-
MVCC【重点】
参考链接
[1] https://www.bilibili.com/video/BV1YD4y1J7Qq/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=0cb0c5881f5c7d76e7580fbd2f551074
[2]https://www.cnblogs.com/jelly12345/p/14889331.html
[3]https://xiaolincoding.com/mysql/transaction/mvcc.html#read-view-%E5%9C%A8-mvcc-%E9%87%8C%E5%A6%82%E4%BD%95%E5%B7%A5%E4%BD%9C%E7%9A%84
[4]https://zhuanlan.zhihu.com/p/52977862MVCC(Multi-Version Concurrency Control)多版本并发控制,MVCC在MySQL InnoDB中的实现主要是为了提高数据库并发性能,用更好的方式去处理读-写冲突,做到即使有读写冲突时,也能做到不加锁,非阻塞并发读
数据库并发场景有三种,分别为:
- 读-读:不存在任何问题,也不需要并发控制
- 读-写:有线程安全问题,可能会造成事务隔离性问题,可能遇到脏读,幻读,不可重复读
- 写-写:有线程安全问题,可能会存在更新丢失问题,比如第一类更新丢失,第二类更新丢失
核心知识点
MVCC它的实现原理主要是依赖记录中的 3个隐式字段,undo日志 ,Read View 来实现的。
1、3个隐式字段 2、聚簇索引 3、undo log 4、 read view 1、3个隐式字段
每行记录除了我们自定义的字段外,还有数据库隐式定义的DB_TRX_ID,DB_ROLL_PTR,DB_ROW_ID等字段
-
DB_ROW_ID:6byte,隐含的自增ID(隐藏主键),如果数据表没有主键,InnoDB会自动以DB_ROW_ID产生一个聚簇索引
-
DB_ROLL_PTR:7byte,回滚指针,指向这条记录的上一个版本(存储于rollback segment里)
-
- DB_TRX_ID:6byte,最近修改(修改/插入)事务ID:记录创建这条记录/最后一次修改该记录的事务ID
-
实际还有一个删除flag隐藏字段, 既记录被更新或删除并不代表真的删除,而是删除flag变了
DB_ROW_ID是数据库默认为该行记录生成的唯一隐式主键;DB_ROLL_PTR是一个回滚指针,用于配合undo日志,指向上一个旧版本;DB_TRX_ID是当前操作该记录的事务ID。
2. 聚簇索引
在MySQL中,InnoDB存储引擎默认使用聚簇索引来组织表的数据。
- 如果表定义了主键,则主键索引就是聚簇索引;【不隐藏】
- 如果表没有定义主键,则InnoDB存储引擎会选择一个唯一的非空索引来作为聚簇索引;【不隐藏】
- 如果没有合适的唯一非空索引,则InnoDB会自动生成一个隐藏的聚簇索引。
下面这张图,主键为id,所以聚簇索引为id,这时候并不是一个隐藏的列
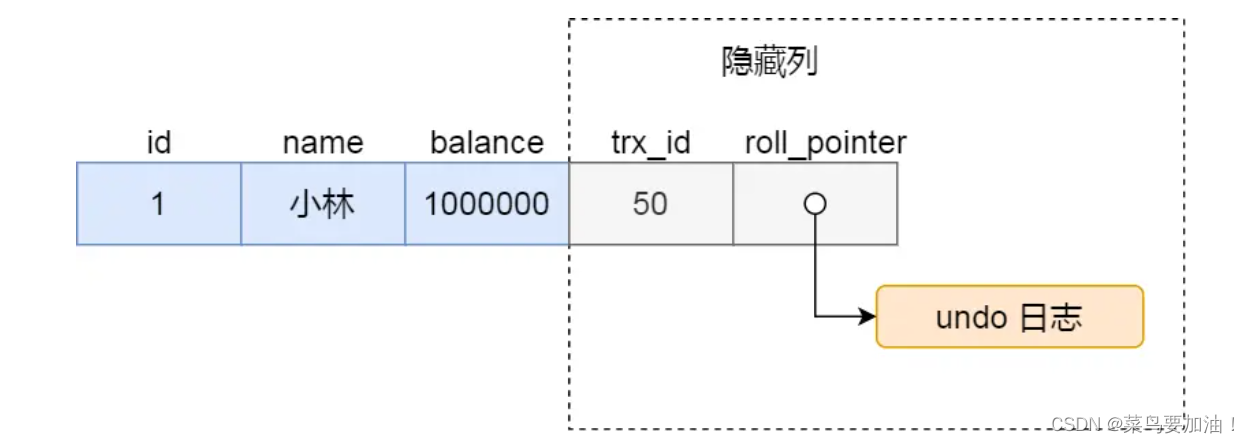
例如下面第一张图由于没有主键,没有唯一非空索引,因此使用自动生成当做聚簇索引

=====================================================================================
MVCC如何实现事务隔离?(Undo log版本链和Readview)
MySQL中MVCC的实现是基于Undo log版本链和Readview来达成的。
=====================================================================================
3. undo log(回滚日志)-------构造版本链
undo log(回滚日志),它保证了事务的 ACID 特性 (opens new window)中的原子性(Atomicity)
undo log主要分为两种:
- insert undo log:代表事务在insert新记录时产生的undo log, 只在事务回滚时需要,并且在事务提交后可以被立即丢弃
- update undo log: 事务在 进行update或delete 时产生的undo log;不仅在事务回滚时需要,在快照读时也需要;所以不能随便删除,只有在快速读或事务回滚不涉及该日志时,对应的日志才会被purge线程统一清除
对MVCC有帮助的实质是update undo log ,undo log实际上就是存在rollback segment中旧记录链,
Undo log(回滚日志),作为回滚的基础,在执行update和delete操作时,会将每次操作详细记录在Undo log中,每条Undo log中都记录一个叫做roll_pointer的引用信息,通过roll_pointer就可以将某条数据对应的Undo log,链接成一个Undo链。在Undo链的头部,通过数据行中的roll_pointer进行关联,就可以构成一条数据的版本链,这样对于每一行记录,都会有一个版本链,体现了这条记录的所有变更,有事务对这条数据进行操作时,将操作后的数据链接到版本的头部。
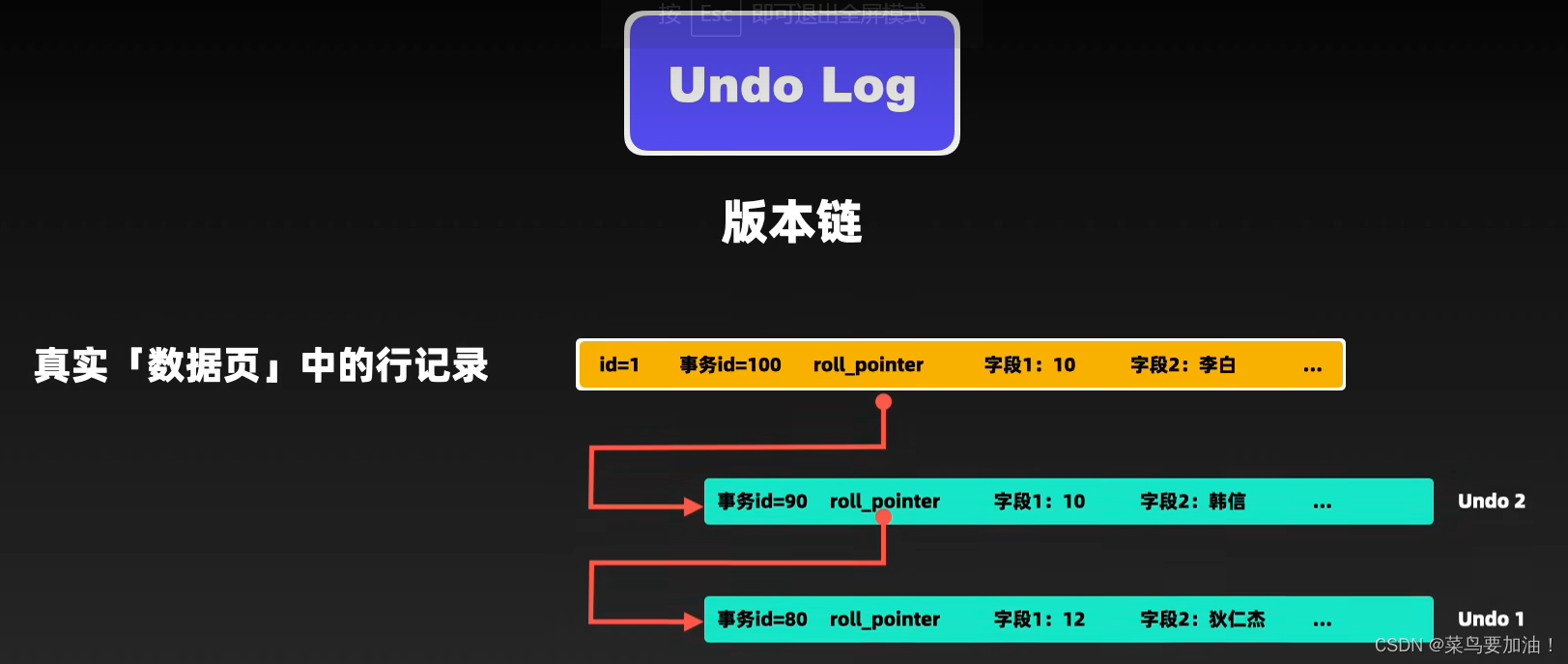
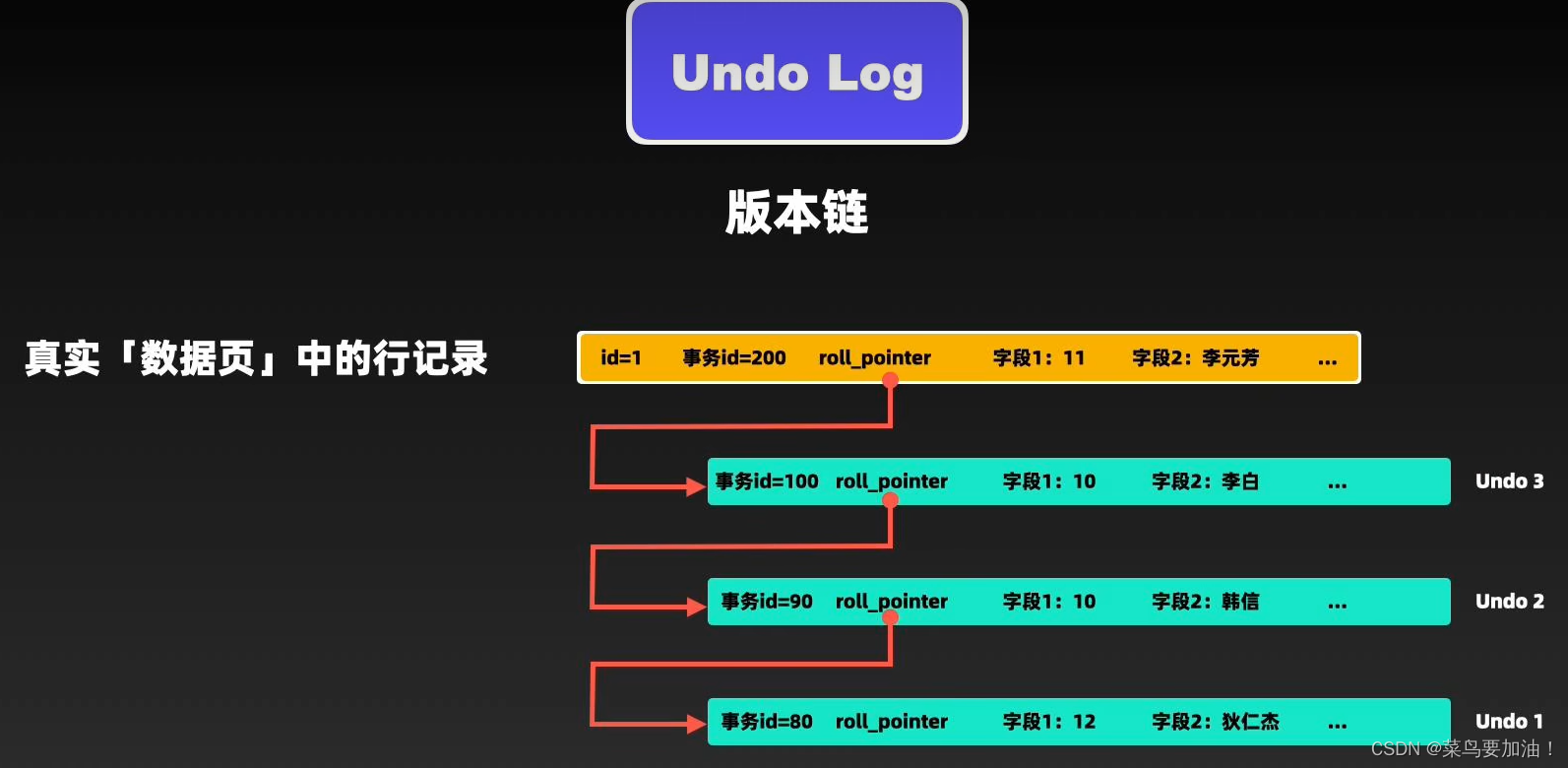
补充:因此,undo log 两大作用:
- 实现事务回滚,保障事务的原子性。 事务处理过程中,如果出现了错误或者用户执 行了 ROLLBACK 语句,MySQL 可以利用 undo log 中的历史数据将数据恢复到事务开始之前的状态。
- 实现 MVCC(多版本并发控制)关键因素之一。 MVCC 是通过 ReadView + undo log 实现的。undo log 为每条记录保存多份历史数据,MySQL 在执行快照读(普通 select 语句)的时候,会根据事务的 Read View 里的信息,顺着 undo log 的版本链找到满足其可见性的记录。
4. 每条数据的版本链都构造好之后,在查询的时候,是如何选择版本?(Read View)
就需要使用到Read View结构来实现。
Read View(读视图),是一个视图一个内存结构,一个 Read View 会在事务开始时创建(针对不同情况而定)。对于 「读提交」和「可重复读」 隔离级别的事务来说,它们的 快照读【补充部分:当前读,快照读和MVCC的关系】(普通 select 语句)是通过 Read View + undo log 来实现的,它们的区别在于 创建 Read View 的时机不同 :
- 「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
- 「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View,这样就保证了在事务期间读到的数据都是事务启动前的记录。
这两个隔离级别实现是通过「事务的 Read View 里的字段」和「记录中的两个隐藏列(trx_id 和 roll_pointer)」的比对,如果不满足可见行,就会顺着 undo log 版本链里找到满足其可见性的记录,从而控制并发事务访问同一个记录时的行为,这就叫 MVCC(多版本并发控制)。
因此我们可以知道在 「读提交」和「可重复读」的实现都是通过MVCC模式完成的
补充:
当前读,快照读和MVCC的关系- 准确的说,MVCC多版本并发控制指的是 “维持一个数据的多个版本,使得读写操作没有冲突” 这么一个概念。仅仅是一个理想概念
- 而在MySQL中,实现这么一个MVCC理想概念,我们就需要MySQL提供具体的功能去实现它,而快照读就是MySQL为我们实现MVCC理想模型的其中一个具体非阻塞读功能。【MVCC是一种通用模式,快照读是MySQL实现MVCC的其中一个具体非阻塞读功能】 而相对而言,当前读就是悲观锁的具体功能实现
- 要说的再细致一些,快照读本身也是一个抽象概念,再深入研究。MVCC模型在MySQL中的具体实现则是由 3个隐式字段,undo日志 ,Read View 等去完成的,具体可以看下面的MVCC实现原理。
当一个事务开始时,数据库系统会根据当前的活跃事务状态创建一个 Read View,用于确定该事务在其执行期间可以看到的数据视图。这个数据视图包含4个信息:
- creator_trx_id:创建Read View的事务;
- m_ids:当前活跃且未提交的事务集合 **(可以存在多个id) **
- min_trx_id:前活跃且未提交集合m_ids中最小事务的id
- max_trx_id:下一个将被分配的事务的id值,该值为全局事务中最大的事务 id 值 + 1 ==id+1;。
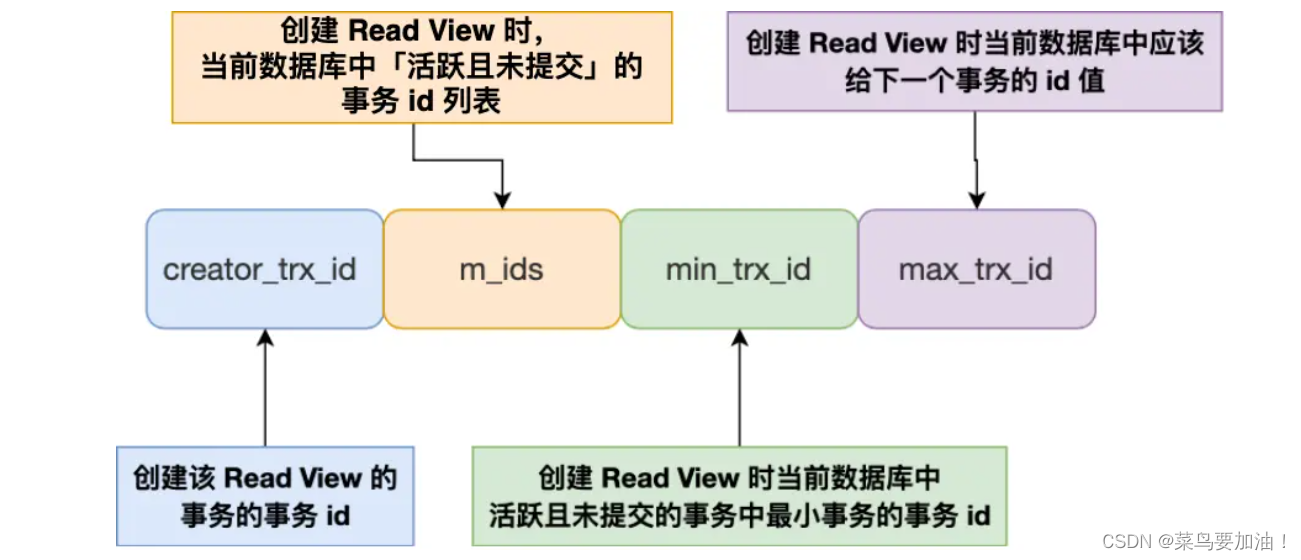
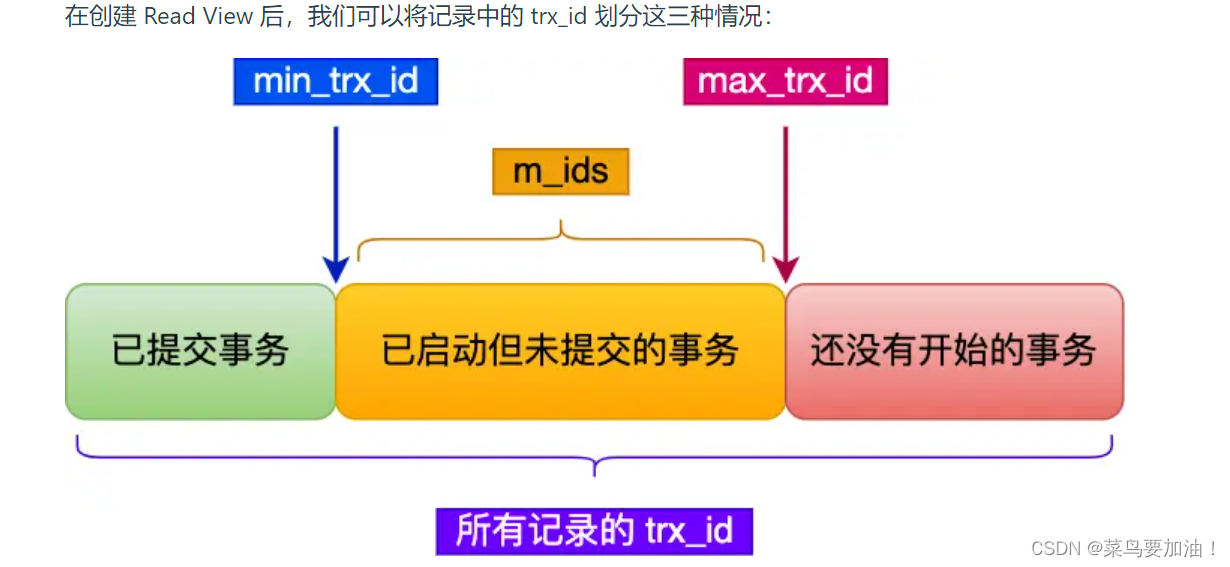
事务在执行期间会使用这个 Read View 来确定哪些数据行是可见的,哪些是不可见的。(例如下面的例子,【T5】可以/不可以看到【T1、T2、T3、T4】中的哪些)因此,创建一个 Read View 是为了在事务执行期间保持数据的一致性和隔离性。访问规则:
- 一个事务去访问记录的时候,自己的更新记录总是可见
- 如果记录的 trx_id 值小于 Read View 中的 min_trx_id 值,【 trx_id < min_trx_id】 表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务 可见。【不一定,因为在【可重复读】隔离级别下,当事务已经启动,创建了Read View,这时候不管重复读几次,读到的结果都是和第一次结果一样的{第一次结果如果为不可见,那么后面几次读取的都是不可见},因为这几次的读取并不会重新创建Read View,与【读提交】隔离级别不同,因为读提交时每一次select都是会重新创建Read View,,所以只要提交修改后的事务,都可见】----------(理解【可重复读】和【读提交】的工作原理)
- 如果记录的 trx_id 值大于等于 Read View 中的 max_trx_id 值 【 trx_id >= max_trx_id】,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务 不可见。
- 如果记录的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间 【min_trx_id<=trx_id
- 如果记录的 trx_id 在 m_ids列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。
如果记录的 trx_id 不在m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
【例子】
上述提及的【trx_id】是【T1、T2、T3、T4事务】对应的记录信息,通过使用Read View对该值的判断,就可以得出【T5】能够访问【T1、T2、T3、T4】中的哪些事务,例子如下:
假设有以下事务序列:
- 事务T:有一条记录,trx_id为 100。(已提交)
- 事务T1:更新一条记录,trx_id为 101。(已启动未提交)
- 事务T2:更新另一条记录,trx_id为 200。(已启动未提交)
- 事务T3:更新第三条记录,trx_id为 300。(已启动未提交)
- 事务T4:更新第三条记录,trx_id为 301。(还没有启动)
- 事务T5:启动后读取记录。trx_id为 305
假设在事务T4启动后,数据库创建了一个Read View来确定T5可以看到哪些记录的变化。此时,T4的Read View可能如下所示:
- creator_trx_id:400;
- m_ids:101、200、300
- min_trx_id:100
- max_trx_id:301
现在来检查每个记录的trx_id,并确定T5对每个记录的可见性:(从链头开始)
- T5能够看到自己的记录
- 当 trx_id=301,对应T4,这时候【 trx_id >= max_trx_id】,所以T5看不到T4
- 当 trx_id=300,对应T3,这时候【min_trx_id<=trx_id
- 同理,T5也看不到T2和T1
- 当trx_id=100,对应T,这时候【 trx_id < min_trx_id】,事务已经提交,所以T5看到T
因此,根据T5的Read View,T5对trx_id为100的记录可见,而对trx_id为101、200、300、301的记录不可见。
===========================【可重复读】和【读提交】的区别
【可重复读】
当上面例子的T1事务变成已提交,但是仍然以T5事务为例
- 事务T:有一条记录,trx_id为 100。(已提交)
- 事务T1:更新一条记录,trx_id为 101。(已提交)
- 事务T2:更新另一条记录,trx_id为 200。(已启动未提交)
- 事务T3:更新第三条记录,trx_id为 300。(已启动未提交)
- 事务T4:更新第三条记录,trx_id为 301。(还没有启动)
- 事务T5:启动后读取记录。trx_id为 305 (第二/多次读取事务)
因为上文提及:「可重复读」隔离级别是启动事务时生成一个 Read View,所以此时 T5 的Read View还是和第一次读取时一样,没有改变过,仍然为
- creator_trx_id:400;
- m_ids:101、200、300
- min_trx_id:100
- max_trx_id:301
所以 T5 读取的结果还是:T5对trx_id为100的记录可见,而对trx_id为101、200、300、301的记录不可见。
这也就应对了可重复读的原理:在同一个事务中多次读取同一行数据时,保证读取到的数据是一致的。【读提交】
当上面例子的T1事务变成已提交,但是仍然以T5事务为例
- 事务T:有一条记录,trx_id为 100。(已提交)
- 事务T1:更新一条记录,trx_id为 101。(已提交)
- 事务T2:更新另一条记录,trx_id为 200。(已启动未提交)
- 事务T3:更新第三条记录,trx_id为 300。(已启动未提交)
- 事务T4:更新第三条记录,trx_id为 301。(还没有启动)
- 事务T5:启动后读取记录。trx_id为 305 (第二/多次读取事务)
因为上文提及:「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,所以此时 T5 的Read View后续读取的每一次都和前一次不一样,都发生改变(假设第二次读取),由于T1已经提交,所以第二次读取后的 T5 Read View为:
- creator_trx_id:400;【不变,因为是在同一个事物,只是读取次数不一样】
- m_ids:200、300
- min_trx_id:200
- max_trx_id:301
同理按照规则:
。。。。(此处省略)
之后到 trx_id=101、trx_id=100,对应 T1、T,这时候【 trx_id < min_trx_id】,事务已经提交,所以T5可以看到 T1,T
所以 T5 读取的结果是:T5对trx_id为100、101的记录可见,而对trx_id为200、300、301的记录不可见。
这也就应对了读提交的原理:事务只能读取已经提交的数据>所以,总的来说,【可重复读】和【读提交】工作区别在于:同一个事务读取数据时的次数发生改变后,前提是有另外的事务T提交了自己的事务,这时候【可重复读】的结果还是和该事务的第一次读取一样,不改变结果。【读提交】的结果和该事务第一次或者前一次的读取不一样,结果发生改变,会看到提交的事务T(下面是更专业解释)
- RR(可重复读): 在可重复读隔离级别下,事务可以多次读取同一数据行,并且在事务执行期间所读取的数据保持一致,即事务执行期间不会受到其他事务的影响。这意味着事务在开始时创建了一个数据视图(Read View),并在整个事务期间保持这个数据视图不变。在这个级别下,其他事务对数据的修改不会影响当前事务的读取结果,从而实现了数据的一致性和隔离性。
- RC(读已提交): 在读已提交隔离级别下,事务只能读取已提交的数据,也就是说事务所读取的数据必须是其他事务已经提交的。这意味着事务在执行查询时会立即看到其他已提交事务所做的修改,而不会看到未提交事务所做的修改。因此,读已提交隔离级别下的数据读取是更为实时和动态的,但同时也会导致读取到的数据不一致。
综上,这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)
MVCC可以解决幻读吗?(待更新…)
MVCC(多版本并发控制)可以部分地解决幻读问题,但并不能完全消除。
幻读(Phantom Read):指在一个事务内,多次执行同一个查询时,由于其他事务对数据进行了插入或删除操作,导致查询结果集合不一致的现象。例如,事务A在查询某个范围内的数据时,事务B在该范围内插入了新的数据,然后事务A再次查询同一范围的数据,发现结果集合中出现了之前不存在的新数据,这就是幻读。
在MVCC中,事务开始时会创建一个Read View(或称为快照),用于记录当前事务开始时数据库的状态。当事务执行查询时,数据库会根据这个Read View来确定可见的数据行版本,从而保证事务执行期间读取到的数据是一致的。
根据 小林coding的讲解,MySQL InnoDB 引擎的可重复读隔离级别(默认隔离级),根据不同的查询方式,分别提出了避免幻读的方案---->【快照读】【当前读】
参考链接
https://xiaolincoding.com/mysql/transaction/phantom.html#%E7%AC%AC%E4%BA%8C%E4%B8%AA%E5%8F%91%E7%94%9F%E5%B9%BB%E8%AF%BB%E7%8E%B0%E8%B1%A1%E7%9A%84%E5%9C%BA%E6%99%AF快照读是如何避免幻读
可重复读隔离级是由 MVCC(多版本并发控制)实现的,实现的方式是开始事务后(执行 begin 语句后),在执行第一个查询语句后,会创建一个 Read View,后续的查询语句利用这个 Read View,通过这个 Read View 就可以在 undo log 版本链找到事务开始时的数据,所以事务过程中每次查询的数据都是一样的,即使中途有其他事务插入了新纪录,是查询不出来这条数据的,所以就很好了避免幻读问题。
当前读是如何避免幻读
加锁:next-key lock(next-key lock 是间隙锁+记录锁的组合)
可重复读隔离级别下虽然很大程度上避免了幻读,但是还是没有能完全解决幻读。
即:MySQL InnoDB 引擎的默认隔离级为【可重复读隔离级别】,想要解决幻读,只能根据引擎当前有的方法结合其他方法,根来避免幻读:
因为MySQL InnoDB 引擎中存在 快照读 和 当前读- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读,但是并不能完全避免幻读,只能部分避免。
- 针对当前读(select … for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读。
两个发生幻读场景的例子。
-
第一个例子:对于快照读, MVCC 并不能完全避免幻读现象。因为当事务 A 更新 了一条事务 B 插入的记录,那么事务 A 前后两次查询的记录条目就不一样了,所以就发生幻读。
-
第二个例子:对于当前读,如果事务开启后,并没有执行当前读,而是先快照读,然后这期间如果其他事务插入了一条记录,那么事务后续使用当前读进行查询的时候,就会发现两次查询的记录条目就不一样了,所以就发生幻读。
所以,MySQL 可重复读隔离级别并没有彻底解决幻读,只是很大程度上避免了幻读现象的发生。
要避免这类特殊场景下发生幻读的现象的话,就是尽量在开启事务之后,马上执行 select … for update 这类当前读的语句,因为它会对记录加 next-key lock,从而避免其他事务插入一条新记录。(这种方法就是类似【串行化】,最高级别的隔离,但是性能一直加锁,性能差)
=================================================
总结
1、数据库为什么要有事务?
【为了保证数据最终的一致性。】2、事务包括哪几个特性?
【原子性、隔离性、一致性、持久性。】
参考:事务的ACID特性:https://zhuanlan.zhihu.com/p/277896023、事务的并发引起了哪些问题?
事务并发会引起 【脏读、重复读、幻读】 问题。4、怎么解决事务并发出现的问题?
进行事务隔离,针对不同的并发问题,设置不同的的事务隔离级别 【读未提交,读提交,重复读,序列化】。
参考:事务隔离与实现:https://zhuanlan.zhihu.com/p/277901945、数据库通过什么方式保证了事务的隔离性?
通过 【加锁】 来实现事务的隔离性。
参考:Mysql 的各种锁:https://zhuanlan.zhihu.com/p/523123766、频繁的加锁会带来什么问题?
读取数据的时候没办法修改,修改数据的时候没办法读取,极大的降低了数据库读写性能。
7、数据库是如何解决加锁后的性能问题的?
MVCC 多版本控制,实现读取数据不用加锁, 可以在读取数据同时修改。修改数据时同时可读取。
快照读
快照读是指读取数据时不是读取最新版本的数据,而是基于历史版本读取的一个快照信息(mysql读取undo log历史版本) ,快照读可以使普通的SELECT 读取数据时不用对表数据进行加锁,从而解决了因为对数据库表的加锁而导致的两个如下问题
1、解决了因加锁导致的修改数据时无法对数据读取问题;
2、解决了因加锁导致读取数据时无法对数据进行修改的问题;
当前读
当前读是读取的数据库最新的数据,当前读和快照读不同,因为要读取最新的数据而且要保证事务的隔离性,所以当前读是需要对数据进行加锁的(Update delete insert select …lock in share mode select for update 为当前读)
-
相关阅读:
Jenkins发布windows服务器jar
Rust机器学习之Linfa
尚硅谷-Netty篇
云小课|MRS基础原理之CarbonData入门
使用TortoiseGit导出两次提交时间之间的差异文件
数据结构与算法之美 复杂度分析(下)
关于基环树找环问题
微服务网关之Zuul1.0上
弘辽科技:淘宝9月什么时候有活动?99大促有哪些活动?
Go 里的超时控制
- 原文地址:https://blog.csdn.net/qq_45927881/article/details/136315939