-
AI大模型-启航
什么是大模型?(大体现在参数量巨大)
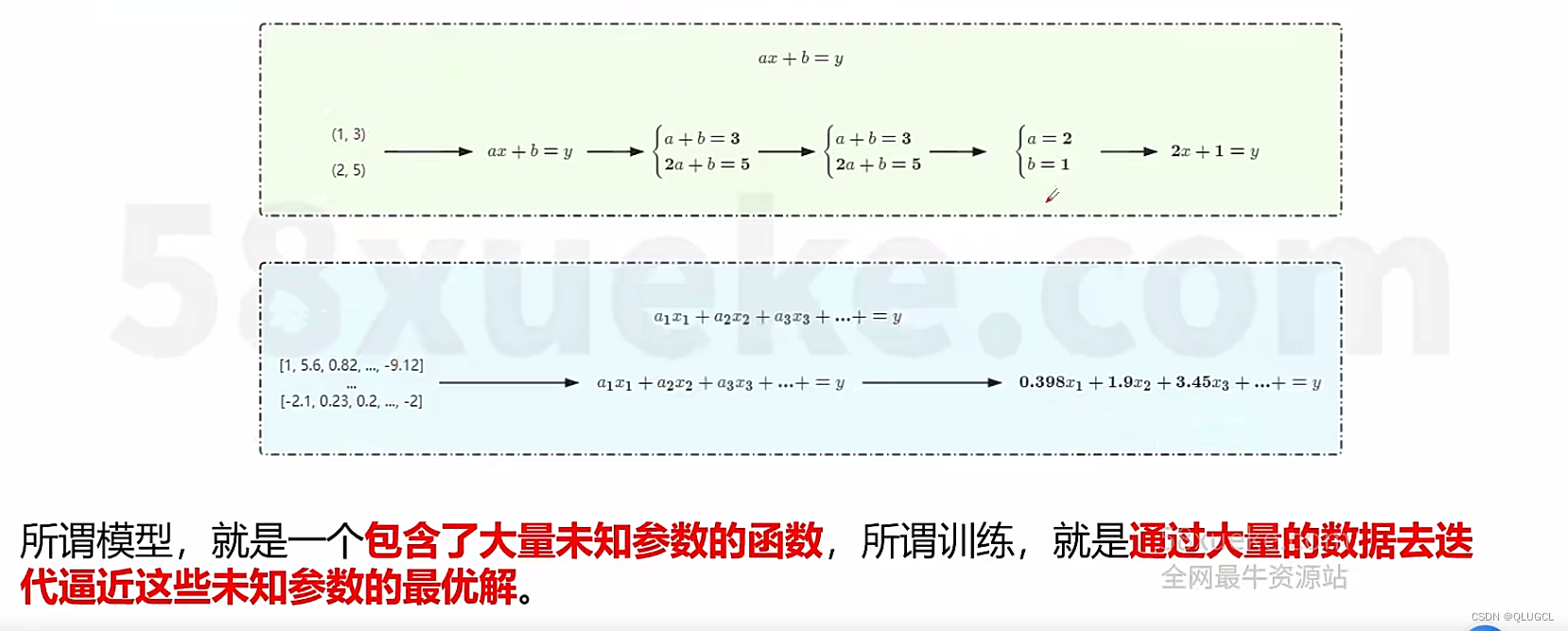
多维角度拆解分析复杂事实,维度数量就是未知参数量,分析公式就是万事万物的规律。
将数据(答案)喂给大模型(复杂公式)逐步求解出来未知参数,最终表达式就是大模型。
我们想要找到一组复杂事实背后的规律,但由于事实的复杂性,我们需要建立一个含有大量(十亿/百亿/千亿1万亿)未知参数的表达式,试图用这个表达式描述复杂事实背后的规律,如果我们求解出,或者近似求解出这些参数,那么我们就掌握了这组复杂事实的规律。
大模型就是这样的一个拥有大量未知参数的表达式,我们通过海量数据去求解或者说迭代更新它的参数,从而让大模型无限接近于复杂事实背后的规律,从而帮助我们实现需求。
实例:通俗理解:大模型就是一个复杂的带未知参数表达式(ax+b=y),数据就是部分实例(坐标),数据喂给大模型训练求出未知参数值后就是最终的大模型(2x+4=y),后面对大模型提出问题(x=9时,y等于多少?)就能通过计算获得答案(y=22)。
- 数据训练中数据被抽象剥离演化为了未知参数值体现在大模型算式中。
- 大模型只进行逻辑处理(参数值是逻辑处理能力的决定因素)还是需要外部知识储备库才能回答问题,外部知识储备库分为两种:一种是上网实时搜索,另一种是离线静态知识库(大数据存储方向:矢量存储)。

大模型将会改变那些行业(大模型有哪些作用?)
所有基于沟通、文案撰写和分析类的基础岗位,不需要特殊经验背景的行业及岗位都会收到AIGC的冲击。
纯技术就完蛋了,要业务强相关才行也就是需要特殊经验背景。



如何搞数据训练模型?
师夷长技以制夷
让GPT做数据标注:根据文本总结问题然后回答问题,最后用该数据训练自己的模型。- 数据训练中数据被抽象剥离演化为了未知参数值体现在大模型算式中。
- 大模型只进行逻辑处理(参数值是逻辑处理能力的决定因素)还是需要外部知识储备库才能回答问题,外部知识储备库分为两种:一种是上网实时搜索,另一种是离线静态知识库(大数据存储方向:矢量存储)。
LangChain带来的技术变革
Large language models (LLMs) are emerging as a transformative technology, enabling developers to build applications that they previously could not. However, using these LLMs in isolation is often
insufficient for creating a truly powerful app - the real power comes when you can combine them with other sources of computation or knowledge.
大型语言模型 (LLM) 正在成为一种变革性技术,使开发人员能够构建他们以前无法构建的应用程序。 然而,单独使用这些 LLM 往往不足以创建一个真正强大的应用程序 — 当你可以将它们与其他计算或知识来源相结合时,那么我们将拥有真正强大的技术力量。LangChain 是一套标准化规范,其技术团队致力于完成LLM到应用层的连接,LangChain 定义了从LLM到应用层的整体框架(分层+模块)— 你只需要按照LangChain定义的标准框架,完成其中的每个模块,就可以实现LLM能力到外部应用的完整链路。
LangChain 技术团队认为单一LLM并不能完全支撑复杂需求,可以通过现有技术与LLM的结合,形成综合的技术系统,由此来实现LLM时代的技术变革。LangChain架构
Models:指定语言模型或者API接口。
Prompts(将问题处理为大模型更容易理解的话术):预设Prompt template,对输入的query进行调format之成为更好的Prompt。
Indexes:通过Indexes对文档进行构建使得系统更好地与文档进行交互。LangChain 支持的主要索引和检索类型目前以矢量数据库为中心(大数据存储方向:矢量存储)。
Memory:让系统拥有长期记忆,记录用户之前的历史对话记录。
Chains:一个任务无法用一问一答解决时,需要使用chain,由chain根据任务进行进一步的拆分,决定如何通过多步骤,使用LLM解决问题。
Tools:Agent运行过程中要使用的一些工具,比如网页搜索工具、专门进行数学运算的工具等。
Agents:应用端,面向客户,调用chain完成任务,实现LLM与应用的链接,将llm、tools等传入agent。实例展示:
“谁是日本的现任领导人,小于他年龄的最大质数是多少?”- 初始化Agent(传入Tools信息,传入LLM信息,指定使用的agent)
- 调用Agent,传入query;
- Agent通过Tools中的网页搜索工具,搜索找到日本现任领导人信息;
- Agent通过Tools中的网页搜索工具,搜索他的年龄(65岁);
- Agent通过Tools中的llm(大模型)-math计算小于65的最小质数;
- 返回答案;
实例解析:
大模型只进行第五步的逻辑处理,以上四步都是插件实现,外部知识储备库采取的上网实时搜索。- 数据训练中数据被抽象剥离演化为了未知参数值体现在大模型算式中。
- 大模型只进行逻辑处理(参数值是逻辑处理能力的决定因素)还是需要外部知识储备库才能回答问题,外部知识储备库分为两种:一种是上网实时搜索,另一种是离线静态知识库(大数据存储方向:矢量存储)。
-
相关阅读:
Linux线程安全
AI图书推荐:用ChatGPT按需DIY定制来赚钱
有哪些免费的数据恢复软件?EasyRecovery免费版下载
【雷丰阳-谷粒商城 】【分布式基础篇-全栈开发篇】【02】Nacos、Feign、Gateway
pp-vehicle简介
普通索引和唯一索引,应该怎么选择?
SpringMVC枚举类型字段处理
Spring MVC和Spring Boot
并查集 rank 的优化
Yakit工具篇:综合目录扫描与爆破的使用
- 原文地址:https://blog.csdn.net/qq_43813373/article/details/136379687