-
如何利用pynlpir进行中文分词并保留段落信息
一、引言
nlpir是由张华平博士开发的中文自然处理工具,可以对中文文本进行分词、聚类分析等,它既有在线的中文数据大数据语义智能分析平台,也有相关的python包pynlpir,其github的地址是:
这个包的使用是免费的,但是授权文件需要每个月更新一次。
二、利用pynlpir进行分词
1.安装模块
首先要安装这个模块,安装方法是在cmd命令行下输入:
pip install pynlpir2. 更新授权
安装后还可能需要更新一下授权
pynlpir update3. 开始批量分词
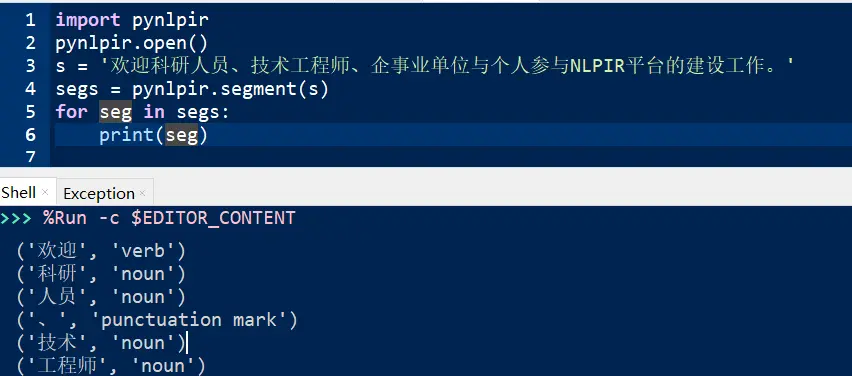
1)基础分词
- import pynlpir
- pynlpir.open()
- s = '欢迎科研人员、技术工程师、企事业单位与个人参与NLPIR平台的建设工作。'
- segs = pynlpir.segment(s)
- for seg in segs:
- print(seg)
显示结果:
基本使用方法
2)批量分词
主要是采用os模块批量读取当前目录下的txt文件,然后分别按段落读取、分词、标注。词与标注信息之前中【_】来连接,两个词之间用【|】,段落之间加入换行符号,然后写入到【seg_】开头的txt文件里。这里,我们采用的是英文的标注信息,每个文件标注完成后会生成新的文件,最终代码如下:
- import pynlpir
- import os
- # 初始化分词库
- pynlpir.open ()
- # 进行分词操作
- txts = [file for file in os.listdir(".") if file.endswith(".txt")]
- for txt in txts:
- with open(txt,"r",encoding="utf-8") as f:
- lines = [line.strip() for line in f.readlines()]
- for line in lines:
- segments = pynlpir.segment (line, pos_tagging=True,pos_english=True)
- with open("segged_"+os.path.basename(txt),"a+",encoding="utf-8") as fi:
- for segment in segments:
- try:
- fi.write(str(segment[0])+"_"+str(segment[1])+"|")
- except Exception as exc:
- print(exc,segment)
- fi.write("\n")
- # 关闭分词库
- pynlpir.close ()
4. 分词效果展示
经过分词和标注后的文件截图展示如下,可以看到很好地保留了段落的信息,这为后面进行词性统计也做好了准备。后期,可以根据nlpir的标注集,对于所有文本中的词性进行统计分析。

三、学后反思
- pynlpir这个包分词速度还是很快的,但是使用起来有一定的难度。更新license时可以去github上下载,或者本地使用代理下载。
- 导入自定义字典时,注意字典编码要转化为ANSI编码,否则可能会报错。
- 批量分词时,注意文件的路径最好不要有中文,否则也可能无法顺利分词。
- 如果是在Linux上更新Lincense的话,为了保险起见,可以先去github上下载,再进行上传,以确保万无一失。
-
相关阅读:
安卓apk反编译教程
各种大佬写的爬虫相关的框架汇总
设计师找灵感就上这几个网站。
再次安装pytorch
How to choose an industrial vacuum cleaner?
【机器学习】【深度学习】批量归一化(Batch Normalization)
基于java的在线物流管理系统【原创】
C++-Cmake指令:find_library【该命令用于查找库(动态库或者静态库),当构建依赖于第三方库/系统库,可以使用该命令来查找并使用库】
第57篇:创建Nios II工程之Hello_World<三>
rust字符串
- 原文地址:https://blog.csdn.net/henanlion/article/details/136386870
