-
文生图的最新进展:从一致性模型CMs、LCM、SDXL到Stable Diffusion3、SDXL-Lightning
前言
很明显,OpenAI的首个视频生成模型sora极大程度的提高了大家对文生图、文生视频的热情,也极大的扩展了大家对AIGC的想象力
第一部分 一致性模型Consistency Model
注,本文第一部分最早写在23年11月份的这篇文章里《AI绘画神器DALLE 3的解码器:一步生成的扩散模型之Consistency Models》,后因与本文要介绍的LCM关系密切,且也是文生图比较新的进展,故移到本文
1.1 什么是Consistency Models
1.1.1 Consistency Models的背景
关于我为何关注到这个一致性模型,说来话长啊,历程如下
- 我司LLM项目团队于23年11月份在给一些B端客户做文生图的应用时,对比了各种同类工具,发现DALLE 3确实强,加之也要在论文100课上讲DALLE三代的三篇论文,故此文的2.3节中重点写了下DALLE 3的训练细节:AI绘画原理解析:从CLIP、BLIP到DALLE、DALLE 2、DALLE 3、Stable Diffusion
- 在精读DALLE 3的论文时,发现其解码器用到了Consistency Models
当然,后来OpenAI首届开发者大会还正式发布了这个模型,让我对它越发好奇
- Consistency Models的第一作者宋飏也证实了该模型是DALLE 3的解码器
宋飏不算扩散圈的新人,因为早在2019年,斯坦福一在读博士宋飏和其导师通过此文《Generative Modeling by Estimating Gradients of the Data Distribution》提出了一种新方法来构建生成模型:即不需要估计数据的概率分布(数据概率的分布类似高维曲面),相反,它估计的是分布的梯度(分布的梯度可以看成是高维曲面的斜率)
- 至此,已确定必须得研究下这个「AI绘画神器DALLE 3的解码器:一步生成的扩散模型之Consistency Models」了
1.1.2 什么是Consistency Models:何以颠覆原来的扩散模型
根据本博客内之前的文章可知,扩散模型广泛应用于DALLE、stable diffusion等文生图的模型中,但一直以来扩散模型的一个缺点就是采样速度较慢,通常需要100-1000的评估步骤才能抽取一个不错的样本
23年5月,OpenAI的Yang Song、Prafulla Dhariwal、Mark Chen、Ilya Sutskever等人提出了Consistency Models(GitHub地址),相比扩散模型,其使用1个步骤就能获得不错的样本,整体效率至少提升100倍同时也极大地降低了算力成本,其中一作是华人宋飏(其本毕清华,博毕斯坦福)
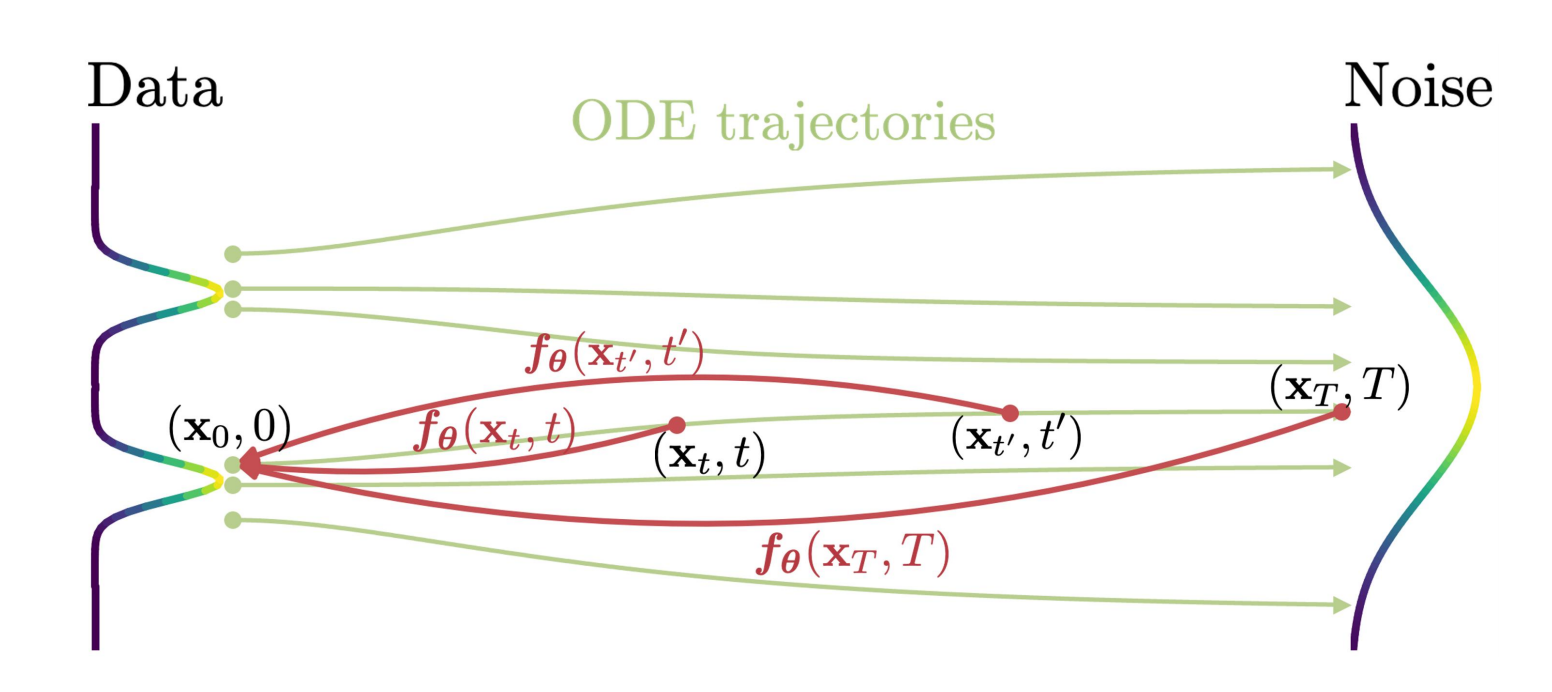
- 其在连续时间扩散模型的概率流(PF)常微分方程(ODE)的基础上,其轨迹平滑过渡,将数据分布转化为可处理的噪声分布
- 通过该一致性模型模型,可将任何时间步长的任何点映射到轨迹的起点
比如给定一个可将“数据”转换为“噪声”概率流(PF) ODE,可将ODE轨迹上的任何点「例如,下图中的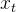 ,
,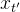 和
和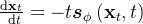 ),映射到它的原点(例如,生成建模的
),映射到它的原点(例如,生成建模的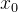 )」。这些映射的模型被称为一致性模型,因为它们的输出被训练为在同一轨迹上的点(有着一致性)
)」。这些映射的模型被称为一致性模型,因为它们的输出被训练为在同一轨迹上的点(有着一致性)
Given a Probability Flow (PF) ODE that smoothlyconverts data to noise, we learn to map any point (e.g., xt,xt1 , and xT ) on the ODE trajectory to its origin (e.g., x0)for generative modeling. Models of these mappings arecalled consistency models, as their outputs are trained to beconsistent for points on the same trajectory

相比扩散模型,它主要有两大优势:
- 其一,无需对抗训练(adversarial training),就能直接生成高质量的图像样本
- 其二,相比扩散模型可能需要几百甚至上千次迭代,一致性模型只需要一两步就能搞定多种图像任务——包括上色、去噪、超分等,都可以在几步之内搞定,而不需要对这些任务进行明确训练(当然,如果进行少样本学习的话,生成效果也会更好)
原理上,一致性模型直接把随机的噪声映射到复杂图像上,输出都是同一轨迹上的同一点,所以实现了一步生成
1.1.3 Consistency Models的两种训练方法
一致性模型有两种训练方法
- 一种是通过蒸馏预训练扩散模型进行训练(Consistency models canbe trained either by distilling pretrained diffusion models)
即先利用数值ODE求解器和预训练的扩散模型来生成PF ODE轨迹上的相邻点对(The first methodrelies on using numerical ODE solvers and a pre-trained diffusion model to generate pairs of adjacent points on a PF ODE trajectory)
之后通过最小化这些相邻点对的之间的差异,我们可以有效地将扩散模型提炼为一致性模型(这允许通过一次网络评估生成高质量的样本)
By minimizing the difference between model outputs for these pairs, we can effectively distill a diffusion model into a consistency model, which allows generating high-quality samples with one network evaluation - 另外一种,也可以完全作为独立的生成模型进行训练
该方法完全消除了对预训练扩散模型的需要,允许我们单独训练一致性模型。这种方法将一致性模型定位为一个独立的生成模型家族
重要的是,这两种方法都不需要对抗性训练,并且它们都对架构施加了较小的约束,允许使用灵活的神经网络对一致性模型进行参数化
实验结果表明,一致性模型在一步和少步采样方面优于现有的蒸馏技术,如渐进式蒸馏,且当作为独立的生成模型进行训练时,一致性模型可以与现有的一步非对抗生成模型在标准基准测试汇总媲美,如CIFAR-10、ImageNet 64×64和LSUN 256×256
2.1 Consistency Models的推导
2.1.1 对扩散模型推导的回顾
首先回顾一下diffusion的算法原理
- 假设我们有数据分布
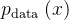 , 扩散模型通过如下的随机微分方程(SDE)对数据分布进行
, 扩散模型通过如下的随机微分方程(SDE)对数据分布进行
Let pdata(x) denote the data distribution. Diffusion models start by diffusing pdata(x) with a stochastic differential equation (SDE)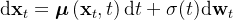
其中,![t \in[0, T]](https://1000bd.com/contentImg/2024/03/06/045612479.png) ,
,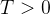 是一个固定的常数,是漂移系数,
是一个固定的常数,是漂移系数,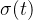 是扩散系数,
是扩散系数,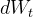 是维纳过程的增量
是维纳过程的增量 - 为了通过该式得到一个常微分方程(ODE),需要消除随机项,在某些扩散模型中,比如Score-Based Generative Models,可以使用概率密度函数
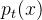 来代替漂移项,进而定义一个无随机项的轨迹,称为ODE轨迹
来代替漂移项,进而定义一个无随机项的轨迹,称为ODE轨迹 - 一致性模型的作者宋飏等人推导出,上述 SDE 存在一个ODE形式的解轨迹(ODE trajectory)
![\mathrm{d} \mathbf{x}_{t}=\left[\boldsymbol{\mu}\left(\mathbf{x}_{t}, t\right)-\frac{1}{2} \sigma(t)^{2} \nabla \log p_{t}\left(\mathbf{x}_{t}\right)\right] \mathrm{d} t](https://1000bd.com/contentImg/2024/03/06/045611615.png)
其中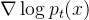 是 的得分函数,而这个得分函数是diffusion model 的直接或者间接学习目标
是 的得分函数,而这个得分函数是diffusion model 的直接或者间接学习目标 - 采用 EDM 中的 setting,设置
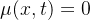 、
、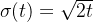 ,训练一个得分模型
,训练一个得分模型
可将上述 ODE 转为 - 得到 ode 的具体形式后,利用现有的数值 ODE solver,如 Euler, Heun, Lms 等,即可解出 x(.)
当然,考虑到数值精确性,我们往往不会直接求出原图即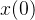 ,而是计算出一个
,而是计算出一个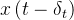 ,持续这个过程来求出
,持续这个过程来求出
// 待更
2.2.2 Consistency Models 的推导与源码解读
// 待更
第二部分 Latent Consistency Models(LCM)
2.1 LCM与通用加速器LCM-LoRA
受到上文的Consistency Models的启发「其采用了一种一致性映射技术,巧妙地将普通微分方程(ODE)轨迹上的点映射到它们的起源,从而实现了快速的一步生成」,清华大学交叉信息研究院一团队(包括骆思勉和谭亦钦等人)于2023年11月推出Latent Consistency Models(潜一致性模型,简称LCM)
其通过将引导的逆扩散过程视为增广概率流ODE(PF-ODE)的解决方案,LCMs能够熟练地预测潜在空间中这些ODE的解(By viewing the guided reverse diffusion process as the resolution of an augmented Probability Flow ODE (PF-ODE), LCMs adeptly predict the solution of such ODEs in latent space),该方法显著减少了迭代步骤的需求
- LCMs是从预训练的潜在扩散模型(LDMs)中提炼出来的(其paper:https://huggingface.co/papers/2311.05556、其项目主页:https://latent-consistency-models.github.io/),仅需要约32个A100 GPU训练小时
- 且考虑到对于专门的数据集,如动漫、照片逼真或幻想图像,还得使用潜在一致性微调LCF对LCM进行微调(或使用潜在一致性蒸馏LCD将预训练的LDM蒸馏为LCM),故为避免这种额外的步骤阻碍LCMs在不同数据集上的快速部署,该团队还提出了LCM-LoRA
使得可以在自定义数据集上实现快速、无需训练的推理,比如可以直接将该LoRA(即通过LCM蒸馏获得的LoRA参数)插入各种稳定扩散模型中,包括SD-V1.5(Rombach等,2022年),SSD-1B(Segmind,2023年)和SDXL(Podell等,2023年)等

和需要多步迭代传统的扩散模型(如Stable Diffusion)不同,LCM仅用1 - 4步即可达到传统模型30步左右的效果,LCM将文生图生成速度提升了5-10倍,世界自此迈入实时生成式AI的时代

2.2 LCM-LORA
潜在一致性模型LCM使用一阶引导蒸馏方法进行训练,利用预训练自编码器的潜在空间将引导扩散模型蒸馏成LCM。该过程涉及解决增强概率流动ODE(PF-ODE,确保生成的样本遵循导致高质量图像的轨迹),以下是LCD的伪代码

由于潜在一致性模型LCM的蒸馏过程是在预训练扩散模型的参数之上进行的,我们可以将潜在一致性蒸馏视为扩散模型的微调过程。因此,能够使用LoRA
LoRA通过应用低秩分解来更新预训练的权重矩阵
- 给定一个权重矩阵
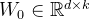 ,更新表示为
,更新表示为 ,其中
,其中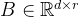 ,
,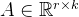 ,且秩
,且秩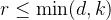
- 在训练过程中,
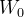 保持不变,只对A和B应用梯度更新,对于输入
保持不变,只对A和B应用梯度更新,对于输入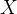 ,修改后的前向传播过程为
,修改后的前向传播过程为
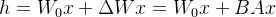
在这个方程中,
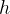 代表输出向量,和
代表输出向量,和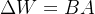 的输出在乘以输入 后相加。 通过将完整的参数矩阵分解为两个低秩矩阵的乘积,LoRA显著减少了可训练参数的数量,从而降低了内存使用量
的输出在乘以输入 后相加。 通过将完整的参数矩阵分解为两个低秩矩阵的乘积,LoRA显著减少了可训练参数的数量,从而降低了内存使用量2.3 LCM与其他类似项目的对比
模型名称
介绍
生成速度
训练难度
SD生态兼容性
DeepFloyd IF
高质量、可生成文字,但架构复杂
更慢
更慢
不兼容
Kandinsky 2.2
比SDXL发布更早且质量同样高;兼容ControlNet
类似
类似
不兼容模型和LoRA,兼容ControlNet等部分插件
Wuerstchen V2
质量和SDXL类似
2x - 2.5x
更容易
不兼容
SSD-1B
由Segmind蒸馏自SDXL,质量略微下降
1.6x
更容易
部分兼容
PixArt-α
华为和高校合作研发,高质量
类似
SD1.5十分之一
兼容ControlNet等部分插件
LCM (SDXL, SD1.5)
训练自DreamShaper、SDXL,高质量、速度快
5x -10x
更容易
部分兼容
LCM-LoRA
体积小易用,插入即加速;牺牲部分质量
5x -10x
更容易
兼容全部SD大模型、LoRA、ControlNet,大量插件
截止至2023/11/22,已支持LCM的开源项目:
- Stable Diffusion发行版,包括WebUI(原生支持LCM-LoRA,LCM插件支持LCM-SDXL)、ComfyUI、Fooocus(LCM-LoRA)、DrawThings
- 小模型:LCM-LoRA兼容其他LoRA,ControlNet
- AnimateDiff WebUI插件
第三部分 Stable Diffusion XL Turbo
3.1 SDXL Turbo:给定prompt 实时响应成图
Stability AI 推出了新一代图像合成模型 Stable Diffusion XL Turbo(其论文地址),使得只用在文本框中输入你的想法,SDXL Turbo 就能够迅速响应,生成对应内容。一边输入,一边生成,内容增加、减少,丝毫不影响它的速度


还可以根据已有的图像,更加精细地完成创作。手中只需要拿一张白纸,告诉 SDXL Turbo 你想要一只白猫,字还没打完,小白猫就已经在你的手中了

SDXL Turbo 模型的速度达到了近乎「实时」的程度,于是有人直接连着游戏,获得了 2fps 的风格迁移画面:
据官方博客介绍,在 A100 上,SDXL Turbo 可在 207 毫秒内生成 512x512 图像(即时编码 + 单个去噪步骤 + 解码,fp16),其中单个 UNet 前向评估占用了 67 毫秒,如此,我们可以判断,文生图已经进入「实时」时代
3.2 SDXL关键技术:对抗扩散蒸馏
3.2.1 两个训练目标:对抗损失和蒸馏损失
在SDXL之前
- 一致性模型(Consistency Models)通过对ODE轨迹施加一致性正则化(by enforcing a consistency regularization on the ODE trajector)来解决即便迭代采样步骤减少到4-8步,依然能保持较好的性能,且在少样本设置下展示了强大的像素模型性能
- 而LCMs专注于在提炼潜在扩散模型并在4个采样步骤中便取得了不错的效果
- 包括LCM-LoRA则引入了一种低秩适应[22]训练方法,以高效学习LCM模块,可以插入到SD和SDXL [50, 54]的不同检查点中(LCMs focus on distilling latent diffusion models and achieve impressive performance at 4 sampling steps. Recently, LCM-LoRA [40] introduced a low-rank adaptation [22] training for efficiently learning LCM modules, which can be plugged into different checkpoints for SD and SDXL [50, 54])
- InstaFlow [36]提出使用修正流[35]来促进更好的蒸馏过程(InstaFlow [36]propose to use Rectified Flows [35] to facilitate a better distillation proces)
但以上这些方法都有共同的缺陷:在4个步骤中合成的样本通常看起来模糊,并且存在明显的伪影
考虑到GANs也可以作为独立的单步模型进行文本到图像合成的训练 [25,59],且采样速度不错,当然,性能落后于基于扩散的模型。那何不在不破坏平衡的情况下,扩展GAN并整合神经网络架构呢?
- 而SDXL则引入了一种名为对抗扩散蒸馏(Adversarial Diffusion Distillation,ADD)的技术,可以在仅1-4步内高效采样大规模基础图像扩散模型,并保持高图像质量(a novel training approach that efficiently samples large-scale foundational image diffusion models in just 1–4 steps while maintaining high image quality)
- 其使用得分蒸馏来利用大规模现成的图像扩散模型作为教师信号,结合对抗性损失,以确保即使在一到两个采样步骤内也能保持高图像保真度(We use score distillation to leverage large-scale off-the-shelf image diffusion models as a teacher signal in combination with an adversarial loss to ensure high image fidelity even in the low-step regime of one or two sampling steps)
具体而言,研究者引入了两个训练目标的组合:

- 对抗损失,对抗损失迫使模型在每次前向传递时直接生成位于真实图像流形上的样本,避免了其他蒸馏方法中常见的模糊和其他伪影
- 分数蒸馏采样SDS 相对应的蒸馏损失,蒸馏损失使用另一个预训练(且固定)的扩散模型作为教师(比如可以使用预训练的扩散模型权重初始化模型),有效利用预训练diffusion model的丰富知识,从而显著改善对抗性损失的训练,类似通过CLIP改善文本对齐
最后,不使用仅解码器的架构来进行GAN训练,而是采用标准的扩散模型框架
3.2.2 训练的具体过程
ADD-student从预训练的UNet-DM中初始化权重
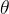 ,具有可训练权重
,具有可训练权重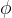 的鉴别器,以及具有冻结权重
的鉴别器,以及具有冻结权重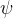 的DM teacher(The ADD-student is initialized from a pretrained UNet-DM with weights θ, a discriminator with trainable weights ϕ, and a DM teacher with frozen weights ψ)
的DM teacher(The ADD-student is initialized from a pretrained UNet-DM with weights θ, a discriminator with trainable weights ϕ, and a DM teacher with frozen weights ψ)在训练过程中
- ADD-student从噪声数据
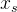 生成样本
生成样本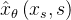 。 噪声数据点是通过正向扩散过程从真实图像数据集 生成的
。 噪声数据点是通过正向扩散过程从真实图像数据集 生成的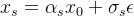 。 在我们的实验中,我们使用与学生DM相同的系数
。 在我们的实验中,我们使用与学生DM相同的系数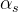 和,并从选择的学生时间步长集合
和,并从选择的学生时间步长集合中均匀采样
- 生成的样本
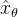 和真实图像被传递给鉴别器Discriminator,鉴别器的目标是区分它们
和真实图像被传递给鉴别器Discriminator,鉴别器的目标是区分它们 - 为了从DM teacher那里获得知识,我们将学生样本通过教师的前向过程扩散到
(we diffuse student samples ˆxθ with the teacher’s forward process toˆxθ,t),并使用教师的去噪预测
作为蒸馏损失的重建目标
(use the teacher’s denoising prediction ˆxψ (ˆxθ,t, t)as a reconstruction target for the distillation loss Ldistill)
因此,总体目标是
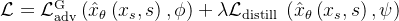
// 待更
第四部分 与sora同架构的Stable Diffusion3
4.1 Stable Diffusion3
stable diffusion的原理在此文《AI绘画原理解析:从CLIP、BLIP到DALLE、DALLE 2、DALLE 3、Stable Diffusion》中已经讲的很清楚了,接下来,我们看下其最新版本SD3
SD3对应的paper为《Scaling Rectified Flow Transformers for High-Resolution Image Synthesis》
// 待更
第五部分 SDXL-Lightning
// 待更
参考文献与推荐阅读
- 图像生成发展起源:从VAE、扩散模型DDPM、DETR到ViT、Swin transformer
- AI绘画原理解析:从CLIP、BLIP到DALLE、DALLE 2、DALLE 3、Stable Diffusion
- 几篇新闻稿
4.13,OpenAI新生成模型开源炸场!比Diffusion更快更强,清华校友一作
11.9,OpenAI上线新功能太强了,服务器瞬间被挤爆
11.11,OpenAI救了Stable Diffusion!开源Dall·E3同款解码器,来自Ilya宋飏等 - Consistency Models
Yang Song, Prafulla Dhariwal, Mark Chen, Ilya Sutskever - 一步生成的扩散模型:Consistency Models
- SDXL Turbo、LCM相继发布,AI画图进入实时生成时代:字打多快,出图就有多快
-
相关阅读:
python基于openpyxl操作excel
基于51单片机的智能病房呼叫系统的设计与实现
Android开发笔记——快速入门(全局大喇叭)
N-129基于springboot,vue学生宿舍管理系统
ArcGIS 10.7软件安装包下载及安装教程!
session共享(redis实现)
机器学习基本概念
C++学习笔记(二十)
k8s-----25、资源调度-ResourceQuota资源配额、资源限制limitrange、服务质量QoS
关于阅读《重构的时机和方法》这本书所带来的启发
- 原文地址:https://blog.csdn.net/v_JULY_v/article/details/136318383