-
Ocr之PaddleOcr模型训练
目录
一、系统环境
1 镜像拉取ppocr 进行部署
2 安装paddlepaddle
二、训练前的准备
1 下载源码
2 预模型下载
3 修改模型训练文件yml
4 编排训练集
5 执行脚本进行训练
6 需要修改文件夹名称
三、开始训练
1 执行训练命令
2 对第一次评估进行解释
3 引言
五、总结
一、系统环境
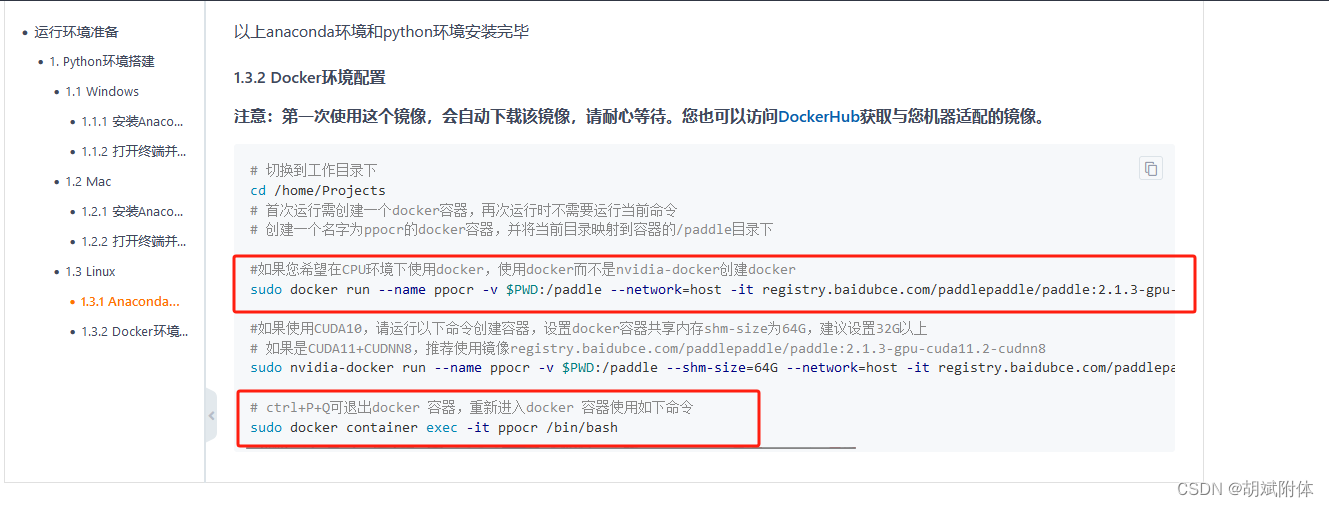
1. 镜像拉取ppocr 进行部署
注:gitee上有提供环境准备的链接【链接】
注:其中用到了下方红框命令
2. 安装paddlepaddle
pip install paddlepaddle- 1
二、训练前的准备
1. 下载源码
切换到 /paddle/目录下 下载源码cd /paddle git clone https://gitee.com/paddlepaddle/PaddleOCR.git # 切换版本 git checkout origin/release/2.7- 1
- 2
- 3
- 4
2. 预模型下载
注:预训练模型:已经训练好的模型。在此模型基础上训练,对生成新的模型进行增强-
模型下载gitee.paddleocr 可直接跳转至下方页面对模型进行下载 这里参考的文章 >> |
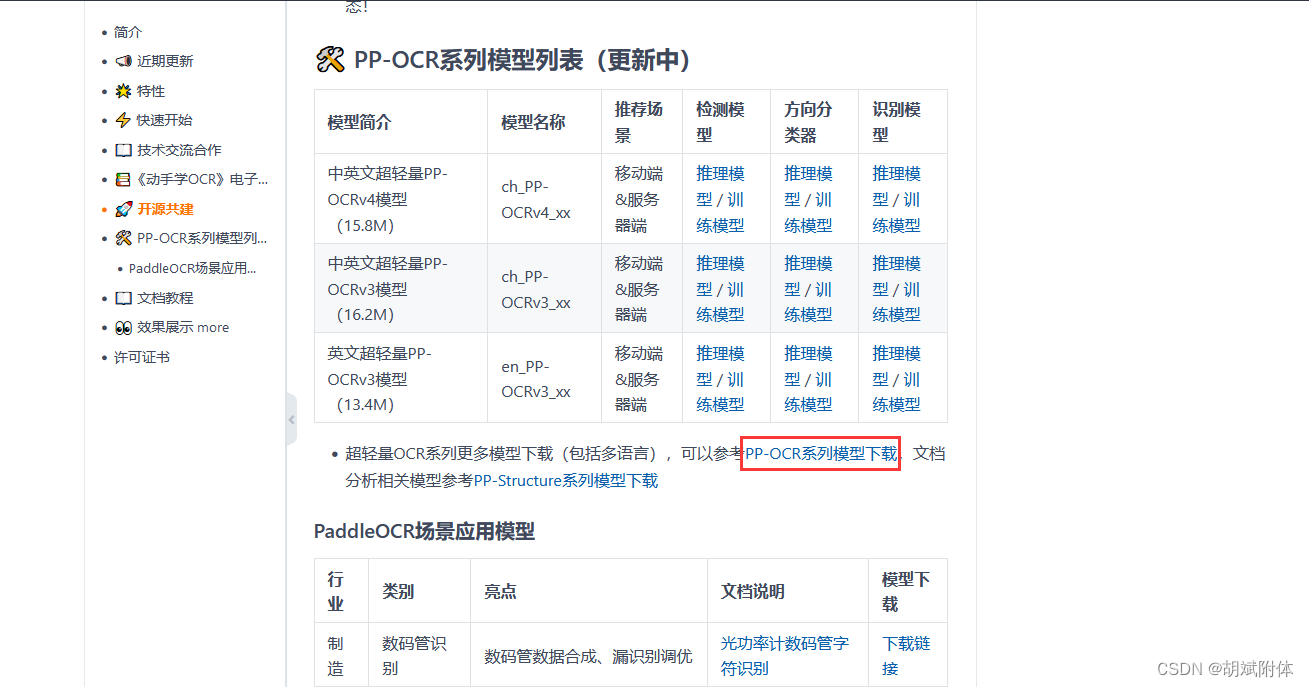
注:进入PP-OCR系列模型下载页面
注:此处下载的训练模型内容是ch_det_mobile_v2.0_det ( 跟随参考文章 )
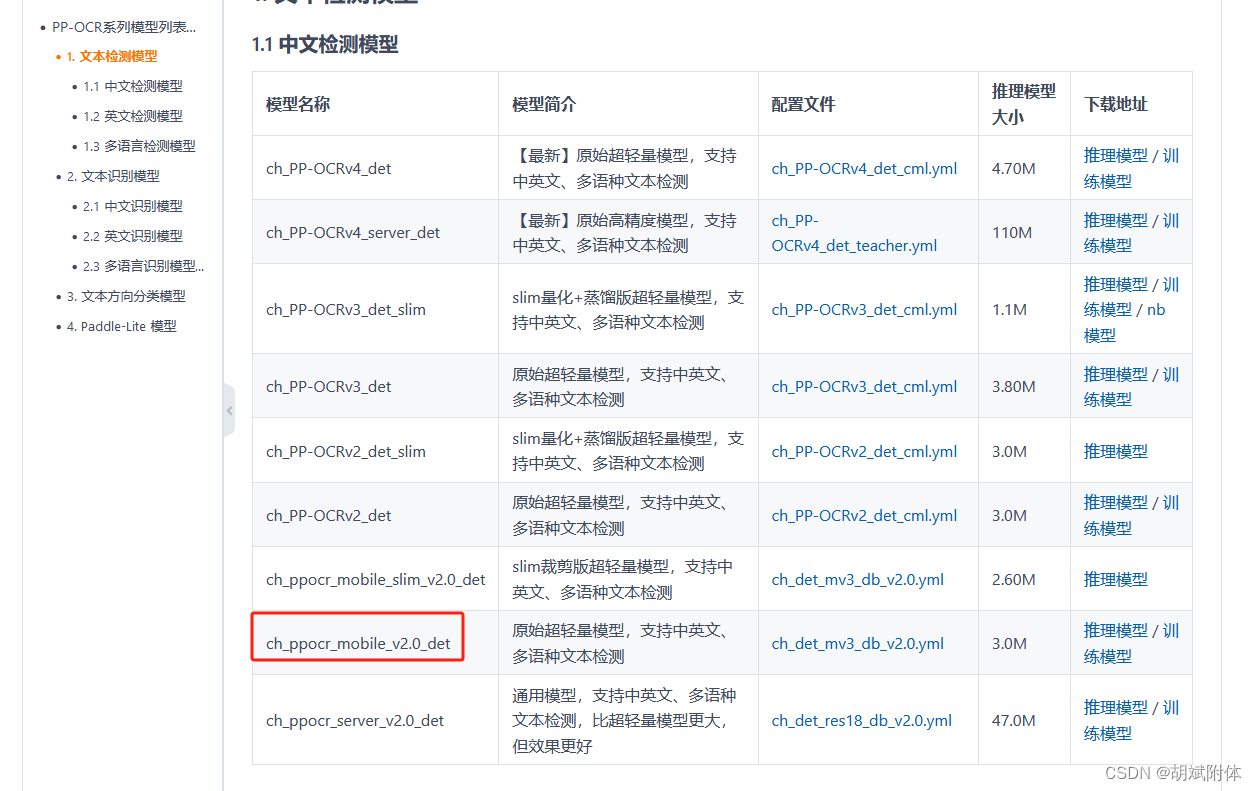
注:首先创建目录mkdir /paddle/PaddleOCR/Preliminary_training- 1
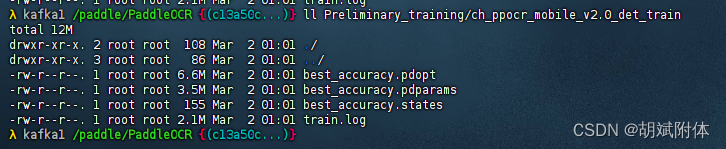
注:可训练自己的数据集,这里跳过,直接使用公开数据集训练自己的数据集 参考文章 >>|
注:公开数据集下载说明 >>|
注:共3部分 下载图片和标注
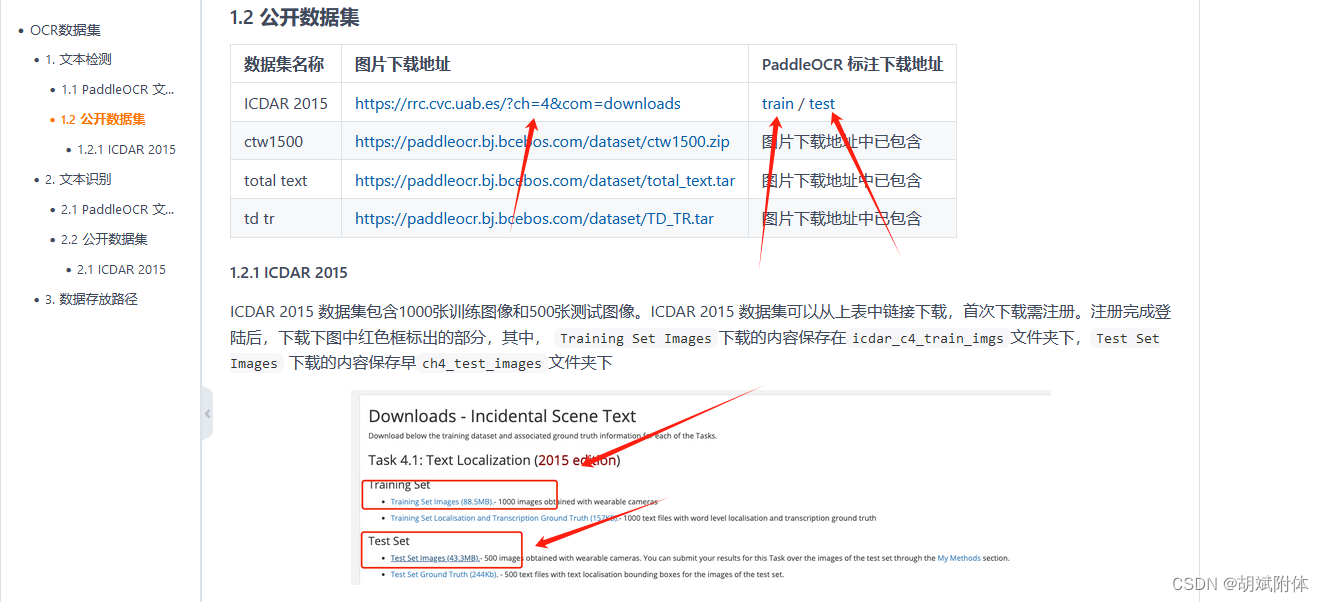
注:进入网站进行下载时需要注册登录
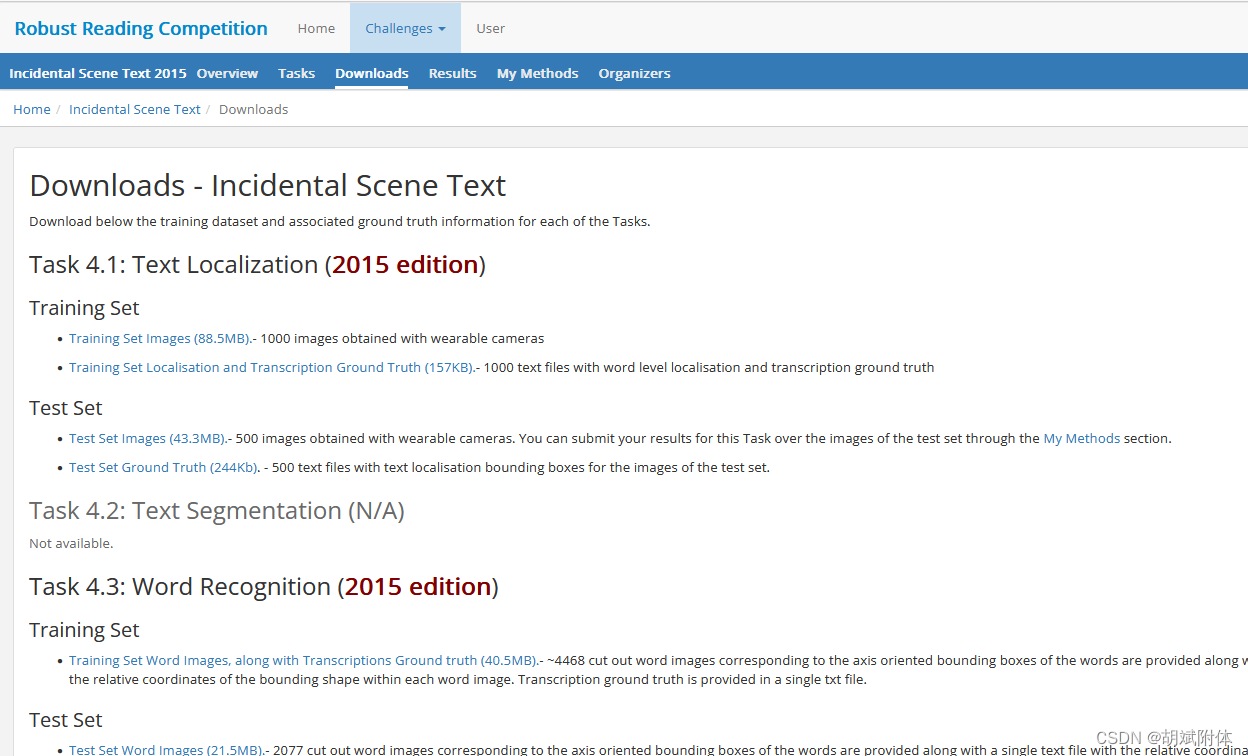
注:下图就是下载后的内容
注:下载的文件需要对文件夹名称做修改(留作彩蛋,文章后面会说)去那 >>|

3. 修改模型训练文件yml
注:修改预训练模型的位置。修改use_gpu: false(因本机使用的是cpu)

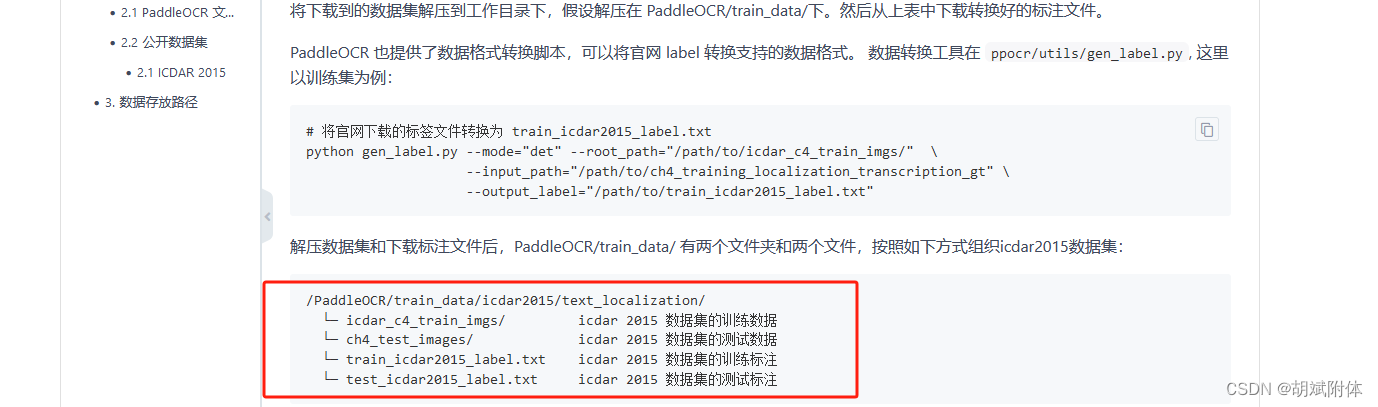
4. 将下载的训练集进行编排
注:编排如图
5. 执行脚本进行训练
注:选择配置文件进行训练,这里选择 ./configs/det/det_mv3_db.yml det_mv3_db的意思基于db和mobileNetV3算法的文本检测配置文件
注:处理执行时遇到的问题- 问题1:处理模块不存在问题
ModuleNotFoundError: No module named 'skimage' , 'imgaug', 'pyclipper', 'tqdm', 'rapidfuzz'
注:安装相关模块进行解决# 安装图像处理模块 pip install scikit-image # 安装图像增强模块 pip install imgaug # 安装形状裁剪模块 pip install pyclipper # 安装嵌入式数据库模块 pip install lmdb # 安装进度条库 pip install tqdm # 安装字符串匹配库 pip install rapidfuzz- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
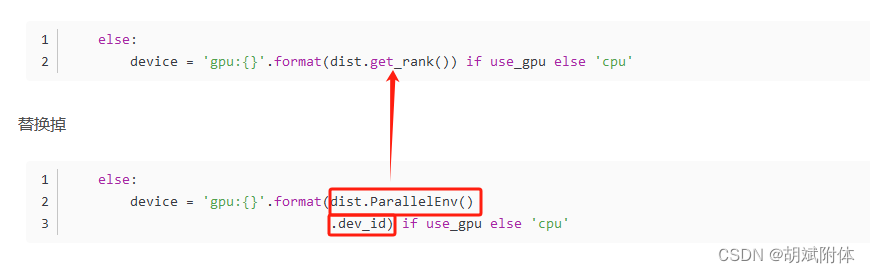
- 问题2:对象无此属性错误

注:编辑报错文件/paddle/PaddleOCR/tools/program.py 进行修改。将dist.ParallelEnv().dev_id 为 dist.get_rank()
错误处理参考文章>> |
6. 修改文件夹名称(彩蛋)
注:修改训练文件夹 ch4_training_images 为 标注文件中(train_icdar2015_label.txt)图片路径的名称 icdar_c4_train_imgs
注:或者修改标注文件的内容也可以,保持一致。避免执行训练脚本时报错

注:查看标注文件 train_icdar2015_label.txtcat ./train_data/icdar2015/text_localization/train_icdar2015_label.txt- 1
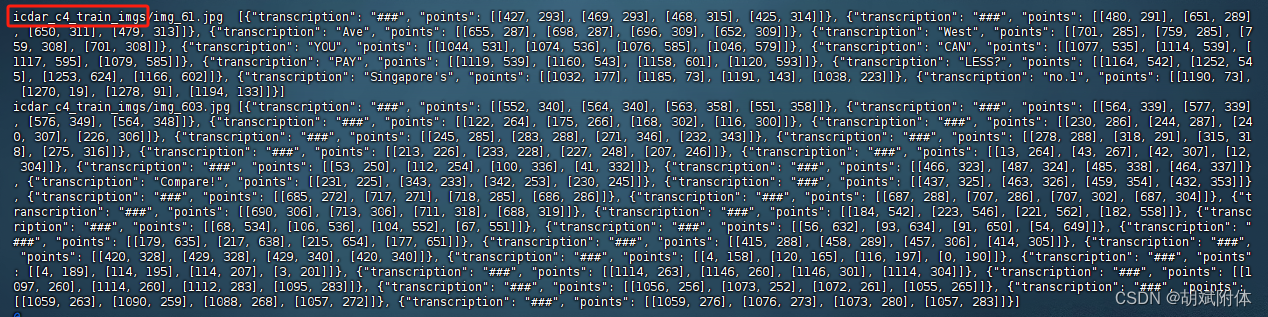
注:故将ch4_training_images 文件夹名称改成 icdar_c4_train_imgs/

三. 开始训练
1. 执行训练命令
python tools/train.py -c configs/det/det_mv3_db.yml- 1
注:解决方案是修改配置文件参数,兼容系统当前系统性能参考 >> |
注:需要修改配置文件 yml参数 num_workers = 0, 避免报错(内存空间不足)。空间足够大cpu核数够高可以尝试修改其他数值(这里没有再进行测试)参考 >> |

python tools/train.py -c configs/det/det_mv3_db.yml- 1

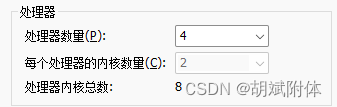
注:cpu配置 4个处理器,2个内核数量
注:内存8G
2. 训练期间第一次评估进行解释
注:使用的文心做的翻译, 向他问了下面这段内容:[2024/03/02 13:36:13] ppocr INFO: epoch: [1/1200], global_step: 10, lr: 0.001000, loss: 8.048188, loss_shrink_maps: 4.862389, loss_threshold_maps: 2.202206, loss_binary_maps: 0.975967, loss_cbn: 0.000000, avg_reader_cost: 0.13627 s, avg_batch_cost: 89.83051 s, avg_samples: 16.0, ips: 0.17811 samples/s, eta: 78 days, 14:11:27- 1
注:最后的 eta 时间很大,果断放弃,看来应该用小一点的训练集去做

3. 引言。
注:后期会训练自定义模型在此更新链接Ocr之PaddleOcr尝试训练自定义模型 >> |五、总结
1. 本篇文章只下载了检测模型进行训练测试。后期还会生成推理模型和对识别模型进行训练并测试并对链接进行更新
- 推理模型生成 >>|
- 识别模型训练 >>|
2. 不同电脑的配置会对模型训练时产生不一样问题。文章中对出现的问题在网上进行搜索,基本都能定位到问题的原因和解决方案。
3. 对模型进行训练的目的。我在工作中使用到了paddleocr识别模型,但是相比较TesseractOCR识别各有千秋。这里希望PaddleOCR能够更好用,所以希望自己能够进一步对他进行训练,期待PaddleOCR能变的更好用。
-
相关阅读:
大数据分析实践 | pandas数据质量分析
JAVA毕业设计好物网站计算机源码+lw文档+系统+调试部署+数据库
RabbitMQ-高级篇-黑马程序员
net-tools 和 iproute2 笔记221103
HMS Core安全检测服务如何帮助大学新生防范电信诈骗?
在github的README.md中插入视频;在github的README.md中添加gif演示动画
el-data-picker限制日期可选范围
【kafka】九、kafka消费者分区分配策略
404、左叶子之和
JavaScript中的闭包
- 原文地址:https://blog.csdn.net/u014642921/article/details/136144843