-
CUDA编程 - 用向量化访存优化 - Cuda elementwise - Add(逐点相加)- 学习记录
Cuda elementwise - Add
一、简介
1.1、ElementWise Add
Element-wise 操作是最基础,最简单的一种核函数的类型,它的计算特点很符合GPU的工作方式:对于每个元素单独做一个算术操作,然后直接输出。
Add 函数 :逐点相加
- 传入 数组 a,b,c
- 传入 数据数量 N
- 传出结果 数组c
1.2、 float4 - 向量化访存
所谓向量化访存,就是一次性读 4 个 float,而不是单单 1 个
要点:
- 小数据规模情况下,可以不考虑向量化访存的优化方式
- 大规模数据情况下,考虑使用向量化访存,且最好是缩小grid的维度为原来的1/4,避免影响Occupancy
- float4 向量化访存只对数据规模大的时候有加速效果,数据规模小的时候没有加速效果
float4的性能提升主要在于访存指令减少了(同样的数据规模,以前需要4条指令,现在只需1/4的指令),指令cache里就能存下更多指令,提高指令cache的命中率。
判断是否用上了向量化访存,是在 nsight compute 看生成的SASS代码里会有没有LDG.E.128 Rx, [Rx.64]或STG.E.128 [R6.64], Rx这些指令的存在。有则向量化成功,没有则向量化失败。
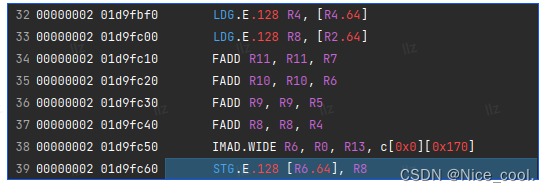
二、实践
2.1、如何使用向量化访存
c :
#define FLOAT4(value) *(float4*)(&(value))- 1
宏解释:
对于一个值,先对他取地址,然后再把这个地址解释成 float4
对于这个 float4的指针,对它再取一个值
这样编译器就可以一次读四个 floatc++ :
#define FLOAT4(value) (reinterpret_cast<float4*>(&(value))[0])- 1
2.1、简单的逐点相加核函数
__global__ void elementwise_add(float* a, float* b, float* c, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < N) c[idx] = a[idx] + b[idx]; }- 1
- 2
- 3
- 4
2.2、ElementWise Add + float4(向量化访存)
__global__ void elementwise_add_float4(float* a, float* b, float *c, int N) { int idx = (blockDim.x * blockIdx.x + threadIdx.x) * 4; if(idx < N ){ float4 tmp_a = FLOAT4(a[idx]); float4 tmp_b = FLOAT4(b[idx]); float4 tmp_c; tmp_c.x = tmp_a.x + tmp_b.x; tmp_c.y = tmp_a.y + tmp_b.y; tmp_c.z = tmp_a.z + tmp_b.z; tmp_c.w = tmp_a.w + tmp_b.w; FLOAT4(c[idx]) = tmp_c; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
将核函数写成 float4 的形式的时候,首先要先使用宏定义(参考1.3),其次要注意线程数的变化。
线程数变化原因:因为一个线程可以处理4个float了,所以要减少 四倍的线程。
2.3、完整代码
elementwise_add.cu
#include#include #include #include #include #include #include #include #define FLOAT4(value) *(float4*)(&(value)) #define checkCudaErrors(func) \ { \ cudaError_t e = (func); \ if(e != cudaSuccess) \ printf ("%s %d CUDA: %s\n", __FILE__, __LINE__, cudaGetErrorString(e)); \ } // ElementWise Add // elementwise_add<< - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
编译和运行:
nvcc -o elementwise_add elementwise_add.cu ./elementwise_add- 1
- 2
-
相关阅读:
按键中断实验
springcloud nacos和eureka
实时大数据处理real-time big data processing (RTDP)框架:挑战与解决方案
LabVIEW大量数据的内存管理
UI控件DevExpress WinForm新手指南——如何在应用启动时执行操作
interface 接口相关【GO 基础】
oCPC实践录 | oCPC转化的设计、选择、归因与成本设置(3)
尚硅谷大数据项目《在线教育之实时数仓》笔记001
俄罗斯方块——C语言实践(Dev-Cpp)
229. 多数元素 II
- 原文地址:https://blog.csdn.net/weixin_40653140/article/details/136300514
