-
Pytorch入门学习写一个简单的分类程序
参考视频:https://www.bilibili.com/video/BV1AP4y167bX/?spm_id_from=333.999.0.0&vd_source=98d31d5c9db8c0021988f2c2c25a9620
网络初学
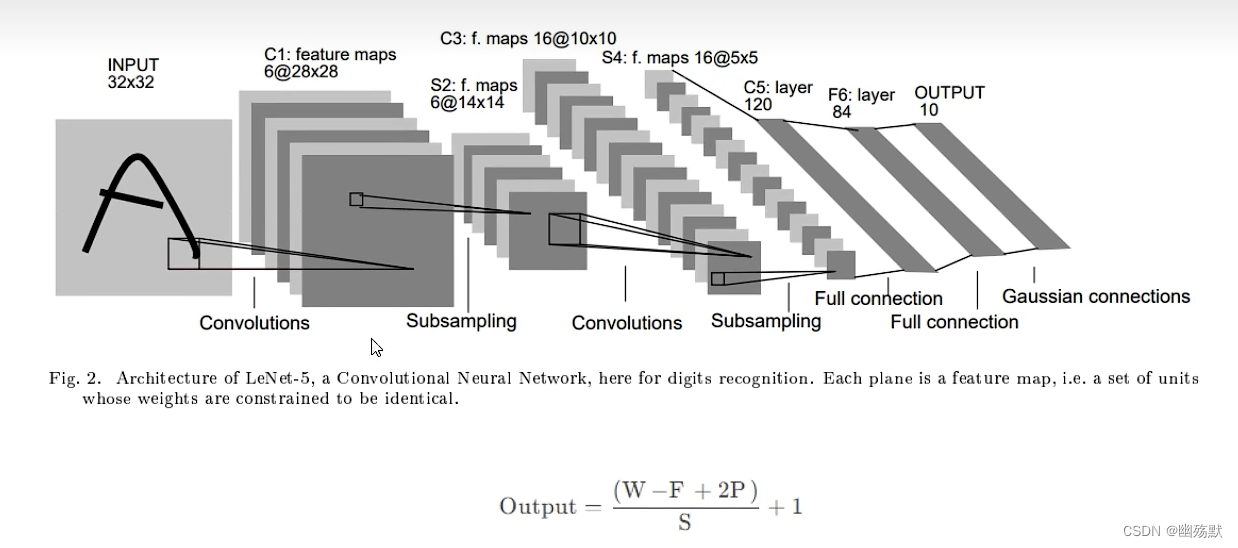
import torch import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1=nn.Conv2d(1,6,5) self.conv2=nn.Conv2d(6,16,5) self.fc1=nn.Linear(16*5*5,120) self.fc2=nn.Linear(120,84) self.fc3=nn.Linear(84,10) def forward(self,x): #x : tensor[batch,channel,H,W] #假设这里的x的维度是(1,1,32,32) x=self.conv1(x)#x的维度是(1,6,28,28) x=F.relu(x)#x的维度是(1,6,28,28) x=F.max_pool2d(x,(2,2))#x的维度是(1,6,14,14) x=F.max_pool2d(F.relu(self.conv2(x)),2)#(1,6,14,14)->(1,16,10,10)->(1,16,5,5) x=x.view(-1,x.size()[1:].numel())#(1,16,5,5)-->(1,16*5*5) x=F.relu(self.fc1(x))#(1,16*5*5)->(1,120) x=F.relu(self.fc2(x))#(1,120)->(1,84) x=self.fc3(x)#(1,84)->(1,10) return x net=Net() print(net) a=torch.randn(1,1,32,32) b=net(a) print(b.size())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
简单的分类程序
环境配置:
conda create -n szh python=3.8 conda install pytorch==1.6.0 cudatoolkit=10.1 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ conda install torchvision -c pytorch pip install matplotlib- 1
- 2
- 3
- 4
项目开发的主要流程是:
- 用torch的torchvision加载初始化数据集。
- 定义卷积神经网络。
- 定义损失函数。
- 根据训练数据训练网络。
- 测试数据上测试网络。
项目结构:
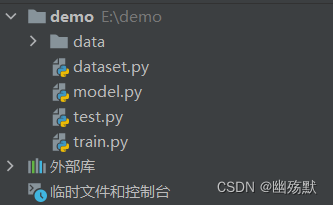
data文件是运行后自动生成的用来保存数据集。
dataset.py""" Dataset 定义好数据的格式和数据变换形式 Dataloader 用iterative的方式不断读入批次数据 """ import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np transform=transforms.Compose( [ transforms.ToTensor(), transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) ] ) trainset=torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform) testset=torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=transform) trainloader=torch.utils.data.DataLoader( trainset,batch_size=4,shuffle=True,num_workers=0 ) testloader=torch.utils.data.DataLoader( testset,batch_size=4,shuffle=False,num_workers=0 ) classes=('airplane','automobile','bird','cat','deer','dog','frog','horse','ship','truck') def imshow(img): img=img/2 +0.5#unnormalize npimg=img.numpy() plt.imshow(np.transpose(npimg,(1,2,0))) plt.show() plt.savefig('1.jpg') plt.close() if __name__ == '__main__':#测试数据集是否正确的加载成功 dataiter = iter(trainloader) images, labels = dataiter.next() imshow(torchvision.utils.make_grid(images)) print(labels) print(labels[0], classes[labels[0]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
model.py
import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim class Net(nn.Module):#分类的主干网络 def __init__(self): super(Net, self).__init__() self.conv1=nn.Conv2d(3,6,5) self.conv2=nn.Conv2d(6,16,5) self.fc1=nn.Linear(16*5*5,120) self.fc2=nn.Linear(120,84) self.fc3=nn.Linear(84,10) def forward(self,x): #x : tensor[batch,channel,H,W] #假设这里的x的维度是(1,1,32,32) x=self.conv1(x)#x的维度是(1,6,28,28) x=F.relu(x)#x的维度是(1,6,28,28) x=F.max_pool2d(x,(2,2))#x的维度是(1,6,14,14) x=F.max_pool2d(F.relu(self.conv2(x)),2)#(1,6,14,14)->(1,16,10,10)->(1,16,5,5) x=x.view(-1,x.size()[1:].numel())#(1,16,5,5)-->(1,16*5*5) x=F.relu(self.fc1(x))#(1,16*5*5)->(1,120) x=F.relu(self.fc2(x))#(1,120)->(1,84) x=self.fc3(x)#(1,84)->(1,10) return x- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
train.py
import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from model import Net transform=transforms.Compose( [ transforms.ToTensor(), transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) ] ) trainset=torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform) testset=torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=transform) trainloader=torch.utils.data.DataLoader( trainset,batch_size=4,shuffle=True,num_workers=0 ) testloader=torch.utils.data.DataLoader( testset,batch_size=4,shuffle=False,num_workers=0 ) net=Net() criterion=nn.CrossEntropyLoss() optimizer=optim.SGD(net.parameters(),lr=0.001,momentum=0.9) for epoch in range(2): running_loss=0.0 for i,data in enumerate(trainloader,0): inputs,labels=data optimizer.zero_grad() outputs=net(inputs) loss=criterion(outputs,labels) loss.backward() optimizer.step() running_loss+=loss.item() if i%2000 ==1999: print("[%d,%5d] loss:%.3f" % (epoch+1,i+1,running_loss/2000)) running_loss=0.0 print("Finish") PATH='./cifar_net.pth' torch.save(net.state_dict(),PATH)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
test.py
import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from model import Net transform=transforms.Compose( [ transforms.ToTensor(), transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) ] ) trainset=torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform) testset=torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=transform) trainloader=torch.utils.data.DataLoader( trainset,batch_size=4,shuffle=True,num_workers=0 ) testloader=torch.utils.data.DataLoader( testset,batch_size=4,shuffle=False,num_workers=0 ) net=Net() PATH='./cifar_net.pth' net.load_state_dict(torch.load(PATH)) correct=0 total=0 with torch.no_grad(): for data in testloader: images,labels=data outputs=net(images) _,predicted=torch.max(outputs,1) total+=labels.size(0) correct+=(predicted==labels).sum().item() correctGailv=100*(correct/total) print(correctGailv)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
-
相关阅读:
ssm健康饮食推荐系统分析与设计毕业设计源码261631
11 假设检验
exoplayer的使用-4,手势,事件监听等
二面被 RocketMQ 虐后,狂刷这套实战到源码手册,再战阿里
产品升级!全球尺度下原核基因组关键基因共进化无标题
A-Level经济真题(12)
数据解析——BeautifulSoup
C++ 类和对象篇(六) 拷贝构造函数
探索 Redis 与 MySQL 的双写问题
LeetCode 731. My Calendar II【设计,有序映射,差分;线段树】中等
- 原文地址:https://blog.csdn.net/bettle_king/article/details/136358279
