-
NLP-词向量、Word2vec
Word2vec
Skip-gram算法的核心部分
我们做什么来计算一个词在中心词的上下文中出现的概率?
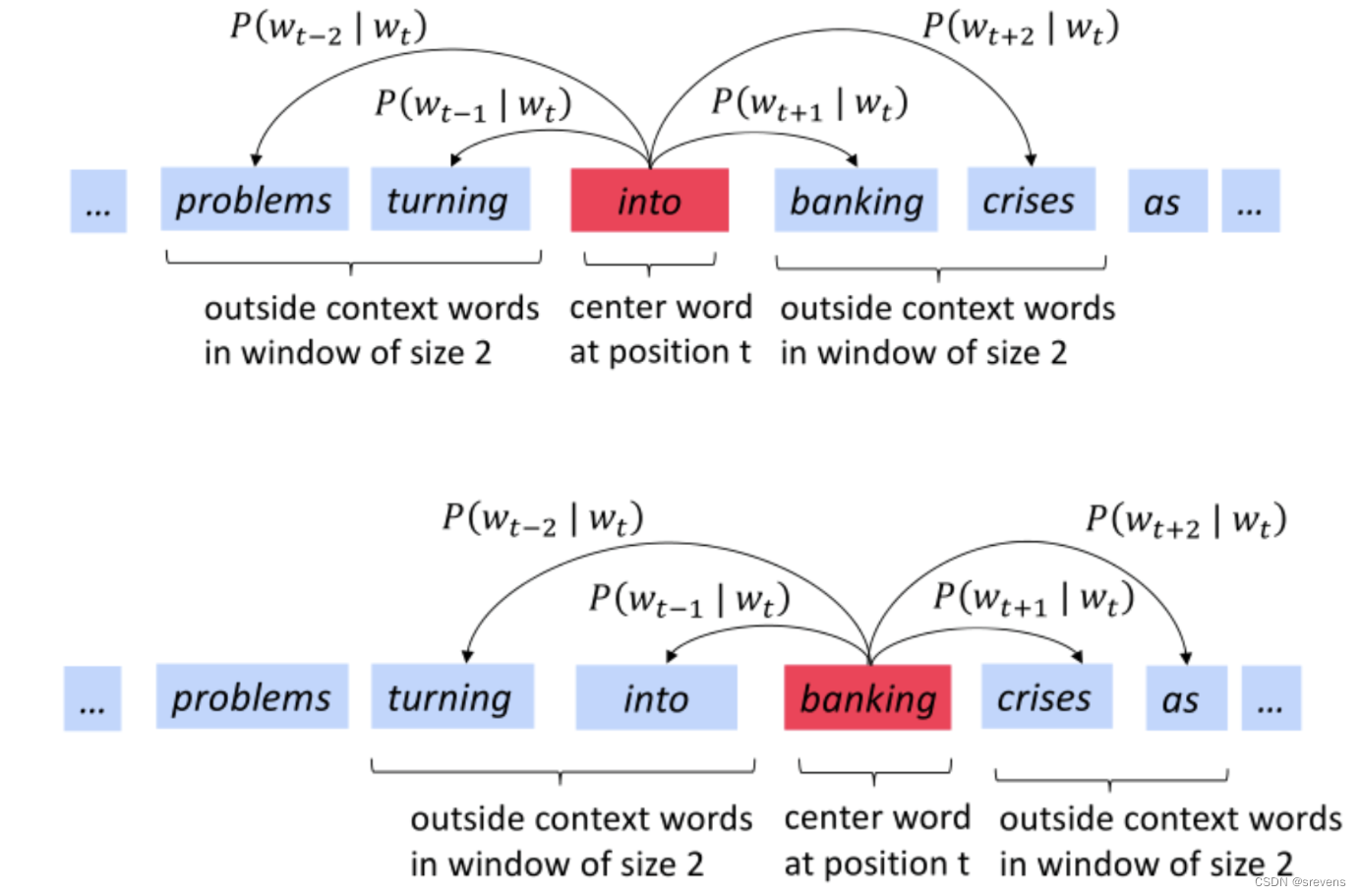
似然函数
词已知,它的上下文单词的概率 相乘。
然后所有中心词的这个相乘数 再全部相乘,希望得到最大。
目标函数(代价函数,损失函数)
平均对数似然 + 转化为极小化问题

最小化目标函数 J(θ) <==> 最大化预测的准确性

- 为了简化数学和优化,每个单词都用两个向量表示:

预测函数
模型训练目的:具有相似上下文的单词,具有相似的向量。
所有上下文之间的向量最相似,这样似然函数最大,损失函数最小!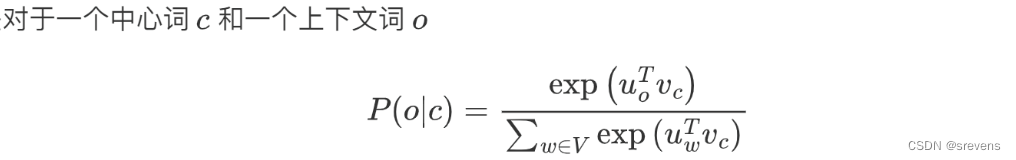
取幂 用于使得所有数都为正
点乘 用于计算向量相似程度。向量之间越相似,点乘结果越大。
目的:找到与中心词向量 点乘最大的词向量,得到最相似的向量。
分母 用于归一化,最终得到概率分布 => 所有词跟中心词的相似程度所构成的概率#预测函数使用的softmax函数
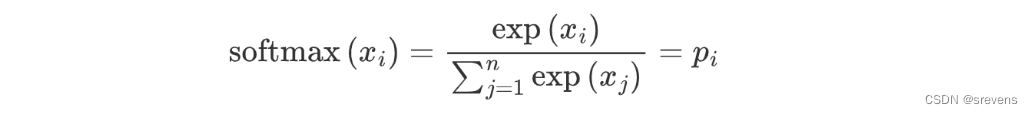
最小化损失函数来调整词向量 -> 最大化 在中心词的上下文实际看到的词的概率

θ表示模型所有的参数,向量长度为2dV。调整θ来最大化上下文词的预测!
词库一共有V个词,每个词向量都是d维。
每个词都有上下文词向量和中心词向量。梯度下降法

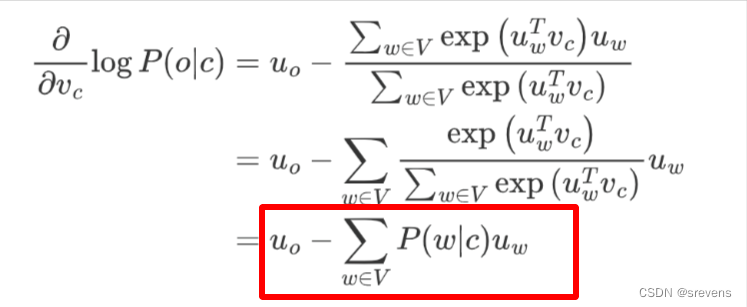

总结:
- 为上下文词和中心词随机初始化一个向量
- 使用迭代算法逐步更新这些词向量 (梯度下降法)
- 可以更好的预测哪些词会出现在其他词的上下文中
- 为了简化数学和优化,每个单词都用两个向量表示:
-
相关阅读:
Oracle -- 视图与序列
Maven3.8.5安装与配置
Pandas数据分析31——全国城市房价分析及样式可视化
K8S配置管理---secret与configmap
Spring Cloud OpenFeign 开启 httpclient5
数学建模:最优化问题及其求解概述
如何使用PS做出大小水泡组合文字效果呢
亚马逊第三大卖家国家巴基斯坦电商营商环境如何?且看跨境电商数字身份验证服务商ADVANCE.AI要参解析
vue3 - swiper插件 实现PC端的 视频滑动功能(仿抖音短视频)
mysql执行拼接的sql语句
- 原文地址:https://blog.csdn.net/stevence112/article/details/136310415