-
【医学影像】LIDC-IDRI数据集的无痛制作
0.下载
0.0 链接汇总
- LIDC-IDRI官方网址:https://www.cancerimagingarchive.net/nbia-search/?CollectionCriteria=LIDC-IDRI
- NBIA Data Retriever 下载链接:https://wiki.cancerimagingarchive.net/display/NBIA/Downloading+TCIA+Images
0.1 步骤
- 检索
分成两种,Simple Search一个是多种关键字筛选,鉴定为没用。
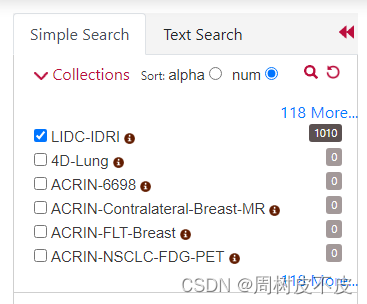
直接用Text Search ,将annotation的ID输上,点击search
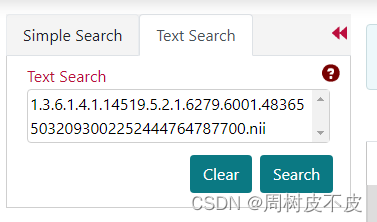
- 加入Cart
检索出来会有好几种模态/任务的数据,选择自己需要点击购物车加入Cart。
例如:我是做CT分割,故只选择模态为CT的那个数据。

重复Text检索步骤,得到最终自己需要的所有Cart:
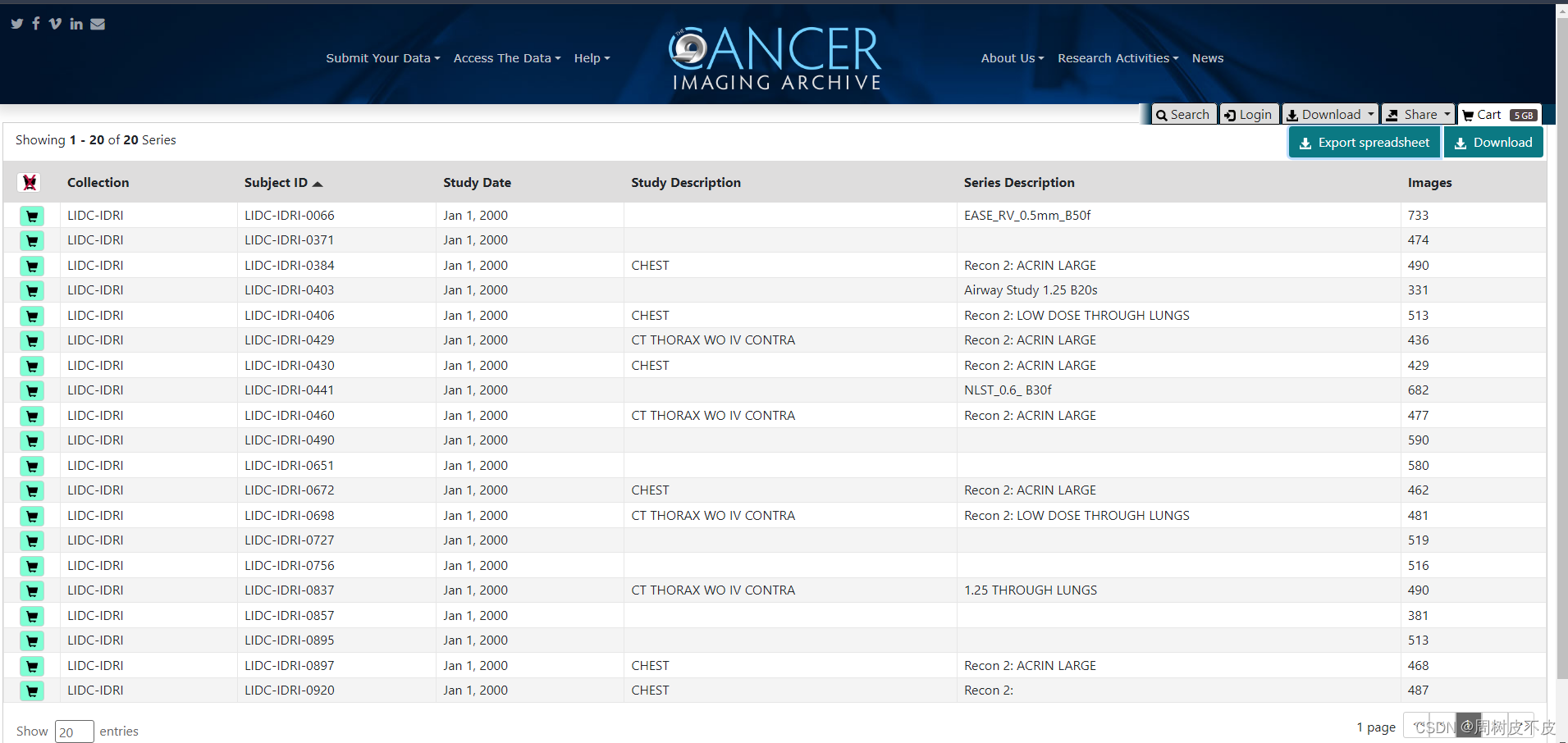
- 下载
-
安装好NBIA Data Retriever
前面链接下载,或者Download->Get NBIA Data Retriever 下载,有官方指引。
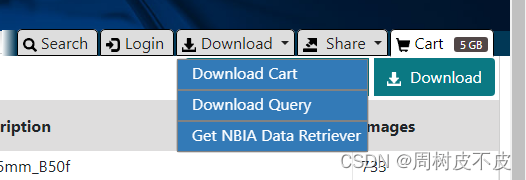
-
生成manifest文件
-
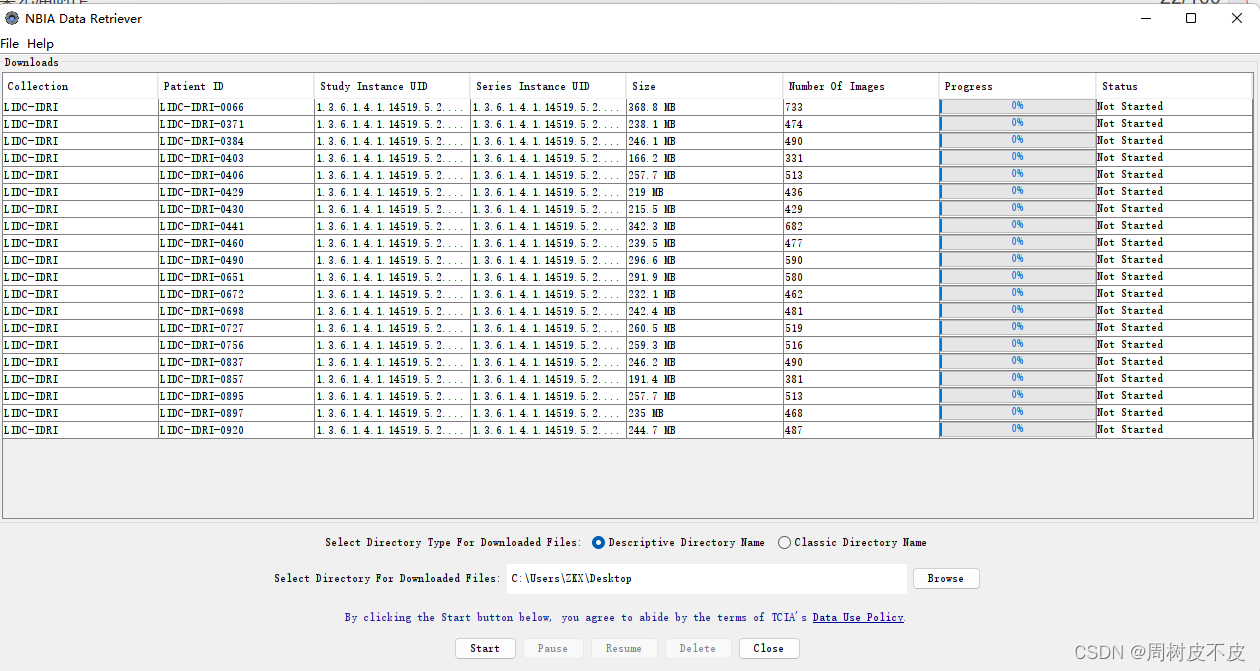
下载
设置好路径,点击start
1.合成CT图
这边是直接偷了NaviAirwayi的代码进行dicom文件merge成nii文件。
文件结构需要为:
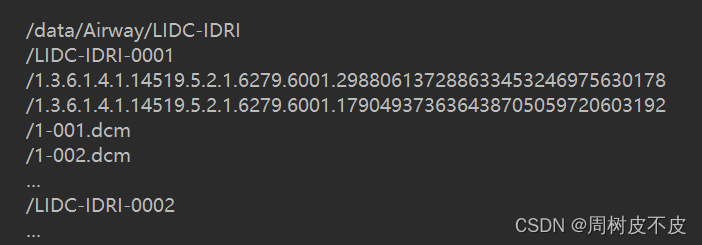
如果按照之前步骤进行下载的话,获得的文件就是上述结构。只是子文件名称会因为太长而被修改,不过不影响结果,最终生成文件名是按照一级目录命名。

预处理代码完整如下:
import numpy as np import os import SimpleITK as sitk from PIL import Image import pydicom import cv2 import nibabel as nib import pydicom ## funtion #####----------------------------------------------------------------------- def loadFile(filename): ds = sitk.ReadImage(filename) #pydicom.dcmread(filename) img_array = sitk.GetArrayFromImage(ds) frame_num, width, height = img_array.shape #print("frame_num, width, height: "+str((frame_num, width, height))) return img_array, frame_num, width, height ''' def loadFileInformation(filename): information = {} ds = pydicom.read_file(filename) information['PatientID'] = ds.PatientID information['PatientName'] = ds.PatientName information['PatientSex'] = ds.PatientSex information['StudyID'] = ds.StudyID information['StudyDate'] = ds.StudyDate information['StudyTime'] = ds.StudyTime information['Manufacturer'] = ds.Manufacturer return information ''' def get_3d_img_for_one_case(img_path_list, img_format="dcm"): img_3d=[] for idx, img_path in enumerate(img_path_list): print("progress: "+str(idx/len(img_path_list))+"; "+str(img_path), end="\r") img_slice, frame_num, _, _ = loadFile(img_path) assert frame_num==1 img_3d.append(img_slice) img_3d=np.array(img_3d) return img_3d.reshape(img_3d.shape[0], img_3d.shape[2], img_3d.shape[3]) #####----------------------------------------------------------------------- # the path to LIDC-IDRI raw images LIDC_IDRI_raw_path = "G:\BAS_test_raw\manifest-1708937949454\LIDC-IDRI" LIDC_IDRI_raw_img_dict = {} img_names = os.listdir(LIDC_IDRI_raw_path) img_names.sort() img_names path_to_a_case = "" def find_imgs(input_path): global path_to_a_case items = os.listdir(input_path) items.sort() # print("There are "+str(items)+" in "+str(input_path)) All_file_flag = True for item in items: if os.path.isdir(input_path + "/" + item): All_file_flag = False break if All_file_flag and len(items) > 10: # print("we get "+str(input_path)) path_to_a_case = input_path else: for item in items: if os.path.isdir(input_path + "/" + item): # print("open filefloder: "+str(input_path+"/"+item)) find_imgs(input_path + "/" + item) for idx, img_name in enumerate(img_names): print(idx / len(img_names), end="\r") find_imgs(LIDC_IDRI_raw_path + "/" + img_name) slice_names = os.listdir(path_to_a_case) slice_names.sort() LIDC_IDRI_raw_img_dict[img_name] = [] for slice_name in slice_names: if slice_name.split(".")[1] == "dcm": LIDC_IDRI_raw_img_dict[img_name].append(path_to_a_case + "/" + slice_name) print("Show the case names: "+str(LIDC_IDRI_raw_img_dict.keys())) # set output path output_image_path = r"G:\myBAS\test\images" if not os.path.exists(output_image_path): os.mkdir(output_image_path) for case in LIDC_IDRI_raw_img_dict.keys(): img_3d = get_3d_img_for_one_case(LIDC_IDRI_raw_img_dict[case]) sitk.WriteImage(sitk.GetImageFromArray(img_3d), output_image_path + "/" + case + ".nii.gz")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
今天折腾了半死,希望对大家有帮助。
reference
-
相关阅读:
Unity 安卓(Android)端AVProVideo插件播放不了视频,屏幕一闪一闪的
Android kotlin开启协程的几种方式
企业电子招标采购系统源码Spring Boot + Mybatis + Redis + Layui + 前后端分离 构建企业电子招采平台之立项流程图
SNAP与Sen2Cor下载与安装
Viola-Jones检测器(VJ)---学习笔记
事务的四大特性----ACID
git修改远程分支名称
maya 设置半径 获取时长,设置时长
Python 时间序列异常点检测 | tsmoothie 基于数据平滑/拟合的方法 简单却快速有效
工程师如何对待开源
- 原文地址:https://blog.csdn.net/weixin_53116058/article/details/136311430
