-
机器学习 | 过拟合&欠拟合
本篇内容我们来讨论模型的过拟合和欠拟合问题
一. 过拟合
首先我们来思考,什么是过拟合?
假设,我们有一个由5个样本点组成的训练集:
通过数据分析,我们认为该训练集中的样本不满足线性关系
更倾向于使用一个4次的曲线来拟合所有样本这样做的结果是,我们一定会得到一条曲线经过5个样本点
也就是说:线性回归模型在训练集上可以达到100%的准确率
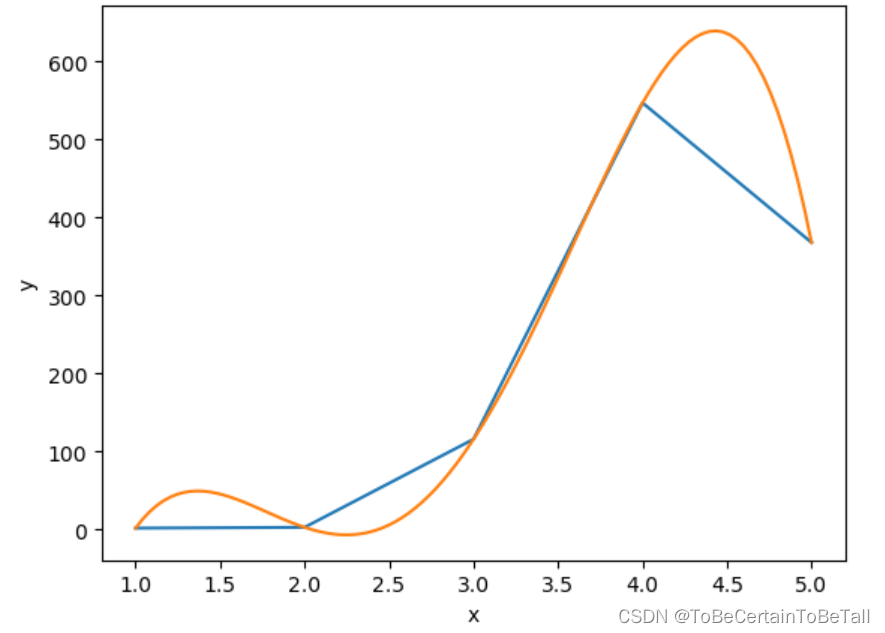
然而,这样的模型在测试集和实际应用中,其准确率远远达不到100%,这种情况也就称为过拟合
产生原因:多项式扩展、模型过于复杂等情况 产生结果:模型学习能力太强,细枝末节的数据也学到了,拟合过度,导致模型准确率下降 过拟合现象:训练集效果非常好,测试集很差- 1
- 2
- 3
1. 正则化(Regularization)
针对线性回归算法的过拟合问题,我们可以用正则化方法来解决
L1正则化&L2正则化 解决思路:
这两种正则化在解决过拟合问题的思路是相同的在求解参数 θ \theta θ(即: θ 0 \theta _{0} θ0, θ 1 \theta _{1} θ1,…, θ n \theta _{n} θn)时,保证其中每个参数的值都不能太大;
若参数值太大,则会给予惩罚,损失函数变大L1正则化&L2正则化 优化算法:
这两个模型在求参数 θ \theta θ时不是梯度下降,而是坐标下降
为了防止过拟合,我们可以在线性回归的损失函数中加入正则化项,即 J ( θ ) = 1 2 ∗ m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) 2 + λ ( Ω ( θ ) ) J(\theta)=\frac{1}{2\ast m}\sum_{i=1}^{m}(\hat{y}^{(i)}-y^{(i)})^{2}+\lambda(\Omega(\theta )) J(θ)=2∗m1i=1∑m(y^(i)−y(i))2+λ(Ω(θ))
1.1 L1正则化
使用L1正则化的回归又被称为Lasso回归(Least Absolute Shrinkage and Selection Operator)
Ω ( θ ) = ∑ j = 1 n ∣ θ j ∣ \Omega (\theta )=\sum_{j=1}^{n}\left | \theta _{j} \right | Ω(θ)=j=1∑n∣θj∣1.2 L2正则化
使用L2正则化的回归又被称为岭回归(Ridge Regression)
Ω ( θ ) = ∑ j = 1 n θ j 2 \Omega (\theta )=\sum_{j=1}^{n}\theta _{j}^{2} Ω(θ)=j=1∑nθj21.3 ElasticNet回归
在无法权衡L1正则化和L2正则化究竟谁更好的前提下,我们可以使用ElasticNet回归,又称弹性网络回归
J ( θ ) = 1 2 ∗ m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) 2 + λ 1 ∑ j = 1 n ∣ θ j ∣ + λ 2 ∑ j = 1 n θ j 2 J(\theta)=\frac{1}{2\ast m}\sum_{i=1}^{m}(\hat{y}^{(i)}-y^{(i)})^{2}+\lambda_{1}\sum_{j=1}^{n}\left | \theta _{j} \right |+\lambda_{2}\sum_{j=1}^{n}\theta _{j}^{2} J(θ)=2∗m1i=1∑m(y^(i)−y(i))2+λ1j=1∑n∣θj∣+λ2j=1∑nθj2公式中的 λ \lambda λ为超参数:
作用: λ \lambda λ大小决定了正则化项发挥作用的大小其中,当 λ \lambda λ=0时,相当于标准线性回归
二. 欠拟合
明白什么是模型的过拟合后,欠拟合就很好理解
假设,我们有一个由10个样本点组成的训练集,模型通过学习后,拟合情况如下:

此时,模型在训练集上的效果很差,这种情况称为欠拟合产生原因:模型复杂度不够,过于简单 产生结果:学习能力不够强,拟合度不够 欠拟合现象:训练集效果很差,测试集效果很差 解决目标:提高模型在训练集上的准确率- 1
- 2
- 3
- 4
1. 解决方式:增加模型复杂度
尝试增加模型的层数或参数数量,使其能更好地拟合数据
具体方法: 多项式扩展- 1
- 2
本篇文章仅涵盖了目前已讨论过的知识点,未来将持续更新
PS:本文相关代码存放位置
波士顿房价预测 正则化代码实现感谢阅读~
-
相关阅读:
使用uwsgi和gunicorn部署Django项目(智能客服系统)
【152.乘积最大子数组】
malloc与free
敏捷Scrum实施落地中的3大典型问题及解法
选择低代码开发,我轻松了不少!
maven打包把代码包和依赖包分开打包
8月6日Pytorch笔记——GAN、WGAN
【数据结构】二叉树的基本概念
Bigemap是如何在生态林业科技行业去应用的
探索arkui(2)--- 布局(列表)--- 1(列表数据的展示)
- 原文地址:https://blog.csdn.net/weixin_49613115/article/details/136268232