-
ELK 简介安装
1、概念介绍
日志介绍
日志就是程序产生的,遵循一定格式(通常包含时间戳)的文本数据。 通常日志由服务器生成,输出到不同的文件中,一般会有系统日志、 应用日志、安全日志。这些日志分散地存储在不同的机器上。
日志的作用:
- 数据查找:通过检索日志信息,定位相应的 bug ,找出解决方案
- 服务诊断:通过对日志信息进行统计、分析,了解服务器的负荷和服务运行 状态
- 数据分析:可以做进一步的数据分析,比如根据请求中的商品 id ,找出 TOP10 用户感兴趣商品。
存在的问题
如何解决
通常,日志被分散的储存不同的设备上。传统查看日志的方法是登陆服务器查看日志,如果管理数十上百台服务器,这种方法很繁琐、效率低下。
当务之急我们需要集中化日志管理,例如:开源的 syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成一件比较麻烦的事情,一般我们使用 grep、awk 和 wc 等 Linux 命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
开源实时日志分析 ELK 平台能够完美的解决我们上述的问题,ELK 是一个成熟的 日志系统,主要功能有日志的收集、分析、检索。
扩展概念
说明
API
Application Programming Interface 应用程序编程接口:是一些预先定义的接口(如函数、HTTP 接口),访问程序 API 接口就可以得到接口返回的数据,无需知道后端源代码是怎么工作的,类似于调用函数,返回函数结果。
XML
可扩展标记语言,是超文本标记语言的补充,一种程序和程序之间传输数据的标记语言,它被设计用来传输和存储数据。
JSON
javascript object notation 一种新型的轻量级数据交换格式,是一种轻量级的数据交换格式。易于人阅读和编写,可以在多种语言之间进行数据交换。同时也易于机器解析和生成
YAML
YAML Aint Markup Language 是一种标记语言,通常以.yml 或者.yaml 为后缀的文件,可与 C,python,java 多种语言交互,是一种专门用来配置文件的语言。
REST
Representational State Transfer,表现层状态转化。
表现层:代表访问资源,比如说一段文本,一部电影,每个资源都有一个 ID 来表示,这个 ID 成为我们的 URL。每个资源仅代表一个信息,一个信息又可以用很多种形式来表示,比如文字,有 txt ,word 格式。
状态转化:通过 GET 用来获取资源,post 用来新建资源,PUT 用来更新资源, delete 删除资源。
RESTful 是一种软件架构风格、设计风格,而不是标准,只是提供了一组设计原则 和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件 可以更简洁,更有层次,更易于实现缓存等机制
ELK 简介
ELK 由 ElasticSearch、Logstash 和 Kibana 三个开源工具组成。这三个工具组合形成了一套实用、易用的日志管理平台,可抓取系统日志、apache 日志、nginx 日志、mysql 日志等多种日志类型,目前很多公司用它来搭建可视化的集中式日志分析平台。
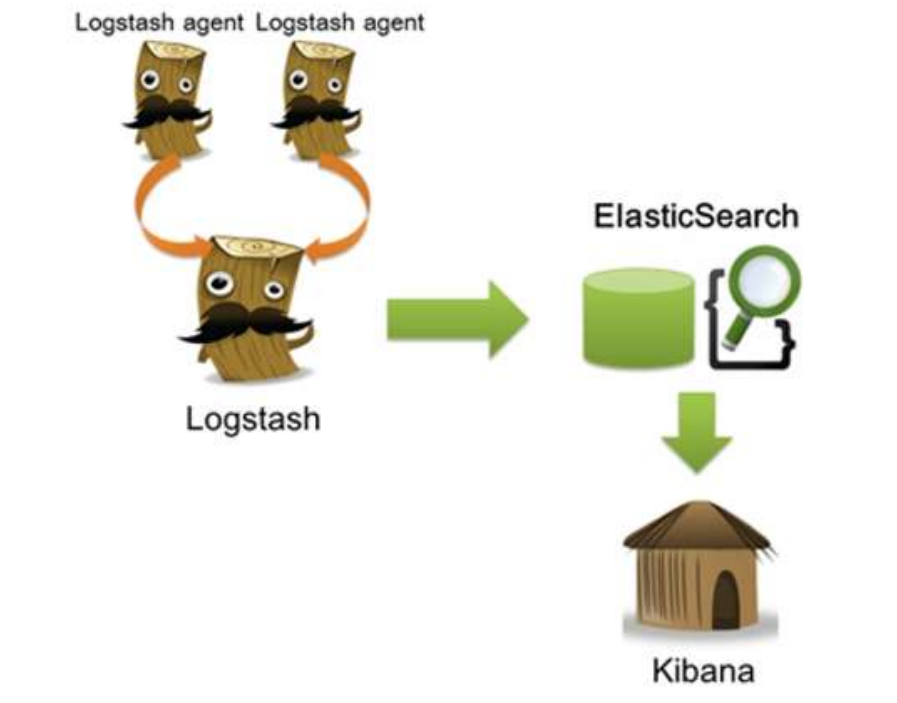
在需要收集日志的所有服务上部署 logstash,作为 logstash agent,用于监控并过滤收集日志,将过滤后的内容发送到 logstash indexer(索引器),logstash indexer 将日志收集在一起交给全文搜索服务 ElasticSearch,可以用 ElasticSearch 进行自定义搜索通过 Kibana 来结合自定义搜索进行页面展示。
ELK 优点
ELK Stack 在机器数据分析,或者说实时日志处理领域,开源界的第一选择。和传统的日志处理方案相比,ELK Stack 具有如下几个优点:
① 处理方式灵活。Elasticsearch 是实时全文索引,不需要像 storm 那样预先编程才能使用;
② 配置简易上手。Elasticsearch 使用用 RESTFUL api 标准开发,数据全部 JSON 接口,Logstash 是 Ruby DSL 设计,都是目前业界最通用的配置语法设计;
③ 检索性能高效。虽然每次查询都是实时计算,但是优秀的设计和实现基本可以达到全天数据查询的秒级响应;
④ 集群线性扩展。不管是 Elasticsearch 集群还是 Logstash 集群都是可以线性扩展的;
⑤ 前端操作炫丽。Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
LogStack
Logstash 是一个开源的工具,主要是用来日志的搜集、分析、过滤, 一般工作方式为 c/s 架构, client 端安装在需要收集日志的主机上,server 端负责将收到的各节点日志进行过滤、修改等操作在一并发往 elasticsearch 上。logstash 是可以被别的替换,比如常见的 fluented.
ElasticSearch
Elasticsearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。
Elasticsearch 是一个建立在全文搜索引擎 Apache Lucene™ 基础上的分布式的,高可用的,基于 json 格式的数据构建索引,准实时查询的搜索引擎。Lucene 是当今最先进最高效的全功能开源搜索引擎框架,但是 Lucene 使用非常复杂。
Elasticsearch 使用 Lucene 作为内部引擎,但是在你使用它做全文搜索时,只需要使用统一开发好的API即可,而并不需要了解其背后复杂的 Lucene 的运行原理。
Elasticsearch 为去中心化的分布式架构,由若干节点组成集群。节点中没有固定的主控角色,可以灵活伸缩规模。集群中每台服务器通常只需部署一个 Elasticsearch节点,每个节点可以将本机的所有数据盘用于存储索引数据。
Elasticsearch 是可伸缩的。一个采用 RESTFUL api 标准的高扩展性和高可用性的实时数据分析的全文搜索工具。 高扩展性体现在拓展非常简单,Elasticsearch 新节点,基本无需做复杂配置,自动发现节点。高可用性,因为这个服务是分布式的,而且是一个实时搜索平台,支持 PB 级的大数据搜索能力。从一个文档到这个文档被搜索到,只有略微的延迟,所以说他的实时性非常高。
Elasticsearch 基本概念
说明
节点(Node)
一个 Elasticsearch 运行的实例。
集群(Cluster)
具有同一集群名称的节点组成的分布式集群。
索引(Index)
一个日志记录的集合,类似数据库。须要注意的是索引的名称不能有大写字母。
切片(Shard)
每个索引的数据可以划分成若干切片,不同切片会被存储到不同的节点上以实现客户端读写条带化。
副本(replica)
切片的数据冗余,和切片主体的内容相同,保证数据安全和高可用。
可以把 elasticearch 当做一个数据库,来对比下与其他数据库的不同, elasticseach 是非关系型数据库。
ElasticSearch 架构
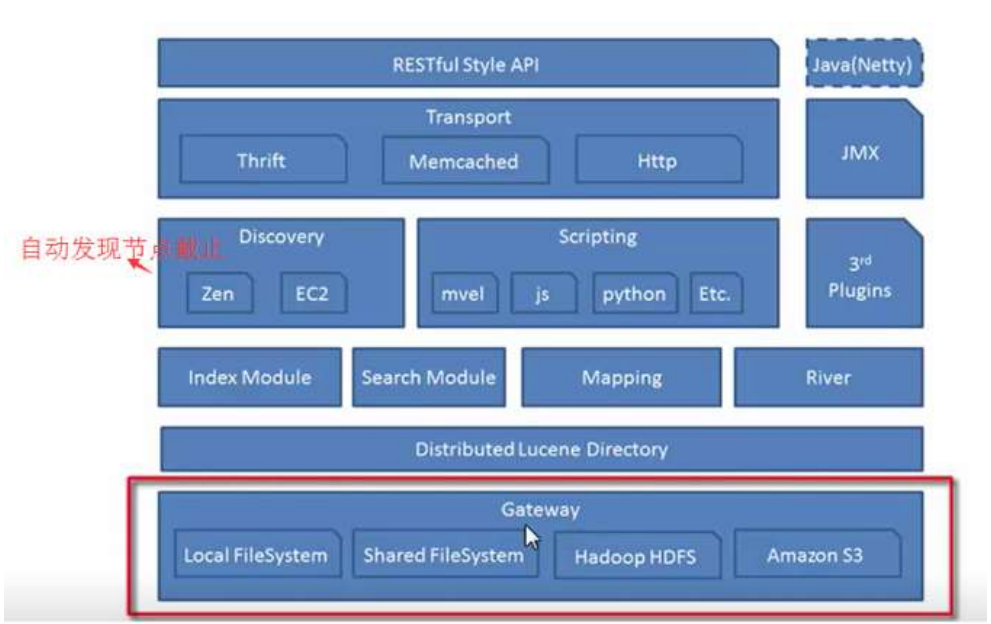
第一行:elasticsearch 支持的索引数据的存储格式,当这个 elasticsearch 关闭再启动的时候,他就会从 gateway 里面读取索引数据。本地的,分布式,亚马逊的 S3
第二行:是 lucene 的框架
第三行:对数据的加工处理方式:
- 创建 index 模块,
- search Module,
- Mapping:是定义文档及其包含的字段是如何存储和索引的过程。例如,我们用映射来定义: 哪些字符串字段应该被当做全文字段 哪些字段包含数字、日期或地理位置是否应该将文档中所有字段的值索引到 catch-all 字段中。
- river 代表 es 的一个数据源,也是其它存储方式(如:数据库)同步数据到 es 的一个方法。它是以插件方式存在的一个 es 服务,通过读取 river 中的数据并把它索引到 es 中。
第四行:
- 左边:是 elasticsearch 自动发现节点的机制。 zen 用来实现节点自动发现的,假如 master 发生故障,其他的节点就会自动选 举,来确定一个 master。
- 中间:方便对查询出来的数据进行数据处理。
- 右边:插件识别,中文分词插件,断点监控插件
第五行:是交互方式,默认是用 httpd 协议来传输的。
第六行:最顶层右边是说可以使用 java 语言,本身就是用 java 开发的。
Kibana
Kibana 是一个为 Logstash 和 ElasticSearch 提供的日志分析的 Web 接口。也是一个开源和免费的工具,可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
ELK 常见框架
① Elasticsearch + Logstash + Kibana
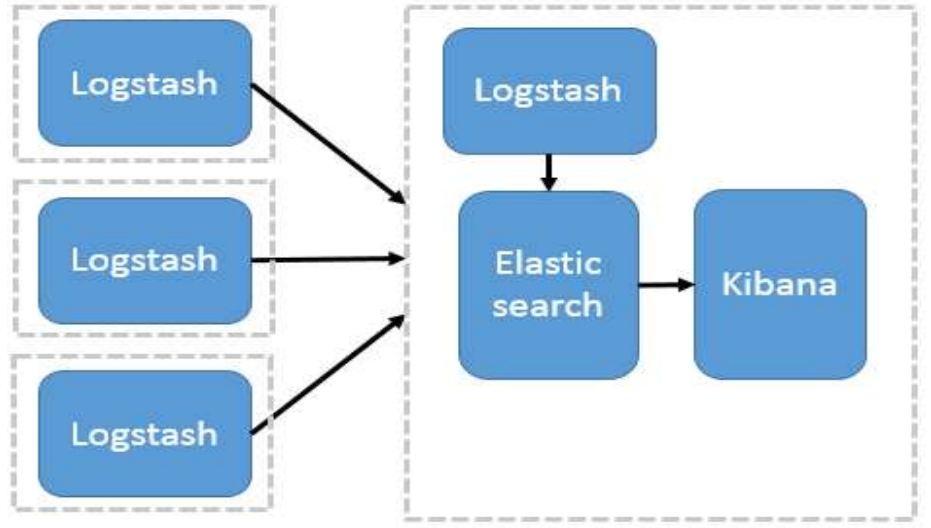
这是一种最简单的架构。通过 logstash 收集日志,Elasticsearch 分析日志,然后在 Kibana(web 界面)中展示。这种架构虽然是官网介绍里的方式,但是往往在生产中很少使用。
② Elasticsearch + Logstash + filebeat + Kibana
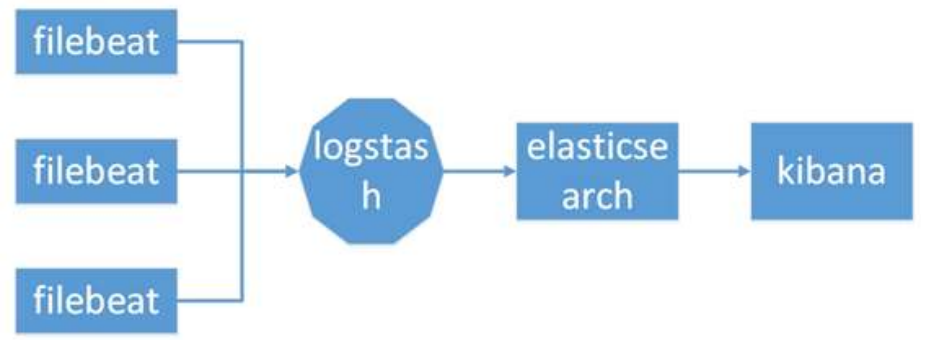
与上一种架构相比,这种架构增加了一个 filebeat 模块。filebeat 是一个轻量的日志收集代理,用来部署在客户端,优势是消耗非常少的资源(较 logstash), 所以生产中,往往会采取这种架构方式,此种架构将收集端 logstash 替换为 beats,更灵活,消耗资源更少,扩展性更强。同时可配置 Logstash 和 Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。但是这种架构有一个缺点,没有消息 队列缓存,当 logstash 出现故障,会造成日志的丢失。
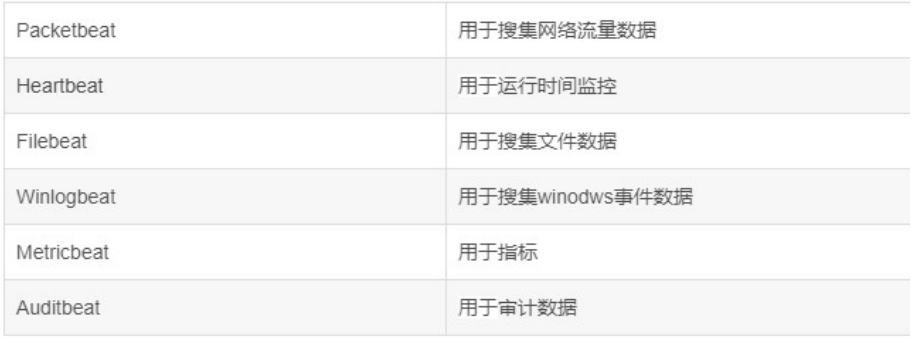
轻量级日志采集框架 Beats,其中包含以下 6 种:
③ Elasticsearch + Logstash + filebeat + redis(kafka)
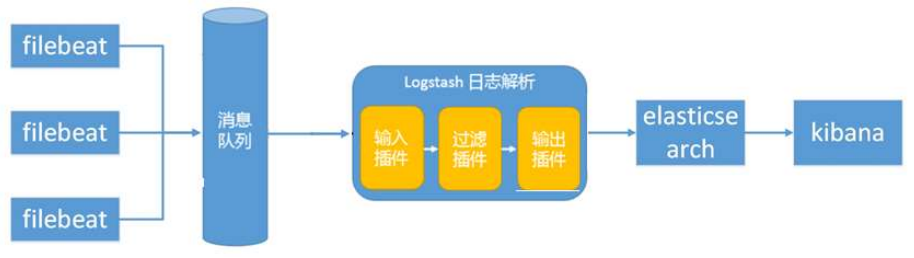
此种架构引入了消息队列机制,位于各个节点上的 beats 先将数据/日志传递给消息队列(kafka、redis、rabbitMQ 等),logstash 从消息队列取数据进行过滤、分析后将数据传递给 Elasticsearch 存储。最后由 Kibana 将日志和数据呈现给用户。因为引入了 Kafka(或者 Redis),所以即使远端 Logstash server 因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
注意:logstash 节点和 elasticsearch 节点可以根据日志量伸缩节点数量, filebeat 部署在每台需要收集日志的服务器上。
2、ELK + Filebeat + Kafka
主机名称
IP地址
服务
备注
node-11
192.168.137.111
ELK8.4
ELK软件版本应一致
node-12
192.168.137.112
httpd + filebeat
使用filebeat收集日志
node-13
192.168.137.113
Kafka + zookeeper
这里部署单节点
安装 Elasticserach
① 下载并安装软件
- # 下载软件
- wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.4.0-linux-x86_64.tar.gz
- wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.4.0-linux-x86_64.tar.gz
- wget https://artifacts.elastic.co/downloads/logstash/logstash-8.4.0-linux-x86_64.tar.gz
- wget https://artifacts.elastic.co/downloads/kibana/kibana-8.4.0-linux-x86_64.tar.gz
- # 安装elasticsearch
- tar -zxvf elasticsearch-8.4.0-linux-x86_64.tar.gz -C /usr/local/
- # 源码包安装 Elasticsearch 不能用 root 启动,这里创建普通用户 elk
- useradd elk
- # 给文件授权
- chown -R elk:elk /usr/local/elasticsearch-8.4.0/
由于 ELK 3 个软件都需要 JDK 只支持,所以只要安装 Elasticsearch + Logstash + Kibana 的服务器都要装 JDK,elasticsearch 7.17.3 及其之前的版本支持 JDK1.8,7.17.3 版本之后需要安装 JDK17 以上。Elasticsearch 安装包自带 jdk,我们使用自带版本。
- # 配置 JDK 环境变量
- vim /etc/profile #在文件最后加入一下行
- export JAVA_HOME=/usr/local/elasticsearch-8.4.0/jdk
- export PATH=$PATH:$JAVA_HOME/bin
- export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- export JAVA_HOME PATH CLASSPATH
- # 使环境变量生效
- source /etc/profile
- # 查看 java 环境
- java -version
② 修改 linux 系统打开文件最大数
- vim /etc/sysctl.conf
- vm.max_map_count=655360
- vim /etc/security/limits.conf #在文件最后添加以下行
- #修改最大打开文件数
- * soft nofile 65536
- * hard nofile 65536
- # 修改最大进程数
- * soft nproc 65536
- * hard nproc 65536
③ 使用普通用户启动Elasticsearch
- su - elk
- cd /usr/local/elasticsearch-8.4.0/config
- # 编辑主配置文件
- vim elasticsearch.yml
- --------------------------------------------------------
- cluster.name: my-application
- node.name: node-1
- #防止启动检测报错
- bootstrap.memory_lock: false
- #修改监听 IP
- network.host: 0.0.0.0
- http.port: 9200
- cluster.initial_master_nodes: ["node-1"]
- #关闭安全认证,否则使用 http 访问不到 es
- xpack.security.enabled: false
- xpack.security.http.ssl:
- enabled: false
- ----------------------------------------------------------------
- # 前台启动 Elasticsearch
- [elk@cong11 elasticsearch-8.4.0]$ ./bin/elasticsearch
- # 后台启动
- ./bin/elasticsearch -d
- # 或者
- ./bin/elasticsearch &
- # 查看端口
- netstat -antup | grep 9200

- # 查看进程
- jps -m

elasticsearch 测试:http://192.168.1.11:9200/
编写 es 启动脚本:以下脚本没有执行成功
- vim /etc/init.d/elasticsearch
- ----------------------------script1-----------------------------------
- #!/bin/sh
- #chkconfig: 2345 80 05
- #description: elasticsearch
- #author: taft
- ES_HOME=/usr/local/elasticsearch-8.12.1
- export JAVA_HOME=/usr/local/elasticsearch-8.12.1/jdk
- export PATH=$PATH:$JAVA_HOME/bin
- export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- export JAVA_HOME PATH CLASSPATH
- start(){
- if [ "$(pidof java)" ]; then
- echo "Elasticsearch is already running."
- return 1
- fi
- /usr/local/elasticsearch-8.12.1/bin/elasticsearch -d
- echo "Elasticsearch started."
- }
- stop() {
- if [ ! "$(pidof java)" ]; then
- echo "Elasticsearch is not running."
- return 1
- fi
- es_pid=`jps | grep Elasticsearch | awk '{print $1}'`
- kill -9 $es_pid
- echo "elasticsearch stopped"
- }
- restart(){
- stop
- start
- }
- case "$1" in
- start)
- start
- ;;
- stop)
- stop
- ;;
- restart)
- restart
- ;;
- *)
- echo "Usage: $0 {start|stop|restart}"
- exit 1
- ;;
- esac
- exit $?
- ========================================================================
- #!/bin/bash
- #
- # /etc/init.d/elasticsearch
- #
- # Elasticsearch Startup Script for SysVinit
- #
- # Elasticsearch environment
- ES_HOME=/usr/local/elasticsearch-8.12.1
- ES_BIN=$ES_HOME/bin
- ES_USER=elk
- ES_GROUP=elk
- # Check that networking is up
- . /etc/init.d/functions
- start() {
- if [ "$(pidof java)" ]; then
- echo "Elasticsearch is already running."
- return 1
- fi
- # Make sure Elasticsearch user owns the data directories
- chown -R $ES_USER:$ES_GROUP $ES_HOME/
- daemon "$ES_BIN/elasticsearch"
- echo "Elasticsearch started."
- }
- stop() {
- if [ ! "$(pidof java)" ]; then
- echo "Elasticsearch is not running."
- return 1
- fi
- kill `pgrep -u $ES_USER -f 'java.*org.elasticsearch.bootstrap.Elasticsearch'`
- kill `pgrep -u elk -f 'java.*org.elasticsearch.bootstrap.Elasticsearch'`
- echo "Elasticsearch stopped."
- }
- restart() {
- stop
- start
- }
- case "$1" in
- start)
- start
- ;;
- stop)
- stop
- ;;
- restart)
- restart
- ;;
- *)
- echo "Usage: $0 {start|stop|restart}"
- exit 1
- ;;
- esac
- exit 0
- =============================服务单元脚本===========================================
- [Unit]
- Description=Elasticsearch 8.12.1 Service
- Documentation=https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
- Wants=network-online.target
- After=network-online.target
- [Service]
- Type=notify
- User=elk
- Group=elk
- ExecStart=/usr/local/elasticsearch/bin/elasticsearch -d
- Restart=on-failure
- LimitNOFILE=65536
- Environment="JAVA_HOME=/usr/local/elasticsearch-8.12.1/jdk"
- Environment="ES_JAVA_OPTS=-Xms512m -Xmx512m"
- [Install]
- WantedBy=multi-user.target
- =============================服务单元脚本===========================================
- chmod +x /etc/init.d/elasticsearch
- # 更改脚本的拥有者
- chown elk:elk /etc/init.d/elasticsearch
- # 添加开机自启动
- chkconfig --add /etc/init.d/elasticsearch
安装 Logstash
Logstash 管道有两个必需的元素,input 和 output,以及一个可选的元素,filter。input 输入插件使用来自源的数据,filter 过滤器插件在你指定时修改数据,output输出插件将数据写入目标。
- # 解压安装包
- tar -zxvf logstash-8.4.0-linux-x86_64.tar.gz -C /usr/local/
- # 做软连接
- ln -s /usr/local/logstash-8.4.0/bin/* /usr/local/bin/
logstash -e 'input {stdin{}} output {stdout{}}'
- -e:立即执行,使用命令行里的配置参数启动实例
- -f:指定启动实例的配置文件
- -t:测试配置文件的正确性
- -r, --config.reload.automatic 监视配置更改,并在更改配置时重新加载配置文件。注意:使用 SIGHUP 手动重新加载配置。默认为 false。
- stdin 标准输入,stdout 标准输出。
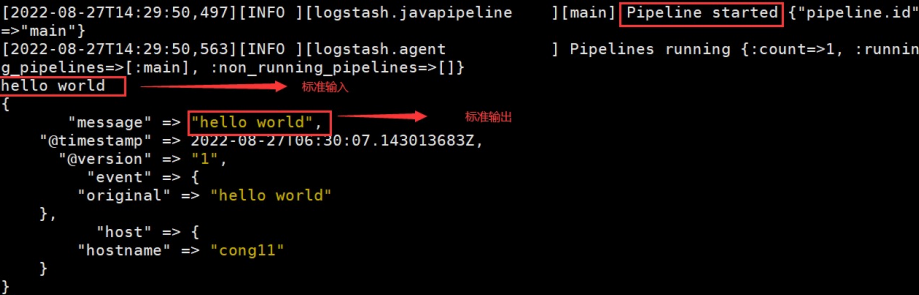
① 使用配置文件启动服务
- vim /usr/local/logstash-8.4.0/config/logstash.conf
- input {
- file {
- # 收集来源,这里收集系统日志
- path => "/var/log/messages"
- # start_position 选择 logstash 开始读取文件的位置,begining 或者 end。
- # 默认是 end,end 从文件的末尾开始读取,beginning表示从文件开头开始时监控
- start_position => "beginning"
- }
- }
- # 数据处理,过滤,为空不过滤
- filter {
- }
- output { #输出插件,将事件发送到特定目标。
- elasticsearch { #将事件发送到 es,在 es 中存储日志
- hosts => ["192.168.1.11:9200"]
- #index 表示事件写入的索引。可以按照日志来创建索引,以便于删旧数据和按时间来搜索日志
- index => "var-messages-%{+yyyy.MM.dd}"
- }
- stdout { codec => rubydebug } # stdout 标准输出,输出到当前终端显示、屏
- }
注:上述文件复制时必须去除多余空格。这个配置文件只是简单测试 logstash 收集日志功能。 还有很多的 input/filter/output 插件类型,可以参考官方文档来配置。https://www.elastic.co/guide/en/logstash/current/index.html
logstash -f /usr/local/logstash-8.12.1/config/logstash.conf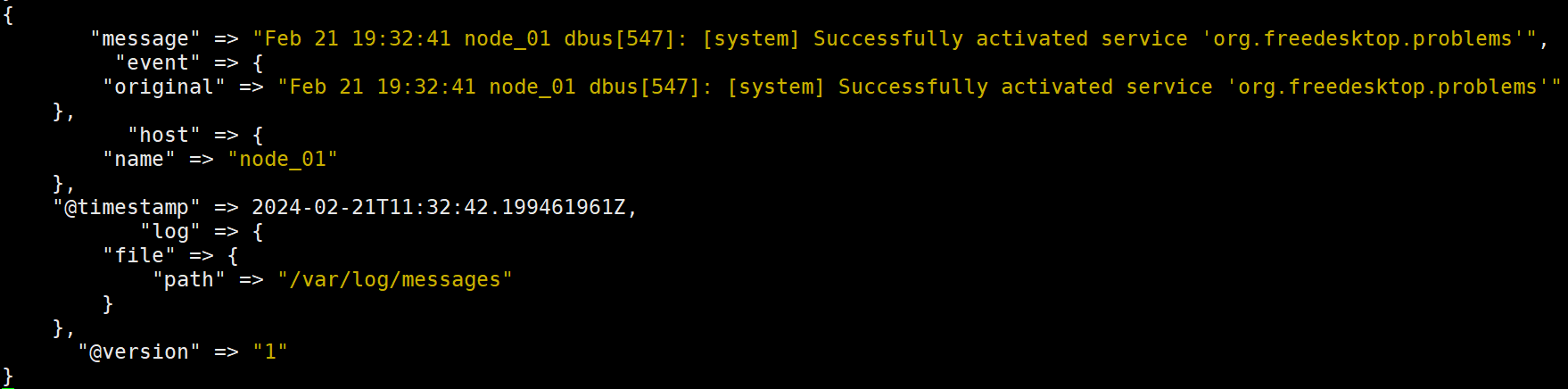
② 测试模拟写入日志
- # 打开新终端,往/var/log/messages 插入测试数据
- echo "$(date) hello world" >> /var/log/messages
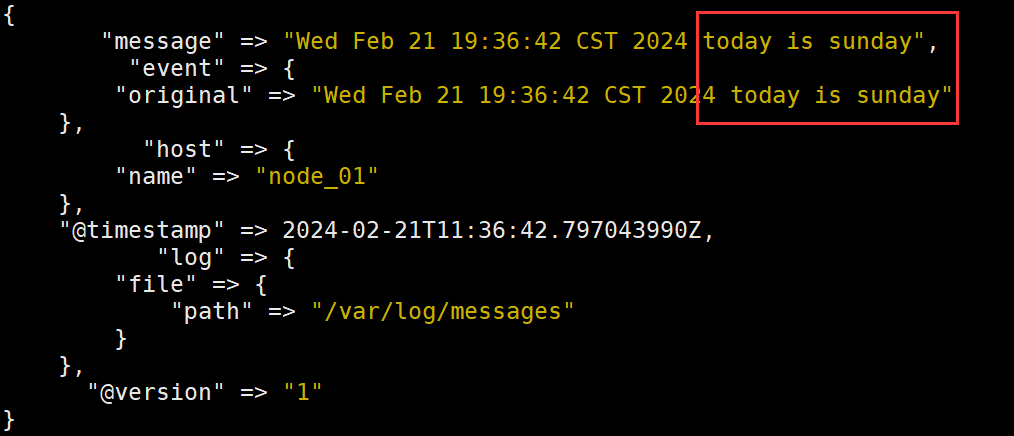
③ 查看 ES 是所有索引和状态
curl -XGET http://192.168.137.101:9200/_cat/indices?v- -X 指定与 HTTP 服务器通信时的请求方式, 默认 GET

④ 查看某个索引结构信息
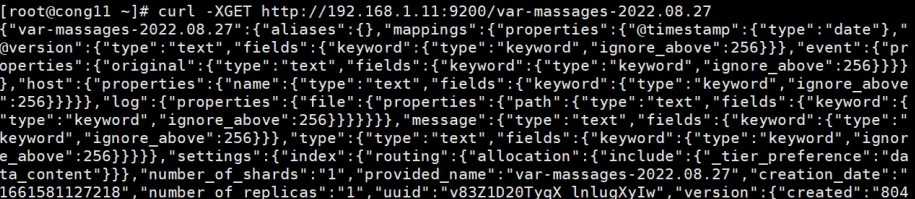
curl -XGET http://192.168.137.101:9200/var-massages-2024.02.21
⑤ 查看某个索引所有文档数据
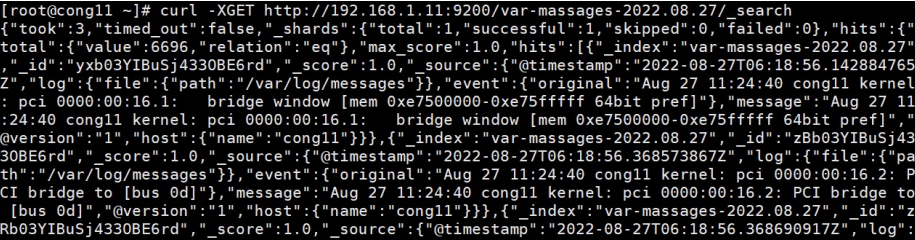
curl -XGET http://192.168.137.101:9200/var-massages-2024.02.21/_search
⑥ 后台启动程序
nohup logstash -f /usr/local/logstash-8.12.1/config/logstash.conf &
- # 设置开机自启动
- echo "source /etc/profile" >> /etc/rc.local
- echo "nohup logstash -f /usr/local/logstash-8.12.1/config/logstash.conf &" >> /etc/rc.local
- chmod +x /etc/rc.local
安装 Kibana
下载 kibana 后,解压到对应的目录就完成 kibana 的安装。
tar -zxvf kibana-8.12.1-linux-x86_64.tar.gz -C /usr/local/① 修改配置文件
- vim /usr/local/kibana-8.4.0/config/kibana.yml
- #开启以下选项并修改
- server.port: 5601
- server.host: "192.168.137.101"
- # 修改 elasticsearch 地址,多个服务器请用逗号隔开。
- elasticsearch.hosts: ["http://192.168.137.101:9200"]
注意: host:与 IP 地址中间有个空格不能删除,否则报错。
② 启动服务
- # 前台启动服务:Kibana should not be run as root. Use --allow-root to continue.
- /usr/local/kibana-8.4.0/bin/kibana --allow-root

- # 设置后台启动 |
- nohup /usr/local/kibana-8.4.0/bin/kibana --allow-root &
- # 查看端口
- netstat -antlp | grep 5601

- # 添加开机自启动
- echo "nohup /usr/local/kibana-8.12.1-linux-x86_64/bin/kibana --allow-root &" >> /etc/rc.local
③ 访问界面:http://192.168.137.101:5601/app/home#/
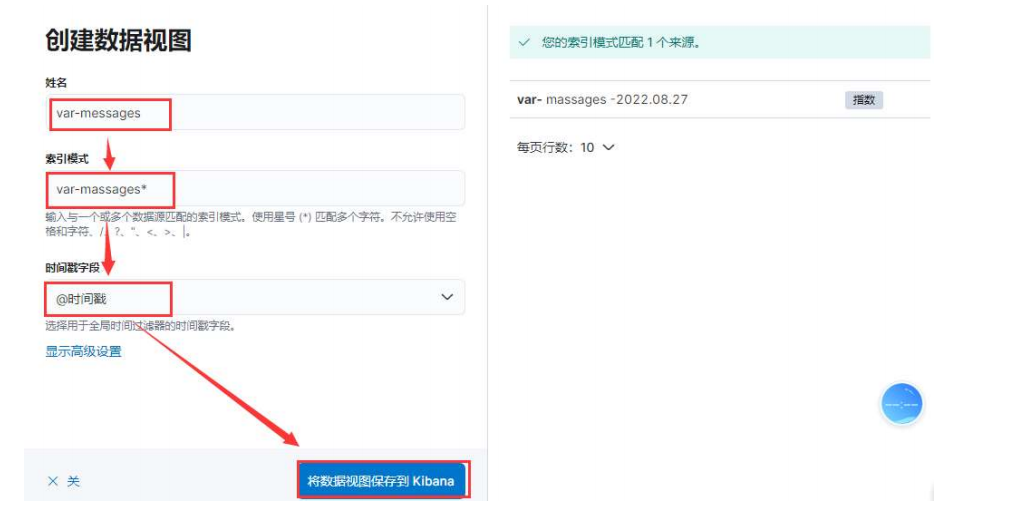
④ 创建一个索引

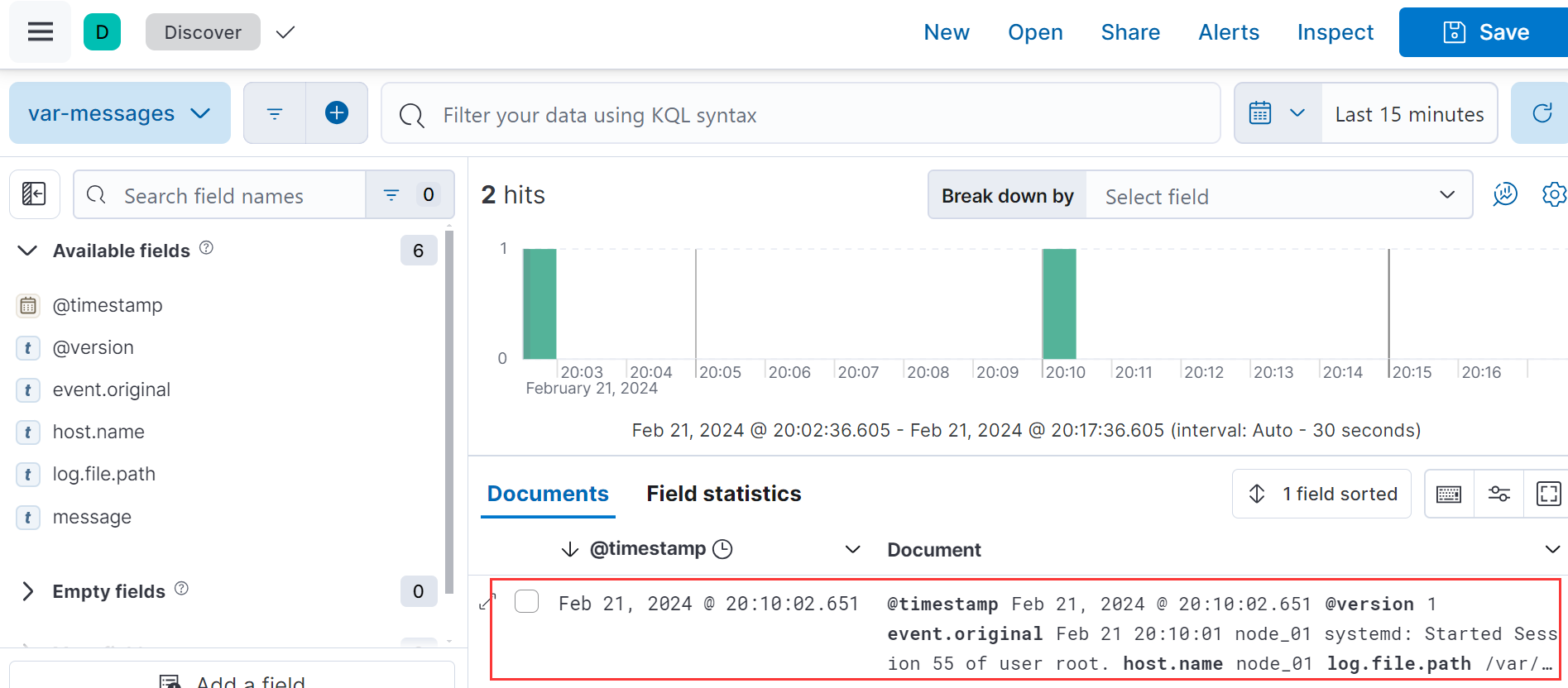
⑤ 使用过滤器过滤数据:过滤日志中包含 hello 的日志

设置 Kibana8 汉化
- vim /usr/local/kibana-8.12.1/config/kibana.yml
- -----------------------------------------------
- i18n.locale: "zh-CN"
- -----------------------------------------------
- ps -ef | grep kibana
- kill -9 1901
- /usr/local/kibana-8.12.1/bin/kibana --allow-root
- http://192.168.1.11:5601/app/home#/
Logstash filter 的使用
安装 httpd + filebeat
在 node-02 上部署 httpd 服务器,然后安装 filebeat,使用 filebeat 收集 httpd 日志文件,把收集到的日志发送给 logstash,让 logstash 过滤日志,把过滤完的日志保存到 elasticsearch,然后通过 kibana 展示出来。
① 安装 httpd
- # 安装 httpd
- yum install -y httpd
- # 启动 httpd
- systemctl start httpd
- # 设置开机自启动
- systemctl enable httpd
② 安装 filebeat
- # 解压缩软件
- tar -zxvf filebeat-8.12.1-linux-x86_64.tar.gz -C /usr/local/
- # 修改配置文件
- vim /usr/local/filebeat-8.12.1-linux-x86_64/filebeat.yml
- - type: filestream
- enabled: true #开启此配置
- paths:
- - /var/log/httpd/* #添加收集 httpd 服务日志
- #- /var/log/* #注释这 4 行
- #output.elasticsearch:
- # Array of hosts to connect to.
- #hosts: ["localhost:9200"]
- output.logstash: #取消注释,把日志放到 logstash 中
- # The Logstash hosts
- hosts: ["192.168.137.101:5044"] #取消注释,修改 logstash 服务器 IP 和端口
- logging.level: warning #调整日志级别(等测试启动成功再修改)
- # 启动服务
- cd /usr/local/filebeat-8.12.1-linux-x86_64/
- # 前台启动启动服务
- ./filebeat -e -c filebeat.yml
- # 后台启动
- ./filebeat -e -c filebeat.yml &
- # 查看服务进程
- ps -ef | grep filebeat
- # 设置开机自启动
- echo " /usr/local/filebeat-8.12.1-linux-x86_64/filebeat -e -c ilebeat.yml & " >> /etc/rc.local
- chmod +x /etc/rc.local
配置 logstash
- vim /usr/local/logstash-8.12.1/config/http_logstash.conf
- ================================================================================
- # Sample Logstash configuration for creating a simple
- # Beats -> Logstash -> Elasticsearch pipeline.
- input {
- file{
- # 收集来源,这里收集系统日志
- path => "/var/log/messages"
- # start_position 选择logstash开始读取文件的位置,begining或者end。
- # 默认是end,end从文件的末尾开始读取,beginning表示从文件开头开始监控
- start_position => "beginning"
- }
- beats{
- # 设置编码器为utf8
- codec => plain{charset => "UTF-8"}
- port => "5044"
- }
- }
- # 数据处理,过滤,为空不过滤
- filter{}
- # 输出插件,将时间发送到特定目标
- output {
- # 标准输出,把收集的日志在当前终端显示,方便测试服务连通性
- # 编码器为rubydebug
- stdout{
- codec => "rubydebug"
- }
- # 将事件发送到es,在es中存储日志
- elasticsearch {
- hosts => ["http://192.168.137.101:9200"]
- #index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
- # index 表示事件写入的索引。可以按照日志来创建索引,以便于删除旧数据和时间来搜索日志
- index => "var-messages-%{+yyyy.MM.dd}"
- #user => "elastic"
- #password => "changeme"
- }
- elasticsearch{
- hosts => ["192.168.137.101:9200"]
- index => "httpd-logs-%{+YYYY.MM.dd}"
- }
- }
- ================================================================================
- # 杀死之前的logstash进程
- jps
- kill -9 1997
- # 启动 logstash
- logstash -f /usr/local/logstash-8.12.1/config/http_logstash.conf
- # 访问 cong12 httpd 服务
- http://192.168.1.12/
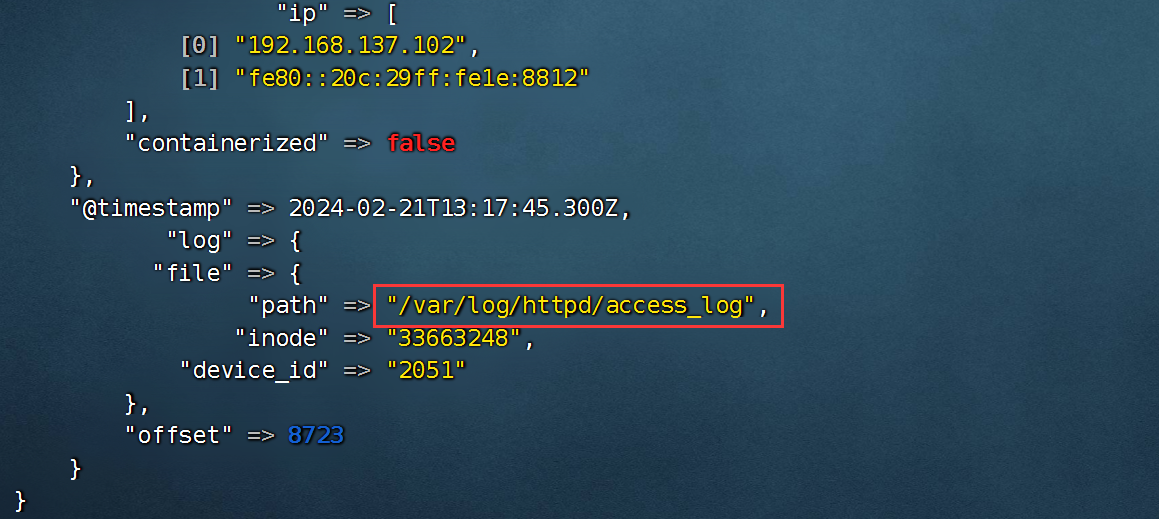
- # 开机自启动
- echo "nohup logstash -f /usr/local/logstash-8.12.1/config/http_logstash.conf" >> /etc/rc.local
配置 Kibana

打开新建的索引去查看收集到的日志,可以通过刚才添加的时间过滤器查看你想要的看到的日志。
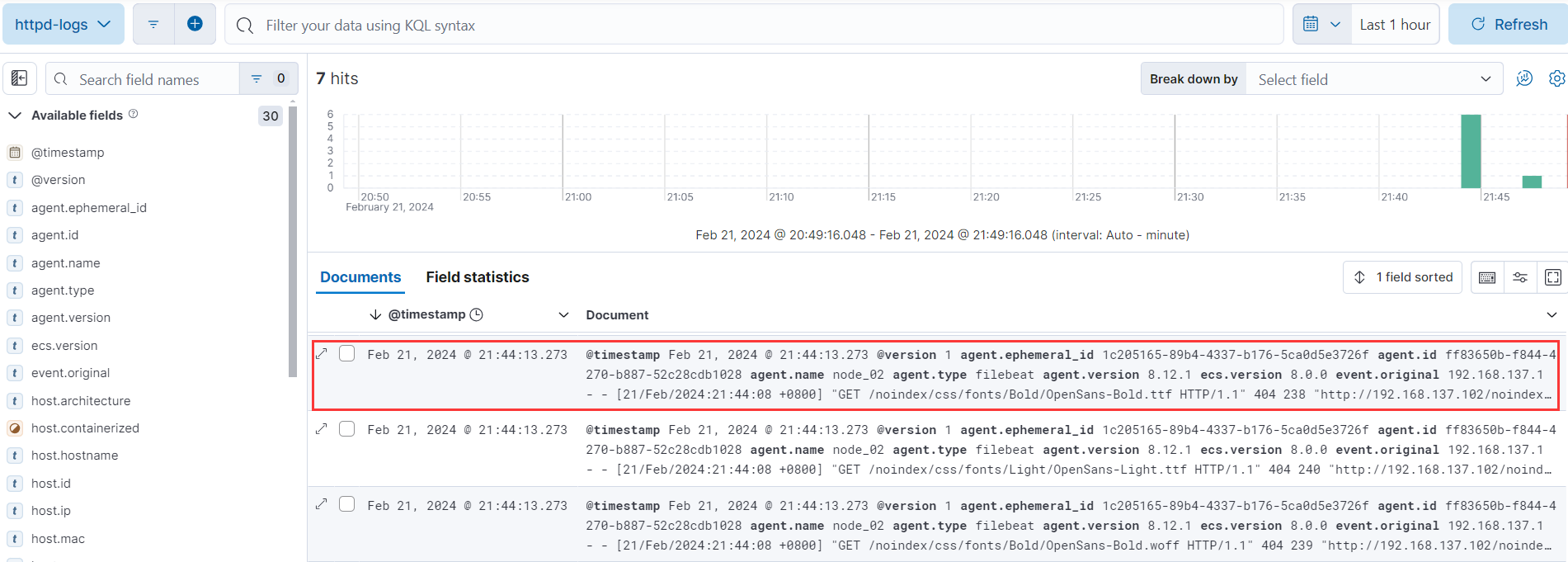
① 添加过滤器
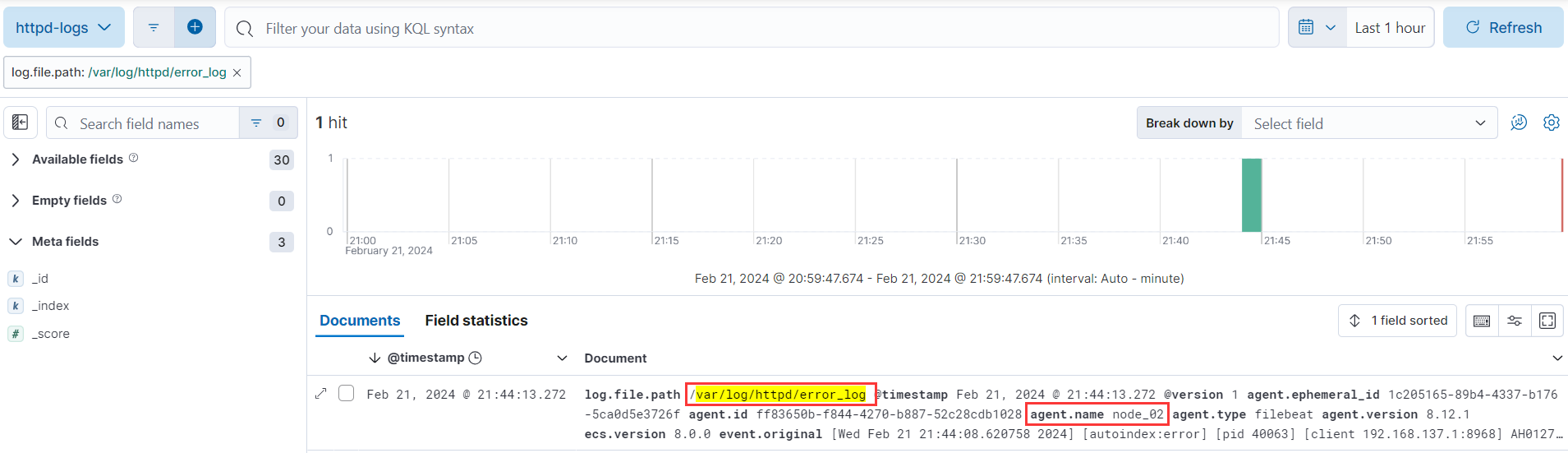
我们可以在搜到的日志继续添加过滤器,过滤出我们想要的内容,比如,我想看下 httpd 的错误日志,那么添加一个 log_file.path 为/etc/httpd/logs/error_log 的过滤器,如果我们监控的服务器比较多,我可以查看特定的主机的 httpd 错误日志添加类型为 log_file.path 的过滤器。

过滤主机的字段名称叫 agent.hostname,添加 agent.hostname 为 node02 的过滤器,所有的过滤器字段在显示的日志上面可以看到。
部署 Kafka + Zookeeper
为了防止收集的日志信息太多或者是服务器服务器 down 机导致的信息丢失,我们这里引入 kafka 消息队列服务器,我们这里搭建单节点的 kafka,生产环境中应该使用集群方式部署。
① 安装JDK
由于 zookeeper 依赖 java 环境,所以我们需要安装 jdk,官网建议最低安装 jdk1.8 版本
- tar -zxvf jdk-8u351-linux-x64.tar.gz -C /usr/local
- # 配置环境变量
- vim /etc/profile
- JAVA_HOME=/usr/local/jdk1.8.0_351
- PATH=$PATH:$JAVA_HOME/bin
- CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- export PATH JAVA_HOME CLASSPATH
- # 重载该文件
- source /etc/profile
- # 查看java版本
- java -version
② 安装Zookeeper
- # 解压安装装包
- tar -zxf apache-zookeeper-3.7.1-bin.tar.gz -C /usr/local/
- # 创建快照日志存放目录:
- mkdir -p /data/zk/data
- # 创建事务日志存放目录:
- mkdir -p /data/zk/datalog
- # 配置zookeeper
- cd /usr/local/apache-zookeeper-3.7.1-bin/conf/
- cp zoo_sample.cfg zoo.cfg
- vim zoo.cfg
- ----------------------------------------
- dataDir=/data/zk/data
- dataLogDir=/data/zk/datalog
- ----------------------------------------
- # 添加 path 环境变量:这里必须是修改配置文件添加 path 环境变量,不然启动报错
- vim /etc/profile
- ---------------------------------------------------------------
- export ZOOKEEPER_HOME=/usr/local/apache-zookeeper-3.7.1-bin
- export PATH=$ZOOKEEPER_HOME/bin:$PATH
- ---------------------------------------------------------------
- source /etc/profile
- # 服务单元文件
- vim /lib/systemd/system/zookeeper.service
- -------------------------------------------------------------------------
- [Unit]
- Description=Zookeeper service
- After=network.target
- [Service]
- Type=forking
- Environment="JAVA_HOME=/usr/local/jdk1.8.0_351"
- User=root
- Group=root
- ExecStart=/usr/local/apache-zookeeper-3.7.1-bin/bin/zkServer.sh start
- ExecStop=/usr/local/apache-zookeeper-3.7.1-bin/bin/zkServer.sh stop
- [Install]
- WantedBy=multi-user.target
- -------------------------------------------------------------------------
- # 重载systemctl程序
- systemctl daemon-reload
- systemctl start zookeeper
- systemctl enable zookeeper
- # 查看zookeeper进程
- jps -m

- # 查看Zookeeper状态
- zkServer.sh status

③ 部署 Kafka
这里部署的是 kafka 单节点,生产环境应该部署 kafka 多节点集群。
- # 解压软件到指定目录
- tar -zxvf kafka_2.13-3.2.1.tgz -C /usr/local/
- # 修改配置文件
- vim /usr/local/kafka_2.13-3.2.1/config/server.properties
- -----------------------------------------------------------
- # broker 的全局唯一编号,不能重复
- broker.id=0
- # 监听
- listeners=PLAINTEXT://:9092 #开启此项
- # 日志目录
- log.dirs=/data/kafka/log #修改日志目录
- # 配置 zookeeper 的连接(如果不是本机,需要该为 ip 或主机名)
- zookeeper.connect=localhost:2181
- -----------------------------------------------------------
- # 创建日志目录
- mkdir -p /data/kafka/log
- # 添加 path 环境变量
- vim /etc/profile
- -----------------------------------------------------------
- export KAFKA_HOME=/usr/local/kafka_2.13-3.2.1
- export PATH=$KAFKA_HOME/bin:$PATH
- -----------------------------------------------------------
- source /etc/profile
- # 服务单元文件
- vim /lib/systemd/system/kafka.service
- -------------------------------------------------------------------------
- [Unit]
- Description=Apache Kafka server(broker)
- After=network.service zookeeper.service
- [Service]
- Type=simple
- Environment="PATH=/usr/local/jdk1.8.0_351/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
- User=root
- Group=root
- ExecStart=/usr/local/kafka_2.13-3.2.1/bin/kafka-server-start.sh /usr/local/kafka_2.13-3.2.1/config/server.properties
- ExecStop=/usr/local/kafka_2.13-3.2.1/bin/kafka-server-stop.sh
- Restart=on-failure
- [Install]
- WantedBy=multi-user.target
- -------------------------------------------------------------------------
- # 重载systemctl程序
- systemctl daemon-reload
- systemctl start kafka
- systemctl enable kafka
- # 查看kafka进程
- jps -m

filebeat 发送数据至 kafka
我们这里修改 filebeat 配置文件,把 filebeat 收集到的 httpd 日志保存到 kafka 消息队列中。把 output.elasticsearch 和 output.logstash 都给注释掉,添加 kafka 项。
vim /usr/local/filebeat-8.12.1-linux-x86_64/filebeat.yml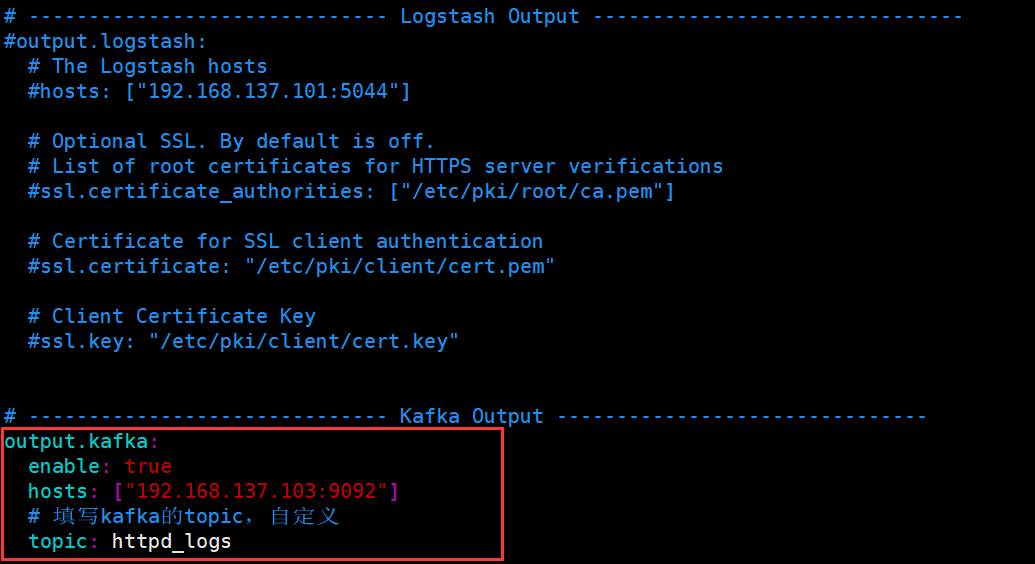
注意: kafka 中如果不存在这个 topic,则会自动创建。如果有多个 kafka 服务器,可用逗号分隔。
① 修改hosts
这里需要添加 kafka 的 hosts 解析,如果不添加会报如下错误:
- vim /etc/hosts
- 192.168.137.102 node_02
- 192.168.137.103 node_03
② 重启服务
- ps -ef | grep filebeat
- kill -9 946
- cd /usr/local/filebeat-8.12.1-linux-x86_64/ && ./filebeat -e -c filebeat.yml &
③ 刷新 httpd 页面 :http://192.168.137.102/,查看 kafka 上所有的 topic 信息
- # 在 kafka 服务器上查看 filebeat 保存的数据,topice 为 httpd_logs
- kafka-topics.sh --bootstrap-server node_03:9092 --list

- # 启动一个消费者获取信息
- kafka-console-consumer.sh --bootstrap-server localhost:9092 \
- --topic httpd_logs --from-beginning
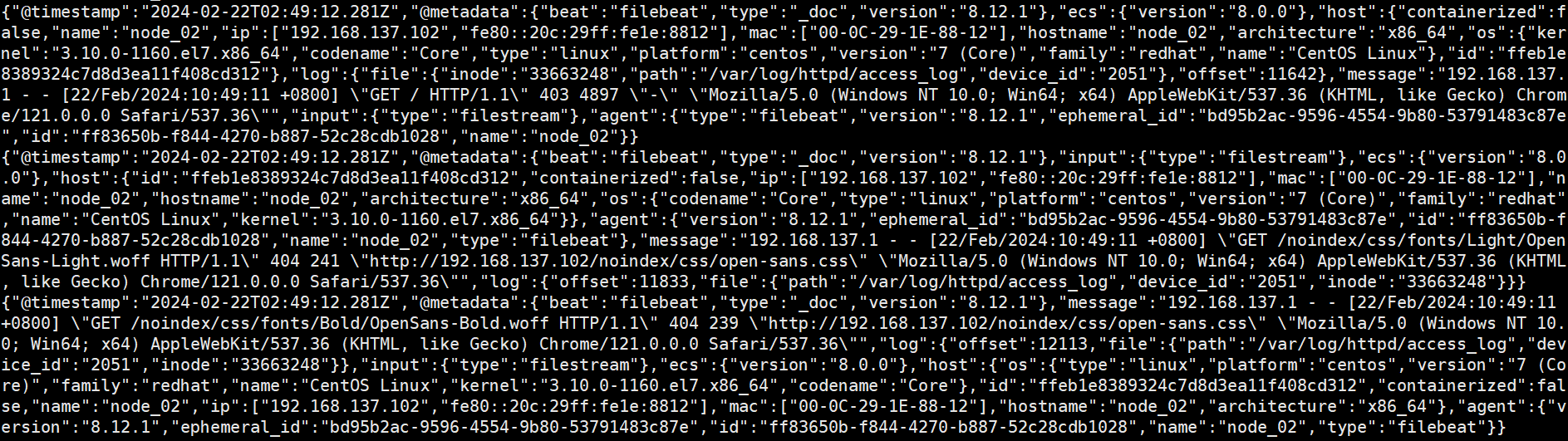
logstash 从 kafka 获取数据
配置 logstash 去 kafka 拿取数据,进行数据格式化,然后把格式化的数据保存到 Elasticsearch,通过 kibana 展示给用户。kibana 是通过 Elasticsearch 进行日志搜索的。
filebeat 中 message 要么是一段字符串,要么在日志生成的时候拼接成 json 然后在 filebeat 中指定为 json。但是大部分系统日志无法去修改日志格式,filebeat 则无法通过正则去匹配出对应的 filed,这时需要结合 logstash 的 grok 来过滤。
① 添加 hosts 解析
- vim /etc/hosts
- 192.168.137.101 node_01
- 192.168.137.102 node_02
- 192.168.137.103 node_03
② 修改 logstash 配置文件
- vim /usr/local/logstash-8.4.0/config/http_logstash.conf
- input{
- kafka {
- codec => plain{charset => "UTF-8"}
- bootstrap_servers => "192.168.1137.103:9092"
- # 这里设置 client.id 和 group.id 是为了做标识
- client_id => "httpd_logs"
- group_id => "httpd_logs"
- # 设置消费 kafka 数据时开启的线程数,一个partition 对应一个消费者消费,
- # 设置多了不影响,在 kafka 中一个进程对应一个线程
- consumer_threads => 5
- # 从最新的偏移量开始消费
- auto_offset_reset => "latest"
- # 此属性会将当前 topic,offset,group,partition 等信息>也带到 message 中
- decorate_events => true
- topics => "httpd_logs"
- }
- }
- output {
- stdout {
- codec => "rubydebug"
- }
- elasticsearch {
- hosts => [ "192.168.137.101:9200" ]
- index => "httpd-logs-%{+YYYY.MM.dd}"
- }
- }
可以使用相同的 group_id 方式运行多个 Logstash 实例,以跨物理机分布负载。主 题中的消息将分发到具有相同的所有 Logstash 实例 group_id。Kafka input 参数详解:
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-kafka.html
③ 重启 logstash
- jps -m
- kill -9 891
- logstash -f /usr/local/logstash-8.12.1/config/logstash.conf
④刷新 apache 页面,产生数据:http://192.168.1.12/
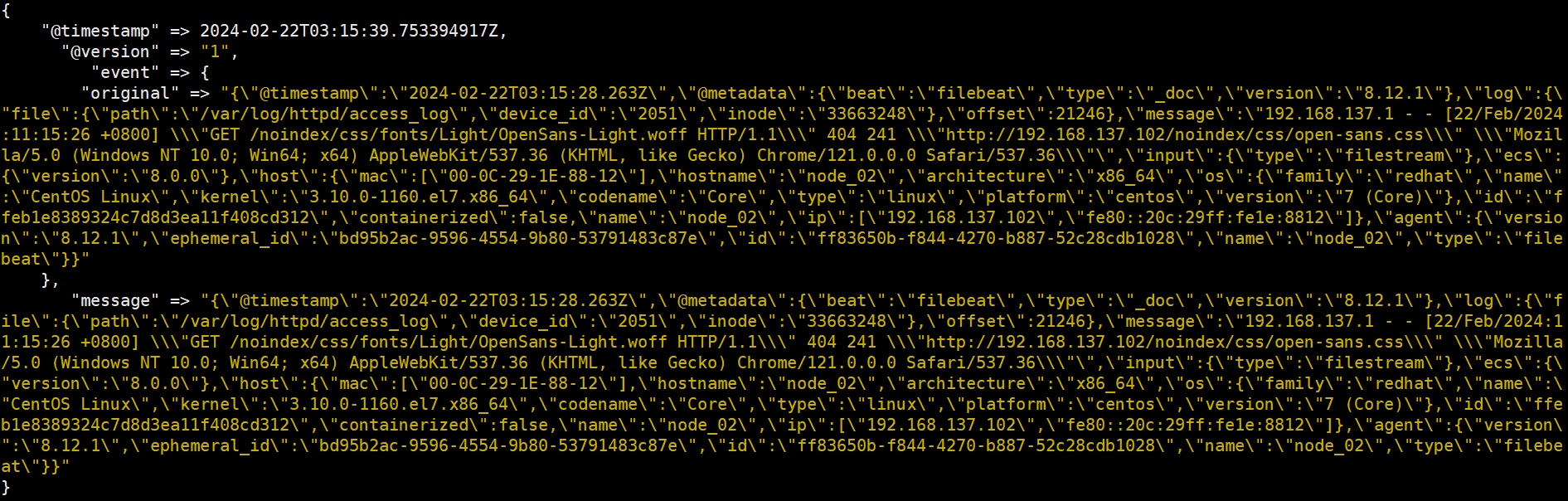
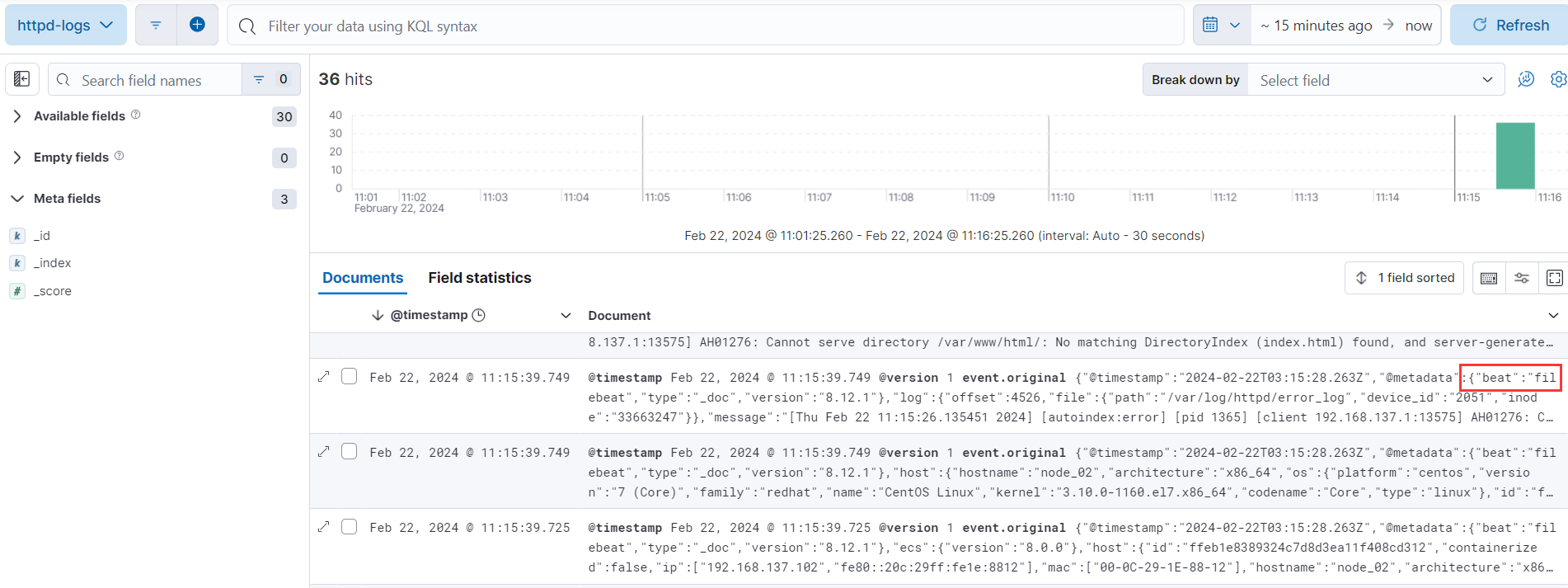
-
相关阅读:
Java excel poi 读取已有文件 ,动态插入一列数据
nacos2.0.2漏洞分析及解决方法
Leecode刷题 412. Fizz Buzz——二级指针、字符串数组、malloc
牛客网刷题篇
电大搜题——学习的好机会
Centos7软件包管理(rpm、yum)
java基于springboot+vue的自习室座位预约系统 elementui
ASP .NET Core API(swaggerUI)实例demo下载、发布与部署(各种遇到的坑、解决方法)
Linux网络配置,常用命令及远程工具
边缘检测--学习笔记
- 原文地址:https://blog.csdn.net/Yuanshigou9/article/details/136232782
