-
C++入门和基础
目录
前言
C++是一种通用的编程语言,它是C语言的扩展。C++可以进行面向对象编程,支持类、继承、多态等面向对象的特性。它还提供了一些其他的功能,如模板、异常处理、动态内存管理等。C++是一种高级语言,可以用来开发各种应用程序,包括系统软件、桌面应用、游戏、嵌入式系统等。C++具有高性能和高效的特点,广泛应用于工业界和学术界。
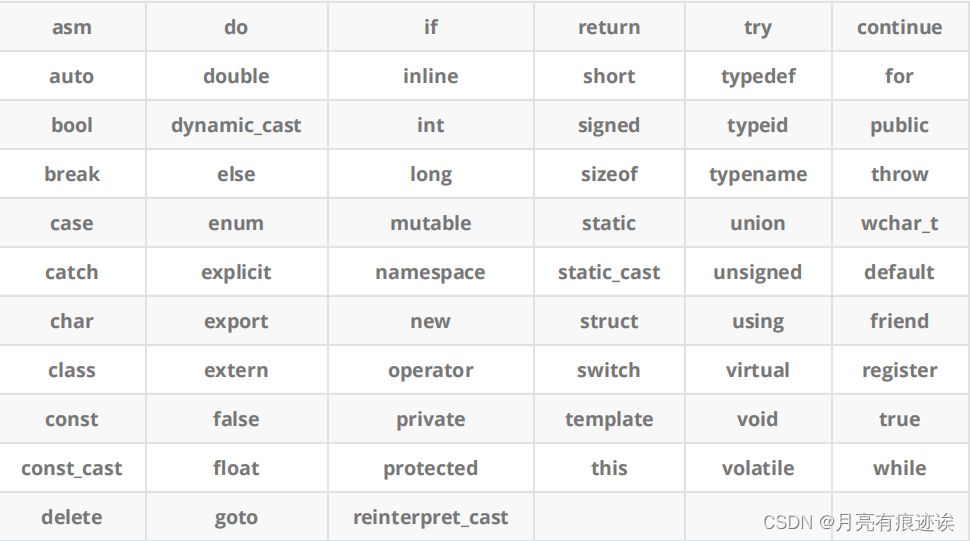
一、C++关键字
C++对比C语言拓展了一些关键字,这里只是简单的给出,不对关键字进行详细的介绍。
二、命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化, 以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
- #include
- #include
- int rand = 10;
- // C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决
- int main()
- {
- printf("%d\n", rand);
- return 0;
- }
- // 编译后后报错:error C2365: “rand”: 重定义;以前的定义是“函数”
2.1 命名空间的定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{} 中即为命名空间的成员。
1.正常的命名空间定义
- namespace hh
- {
- // 命名空间中可以定义变量/函数/类型
- int rand = 10;
- int Add(int left, int right)
- {
- return left + right;
- }
- struct Node
- {
- struct Node* next;
- int val;
- };
- }
2.命名空间可以嵌套
- namespace N1
- {
- int a;
- int b;
- int Add(int left, int right)
- {
- return left + right;
- }
- namespace N2
- {
- int c;
- int d;
- int Sub(int left, int right)
- {
- return left - right;
- }
- }
- }
3.同一个工程中允许存在多个相同名称的命名空间, 编译器最后会合成同一个命名空间中。
ps:下面的代码中的test.h和test.cpp中的两个N1会被合并成一个
- // test.h
- namespace N1
- {
- int Mul(int left, int right)
- {
- return left * right;
- }
- }
- // test.cpp
- namespace N1
- {
- int a;
- int b;
- int Add(int left, int right)
- {
- return left + right;
- }
- namespace N2
- {
- int c;
- int d;
- int Sub(int left, int right)
- {
- return left - right;
- }
- }
- }
注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中。
2.2 命名空间的使用
命名空间的使用有三种方式:
1.加命名空间名称及作用域限定符
- namespace hh
- {
- int a = 6;
- }
- int main()
- {
- int b = hh::a;
- return 0;
- }
2.使用using将命名空间中某个成员引入
- namespace hh
- {
- int a = 6;
- }
- using hh::a;
- int main()
- {
- int b = a;
- return 0;
- }
3.使用using namespace 命名空间名称引入
- namespace hh
- {
- int a = 6;
- }
- using namespace hh;
- int main()
- {
- int b = a;
- return 0;
- }
2.3 标准命名空间
在C++中,标准命名空间(Standard Namespace)是指包含了许多标准库函数、类和对象的命名空间,这些函数、类和对象是C++标准库的一部分。
标准命名空间的名称是
std,它位于全局命名空间中。为了使用标准命名空间中的函数、类或对象,可以使用std::前缀加上相应的名称。例如,使用标准命名空间中的cout和endl:
- #include
- int main() {
- std::cout << "Hello, World!" << std::endl;
- return 0;
- }
在这个例子中,我们使用
std::cout来输出字符串"Hello, World!",使用std::endl来插入一个换行符。为了避免每次都使用
std::前缀,可以使用using namespace std;语句将std命名空间引入到当前作用域中。例如:- #include
- using namespace std;
- int main() {
- cout << "Hello, World!" << endl;
- return 0;
- }
这样就可以直接使用cout和endl,而不需要加上std::前缀。
需要注意的是,使用
using namespace std;可能会引起命名冲突,特别是当引入多个命名空间时。因此,最好只在需要使用大量标准库函数、类和对象时才使用using namespace std;语句,以避免潜在的命名冲突问题。std命名空间的使用惯例:
std是C++标准库的命名空间,如何展开std使用更合理呢?
1. 在日常练习中,建议直接using namespace std即可,这样就很方便。
2. using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对象/函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间 + using std::cout展开常用的库对象/类型等方式。
三、C++输入&输出
在C++中,可以使用标准库中的iostream头文件来进行输入输出操作。
- #include
- using namespace std;
- int main()
- {
- cout << "Hello world!!!" << endl;
- return 0;
- }
说明:
- 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件以及按命名空间使用方法使用std。
- cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含
头文件中。 - << 是流插入运算符, >> 是流提取运算符。
- 使用C++输入输出更方便,不需要像printf / scanf输入输出时那样,需要手动控制格式。C++的输入输出可以自动识别变量类型。
- 实际上cout和cin分别是ostream和istream类型的对象, >> 和 << 也涉及运算符重载等知识,但这里只是简单学习他们的使用。
- #include
- using namespace std;
- int main()
- {
- int a;
- double b;
- char c;
- // 可以自动识别变量的类型
- cin >> a;
- cin >> b >> c;
- cout << a << endl;
- cout << b << " " << c << endl;
- return 0;
- }
ps:关于cout和cin还有很多更复杂的用法,比如控制浮点数输出精度,控制整形输出进制格式等等。因为C++兼容C语言的用法,这些又用得不是很多,我们这里就不展开讲解了。
四、缺省参数
4.1 缺省参数的概念
在C++中,缺省参数(Default Arguments)允许我们在函数声明或定义时为参数提供默认值。这意味着在调用函数时,如果没有为这些参数提供实际的值,则会使用默认值。
使用缺省参数可以使函数调用更加简洁,可以省略一些常用的参数,同时还能提供一些默认行为。
下面是一个使用缺省参数的函数示例:
- void Func(int a = 0)
- {
- cout << a << endl;
- }
- int main()
- {
- Func(); // 没有传参时,使用参数的默认值
- Func(10); // 传参时,使用指定的实参
- return 0;
- }
4.2 缺省参数的分类
- 全缺省参数
- void Func(int a = 10, int b = 20, int c = 30)
- {
- cout << "a = " << a << endl;
- cout << "b = " << b << endl;
- cout << "c = " << c << endl << endl;
- }
- int main()
- {
- Func(1, 2, 3);
- Func(1, 2);
- Func(1);
- Func();
- return 0;
- }
- 半缺省参数
- void Func(int a, int b = 20, int c = 30)
- {
- cout << "a = " << a << endl;
- cout << "b = " << b << endl;
- cout << "c = " << c << endl << endl;
- }
- int main()
- {
- Func(1, 2, 3);
- Func(1, 2);
- Func(1);
- return 0;
- }
注意:
- 半缺省参数必须从右往左依次来给出,不能间隔着给
- 缺省参数不能在函数声明和定义中同时出现,如果声明和定义分明,则应该在声明处给出
- 缺省值必须是常量或者全局变量
五、函数重载
5.1 函数重载的简介
在C++中,函数重载(Function Overloading)是指在同一个作用域内定义多个具有相同名称但参数列表不同的函数。这允许我们使用相同的函数名来执行不同的操作,根据函数参数的个数、类型或顺序的不同来选择正确的函数调用。
函数重载的特点如下:
- 函数名称相同,但参数列表不同。
- 参数列表可以有不同的类型、个数和顺序。
- 如果两个函数函数名和参数是一样的,返回值不同是不构成重载的,因为调用时编译器没办法区分。
需要注意的是,函数重载是在编译期间由编译器进行解析,而不是在运行时。编译器根据函数调用中传递的参数类型、个数和顺序来选择正确的函数。如果没有找到与函数调用匹配的函数,将会发生编译错误。
函数重载可以提高代码的可读性和可维护性,可以为不同的数据类型或参数组合提供适用的函数实现。但是在函数重载时,需要注意避免产生二义性的情况,即避免出现多个函数重载的参数列表相互之间存在模糊的匹配关系。
5.2 函数重载的分类
1.参数类型不同
- int Add(int left, int right)
- {
- cout << "int Add(int left, int right)" << endl;
- return left + right;
- }
- double Add(double left, double right)
- {
- cout << "double Add(double left, double right)" << endl;
- return left + right;
- }
2.参数个数不同
- void f()
- {
- cout << "f()" << endl;
- }
- void f(int a)
- {
- cout << "f(int a)" << endl;
- }
3.参数类型顺序不同(本质还是类型不同)
- void f(int a, char b)
- {
- cout << "f(int a,char b)" << endl;
- }
- void f(char b, int a)
- {
- cout << "f(char b, int a)" << endl;
- }
六、引用
6.1 引用的概念
在C++中,引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。通过引用,可以使用不同的名称访问同一个对象或函数,而不需要拷贝对象本身。引用提供了一种方便且高效的访问变量或函数的方式。引用在函数调用中可以做参数也可以做返回值。
引用语法:
类型 & 引用变量名 ( 对象名 ) = 引用实体;- void TestRef()
- {
- int a = 10;
- int& ra = a; // 定义引用类型
- printf("%p\n", &a);
- printf("%p\n", &ra);
- }
引用的特性:
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
- void TestRef()
- {
- int a = 10;
- // int& ra; // 该条语句编译时会出错
- int& ra = a;
- int& rra = a;
- printf("%p %p %p\n", &a, &ra, &rra);
- }
6.2 常引用
常引用是指在声明引用时,使用
const关键字限定引用所绑定的对象不能被修改。常引用提供了一种只读访问对象的方式,防止意外修改对象的值。常引用常常用于函数参数传递,可以防止函数内部对传递的对象进行修改。- void print(const int& num)
- {
- // 使用常引用作为函数参数
- std::cout << num << std::endl;
- }
- int main()
- {
- int num = 10;
- const int& ref1 = num; // 常引用,绑定到非常对象num
- int num2 = 20;
- const int& ref2 = num2; // 常引用,绑定到非常对象num2
- const int constant = 30;
- const int& ref3 = constant; // 常引用,绑定到常对象constant
- // ref1 = 15; // 错误,常引用不允许修改所绑定的对象的值
- // ref2 = 25; // 错误,常引用不允许修改所绑定的对象的值
- const int& value = ref1 + ref3; // ref1 + ref3表达式的返回值是临时对象,临时对象具有常性
- std::cout << value << std::endl;
- print(10); // 通过常引用访问num的值
- print(num2); // 通过常引用访问num2的值
- print(constant); // 通过常引用访问constant的值
- return 0;
- }
6.3 引用使用场景
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。所以,我们可以使用引用来做参数和返回值。
1.做参数(a、输出型参数 b、对象比较大,减少拷贝,提高效率)这些效果,指针也可以,但是引用更方便,下面是输出型参数的例子:
- void Swap(int& left, int& right)
- {
- int temp = left;
- left = right;
- right = temp;
- }
做参数时传值和传引用的效率比较:
- #include
- #include
- using namespace std;
- struct A
- {
- int a[10000] = { 0 };
- };
- void TestFunc1(A a) {}
- void TestFunc2(A& a) {}
- int main()
- {
- A a;
- // 以值作为函数参数
- size_t begin1 = clock();
- for (size_t i = 0; i < 10000; ++i)
- TestFunc1(a);
- size_t end1 = clock();
- // 以引用作为函数参数
- size_t begin2 = clock();
- for (size_t i = 0; i < 10000; ++i)
- TestFunc2(a);
- size_t end2 = clock();
- // 分别计算两个函数运行结束后的时间
- cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
- cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
- return 0;
- }
2.做返回值(a、修改返回对象 b、减少拷贝提高效率)
- int& Count()
- {
- static int n = 0;
- n++;
- // ...
- return n;
- }
做参数时传值和传引用的效率比较:
- #include
- #include
- using namespace std;
- struct A { int a[10000]; };
- A a;
- // 值返回
- A TestFunc1() { return a; }
- // 引用返回
- A& TestFunc2() { return a; }
- int main()
- {
- // 以值作为函数的返回值类型
- size_t begin1 = clock();
- for (size_t i = 0; i < 100000; ++i)
- TestFunc1();
- size_t end1 = clock();
- // 以引用作为函数的返回值类型
- size_t begin2 = clock();
- for (size_t i = 0; i < 100000; ++i)
- TestFunc2();
- size_t end2 = clock();
- // 计算两个函数运算完成之后的时间
- cout << "TestFunc1 time:" << end1 - begin1 << endl;
- cout << "TestFunc2 time:" << end2 - begin2 << endl;
- return 0;
- }
注意:如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。下面是一个错误示范:
- // 错误示范
- int& func()
- {
- int a = 0;
- return a;
- }
- int& fx()
- {
- int b = 100;
- return b;
- }
- int main()
- {
- int& ret = func();
- cout << ret << endl;
- fx();
- cout << ret << endl;
- return 0;
- }
6.4 引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
- int main()
- {
- int a = 10;
- int& ra = a; //语法不开空间,底层开空间
- ra = 20;
- int* pa = &a; //语法开空间,底层开空间
- *pa = 20;
- return 0;
- }
我们来看下引用和指针的汇编代码对比:
引用和指针的不同点:
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
七、内联函数
内联函数(Inline Functions)是一种特殊类型的函数,在C++中使用关键字
inline来声明。内联函数的特点是在每个调用点上将函数的代码插入到调用点上,而不是通过函数调用的方式进行执行。这样可以减少函数调用的开销,提高程序的执行效率。内联函数的使用场景是在函数体相对简短的情况下,例如只有几行代码的函数,或者函数频繁被调用的情况下。内联函数一般适用于对函数调用时间敏感的场景,可以减少函数调用的开销,提高程序的执行速度。
下面是一个简单的内联函数的示例:
- #include
- // 声明内联函数
- inline int add(int a, int b) {
- return a + b;
- }
- int main() {
- int result = add(3, 4);
- std::cout << "Result: " << result << std::endl; // 输出: Result: 7
- return 0;
- }
在上面的例子中,我们使用
inline关键字声明了一个名为add的内联函数。这个函数只有一行代码,将两个整数相加并返回结果。在main函数中,我们直接调用了内联函数add,而不是通过函数调用的方式进行执行。需要注意的是,内联函数只是对编译器的建议,并不是强制性要求。编译器会根据自身的策略来决定是否将函数作为内联函数来实现。如果函数体过于复杂或函数体内有循环、递归等不适合内联的情况,编译器可能会忽略
inline关键字,将函数按照普通函数的方式进行调用。此外,使用内联函数时需要注意以下几点:
- 内联函数通常适用于函数体简短的情况。
- 内联函数的定义通常放在头文件中,以便能够在使用时进行内联展开。
- 内联函数的编译产生的代码体积可能会增大,因为函数的代码被插入到每个调用点上。
- 内联函数的使用可以提高程序的执行效率,但也可能导致可执行文件的体积增大。
- 内联函数不能递归调用自身。
-
inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到
总的来说,内联函数是一种用于提高程序执行效率的机制,适用于函数体较短且被频繁调用的情况。使用内联函数可以减少函数调用的开销,提高程序的执行速度。
八、auto关键字(C++11)
8.1 auto的使用简介
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的 是一直没有人去使用它,大家可思考下为什么?
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一 个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法。
- int TestAuto()
- {
- return 10;
- }
- int main()
- {
- int a = 10;
- auto b = a;
- auto c = 'a';
- auto d = TestAuto();
- cout << typeid(b).name() << endl;
- cout << typeid(c).name() << endl;
- cout << typeid(d).name() << endl;
- //auto e; 无法通过编译,使用auto定义变量时必须对其进行初始化
- return 0;
- }
【注意】
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto 的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编 译期会将auto替换为变量实际的类型。
8.2 auto的使用细则
1. auto与指针和引用结合起来使用
用auto声明指针类型时,用auto和auto* 没有任何区别,但用auto声明引用类型时则必须加&
- int main()
- {
- int x = 10;
- auto a = &x;
- auto* b = &x;
- auto& c = x;
- cout << typeid(a).name() << endl;
- cout << typeid(b).name() << endl;
- cout << typeid(c).name() << endl;
- *a = 20;
- *b = 30;
- c = 40;
- return 0;
- }
2.在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
- void TestAuto()
- {
- auto a = 1, b = 2;
- auto c = 3, d = 4.0; // 该行代码会编译失败,因为c和d的初始化表达式类型不同
- }
3.auto不能作为函数的参数
- // 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
- void TestAuto(auto a)
- {}
4.auto不能直接用来声明数组
- // 编译失败
- void TestAuto()
- {
- int a[] = { 1,2,3 };
- auto b[] = { 4,5,6 };
- }
8.3 基于范围的for循环
对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
- void TestFor()
- {
- int array[] = { 1, 2, 3, 4, 5 };
- for (auto& e : array)
- e *= 2;
- for (auto e : array)
- cout << e << " ";
- }
注意:与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环。
九、指针空值nullptr(C++11)
在良好的C / C++编程习惯中,声明一个变量时最好给该变量一个合适的初始值,否则可能会出现
不可预料的错误,比如未初始化的指针。如果一个指针没有合法的指向,我们基本都是按照如下
方式对其进行初始化:- void TestPtr()
- {
- int* p1 = NULL;
- int* p2 = 0;
- // ……
- }
NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
- #ifndef NULL
- #ifdef __cplusplus
- #define NULL 0
- #else
- #define NULL ((void *)0)
- #endif
- #endif
可以看到,C++中NULL被定义为字面常量0,这使在使用空值的指针时,不可避免的会遇到一些麻烦,比如:
- void f(int)
- {
- cout << "f(int)" << endl;
- }
- void f(int*)
- {
- cout << "f(int*)" << endl;
- }
- int main()
- {
- f(0);
- f(NULL);
- f((int*)NULL);
- return 0;
- }
程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖,如果这里要使用NULL,就只能将NULL强转为(int*)。
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void*)0。
注意:
- 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
- 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
总结
C++作为一种广泛应用的编程语言,具有强大的功能和高效的性能。无论您是编程初学者还是有一定经验的开发者,掌握C++基础知识都能为您的编程之旅打下坚实基础。通过本文的学习,您将能够掌握C++的入门知识,帮助您迅速上手并建立起编程信心。
-
相关阅读:
如何高效管理自己的电脑?文件再多也不乱!
小黑昨晚又内耗了起床来个leetcode:109. 有序链表转换二叉搜索树
鱼类eDNA生物多样性检测重磅来袭!
LeetCode841. Keys and Rooms
基于音频指纹的听歌识曲系统
LeetCode-764. 最大加号标志【动态规划,二维数组】
Spring Security 的 HttpBasic模式 活该被放弃
5. hdfs的界面详解
节点流和处理流详解
【Spring Boot】Day01
- 原文地址:https://blog.csdn.net/Not_sleep_in/article/details/136416277
