-
亚信安慧AntDB数据并行加载工具的实现(二)
3.功能性说明
本节对并行加载工具的部分支持的功能进行简要说明。
1) 支持表类型
并行加载工具支持普通表、分区表。
2) 支持指定导入字段
文件中并不是必须包含表中所有的字段,用户可以指定导入某些字段,但是指定的字段数要和文件中的字段数保持一致。
3) 支持导入部分记录
并行加载工具支持指定Where条件,只将符合条件的记录导入到数据库中。
4) 自动生成序列字段值
本工具支持自动生成序列字段值,有些表的字段设置了Default值为序列,用户可能需要数据库自己生成,并没有包含在文件中。
当该字段为非分片键时,我们可以使用数据库自有的功能,在插入时自动生成该字段值。但是当该字段为分片键时,我们需要先在加载工具中生成该值,然后根据该值进行分片,插入到对应的DN节点。
5) 无分片键文件导入
当文件中不包含分片键,并且没有Default值时,加载工具将该字段置为Null计算并插入相应节点。
6) 触发器
当导入的表包含触发器时,并行加载工具并不会做特殊的处理,当触发器涉及非本数据节点时,并行加载工具并不支持。例如一个表的触发器,该触发器会插入另外一张表,但是该表分片与原表不同,此时将会涉及多个数据节点。
7) 不支持辅助表
AntDB有辅助表功能,用来优化SQL语句的性能,该表中存放数据表的相应数据。当数据表有辅助表时,并行加载工具只能将文件导入到数据表,并不会修改相应的辅助表。
8) 支持编码转换
并行加载工具支持数据编码转换,在文件中数据和数据库的编码不同时,工具会对文件中数据编码的转换之后再插入数据库。
4.性能
并行加载工具相比Copy命令,有效提升了数据加载的效率。由于表字段的个数、类型及数据的不同,并行加载工具相对Copy命令所提升的倍率并不完全相同。下面以TPCC的数据导入进行性能的对比。
1000仓的数据,需要导入到表Bmsql_Stock的记录有1亿条,数据文件Stock.csv文件的大小为29GB。测试的AntDB集群有2个DN主节点。在此场景的测试中,加载效率提升了7倍左右,加载速度对比图如下所示:
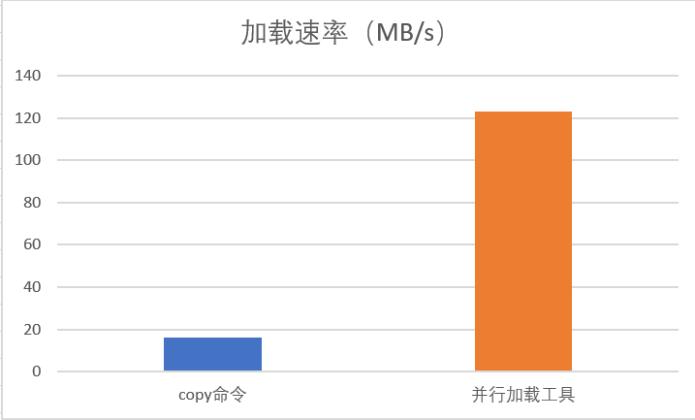
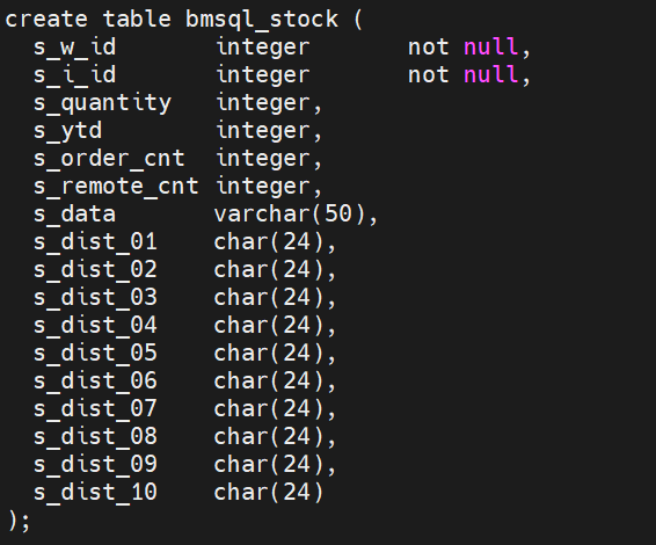
Bmsql_Stock表结构如下:
5. 总结
本文介绍了AntDB并行加载工具的实现方式和使用方法,通过多线程的方式实现并行处理文件数据,并加载到AntDB数据库,有效提升了加载的效率。
-
相关阅读:
03 - 调试环境的搭建(Bochs)(实验未完)
Dockerfile中安装crontab
75. 颜色分类
13行python代码实现对微信进行推送消息
[JAVAee]IP数据包的组包与分包
电子电路学习笔记之NCV6324BMTAATBG——同步降压转换器
发展高质量存储力,中国高科技力量聚浪成潮
ros小问题之roslaunch tab补不全新增的功能包
数学建模--MATLAB基本使用
倍福控制第三方伺服走CSV模式--以汇川伺服为例
- 原文地址:https://blog.csdn.net/weixin_44518445/article/details/136376778