预测过程中常会遇到诸如"模型为什么会预测出错误的结果","如何提升模型的表现"等问题。Analysis模块 提供了可解释性分析、数据优化等功能,旨在帮助开发者更好地分析文本分类模型预测结果和对模型效果进行优化。
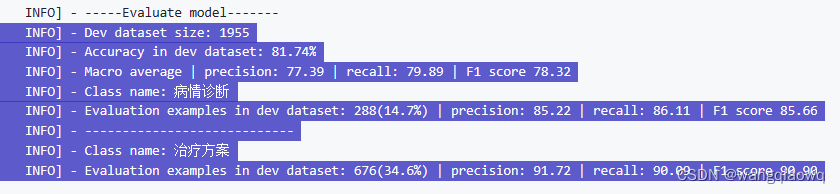

2.4.3 模型裁剪(可选)
如果有模型部署上线的需求,需要进一步压缩模型体积,可以使用 PaddleNLP 的 压缩API, 一行命令即可启动模型裁剪。
pip install paddleslim==2.4.1
python train.py \ --do_compress \ --device gpu \ --model_name_or_path checkpoint \ --output_dir checkpoint/prune \ --learning_rate 3e-5 \ --per_device_train_batch_size 32 \ --per_device_eval_batch_size 32 \ --num_train_epochs 1 \ --max_length 128 \ --logging_steps 5 \ --save_steps 100 \ --width_mult_list '3/4' '2/3' '1/2'还是没有成功。。。
nvcc -V
https://gitee.com/paddlepaddle/PaddleSlim
还是有问题 尚未解决

python train.py --do_compress --device gpu --model_name_or_path checkpoint --output_dir checkpoint/prune --learning_rate 3e-5 --per_device_train_batch_size 32 --per_device_eval_batch_size 32 --num_train_epochs 1 --max_length 128 --logging_steps 5 --save_steps 100 --width_mult_list '3/4' '2/3' '1/2'
另外的错误:


2.5 模型预测

可配置参数说明
task_path:自定义任务路径,默认为None。is_static_model:task_path中是否为静态图模型参数,默认为False。max_length:最长输入长度,包括所有标签的长度,默认为512。batch_size:批处理大小,请结合机器情况进行调整,默认为1。id2label:标签映射字典,如果task_path中包含id2label.json或加载动态图参数无需定义。precision:选择模型精度,默认为fp32,可选有fp16和fp32。fp16推理速度更快。如果选择fp16,请先确保机器正确安装NVIDIA相关驱动和基础软件,确保CUDA>=11.2,cuDNN>=8.1.1,初次使用需按照提示安装相关依赖。
用这个服务器即可,环境已搭建好了:
ERNIE 3.0_体验1 (baidu.com)
- import paddle
- from paddlenlp import Taskflow
- from paddlenlp.transformers import ErnieTokenizer, ErnieModel
- # 模型预测
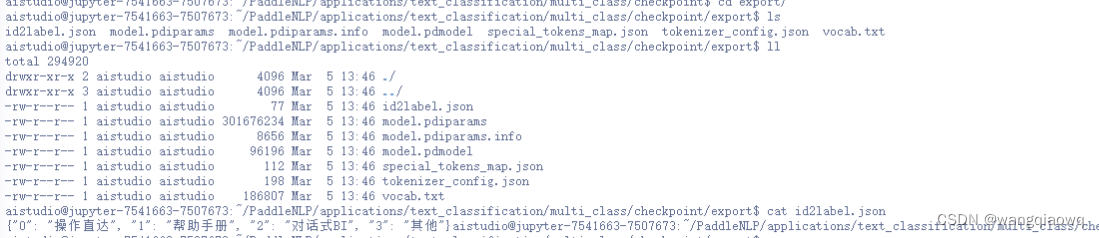
- cls = Taskflow("text_classification", task_path='checkpoint/export', is_static_model=True)
- print(cls(["查询销售订单","怎么登录ERP"]))
- # 裁剪模型预测
- cls = Taskflow("text_classification", task_path='checkpoint/export', is_static_model=True)
- print(cls(["查询销售订单","怎么登录ERP"]))
- # 加载ERNIE 3.0模型和分词器
- tokenizer = ErnieTokenizer.from_pretrained('ernie-3.0-tiny-medium-v2-zh')
- model = ErnieModel.from_pretrained('ernie-3.0-tiny-medium-v2-zh')
- # 要搜索的句子
- search_sentence = "查询销售订单"
- # 将搜索句子向量化
- encoded_input = tokenizer([search_sentence], padding=True, truncation=True, return_tensors='pd', max_seq_len=512)
- with paddle.no_grad():
- search_vector = model(**encoded_input)[1].numpy()
- print(search_vector)
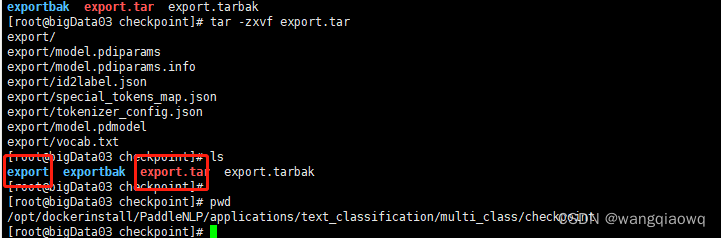
tar -zcvf export.tar export/

打包下载 放到服务化部署的机器上 作为文本分类的模型使用
2.6 模型效果
在线服务化部署搭建请参考:
报错 说是 paddlenlp模块找不到
-bash: paddlenlp: command not found
安装了 paddlenlp 2.5.2 解决了
先配置python3的路径
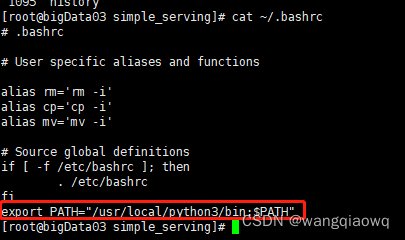
source ~/.bashrc
sudo ln -sf /usr/local/python3/bin/python3.7 /usr/bin/python3
sudo ln -sf /usr/local/python3/bin/pip3.7 /usr/bin/pip3pip3 install paddlenlp==2.5.2


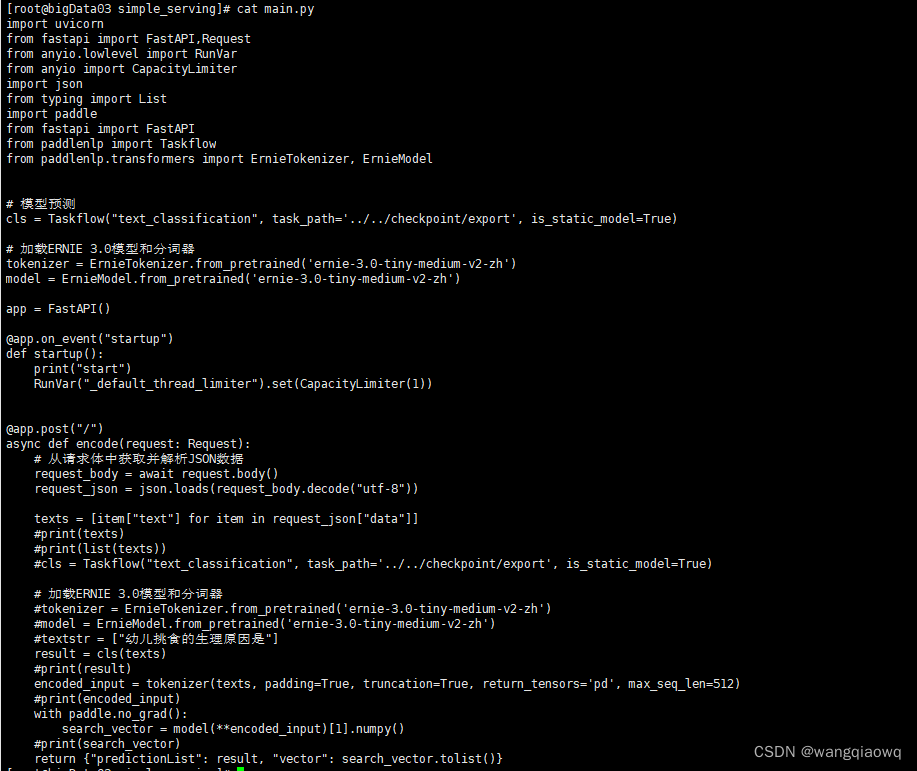
代码:
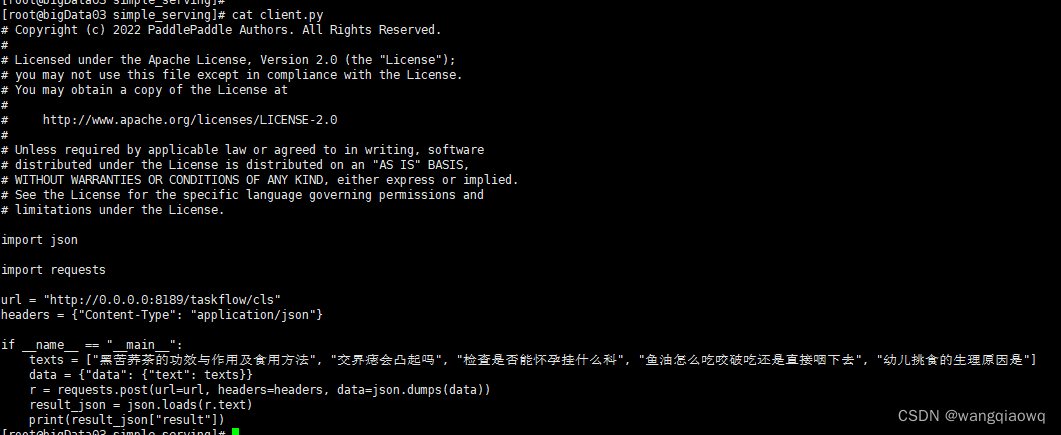
paddlenlp server server:app --host 0.0.0.0 --port 8189 --workers 2

从新写了一个 FastApi的服务 返回文本分类和词向量接口
python3 -m uvicorn main:app --host 192.168.1.243 --port 8111

nohup python3 -m uvicorn main:app --host 192.168.1.243 --port 4001 > paddlenlpweb.log 2>&1 &
nohup python3 -m uvicorn main:app --host 192.168.1.243 --port 8111 > paddlenlpweb.log 2>&1 &
[root@bigData03 simple_serving]# sudo systemctl stop firewalld
[root@bigData03 simple_serving]# systemctl status firewalld.service
关闭防火墙
检验:
curl -X POST http://192.168.1.243:4001/ -H 'Content-Type: application/json' -d '{"data":[{"text": "智能大屏"}, {"text": "智能销售"}]}'

-
相关阅读:
数据结构学习笔记(二)----线性表(上)
B2C在线教育商城--前后端分离部署
mysql面试题10:MySQL中有哪几种锁?表级锁、行级锁、页面锁区别和联系?
ESP32 485风速
【Python Web】Flask框架(五)Bootstrap登录和后台管理案例
未来各职业的人,都会涌入Python和AI大潮中,老教授深度解析
关于Docker挂载的问题!
ruoyi-cloud 升级mybatis plus 报错 Invalid bound statement (not found)
Spring MVC - 相关内容1
jQuery中的prop方法(全选按钮)
- 原文地址:https://blog.csdn.net/wangqiaowq/article/details/136386079
