-
B-树(高阶数据结构)
目录
一、常见的搜索结构
种类 数据格式 时间复杂度 顺序查找 无要求 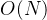
二分查找 有序 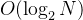
二叉搜索树 无要求 到二叉平衡树(AVL树和红黑树) 无要求 哈希 无要求 
以上结构适合用于数据量相对不是很大,能够一次性存放在内存中,进行数据查找的场景(内查找)
存在问题
若数据量很大,假设有100G数据,无法一次放进内存中,那就只能放在磁盘上了。若放在磁盘上,有时需要搜索某些数据,那么该如何处理呢?
可以考虑将存放关键字及其映射的数据的地址放到一个内存中的搜索树的节点中。要访问数据时,取这个地址去磁盘访问数据
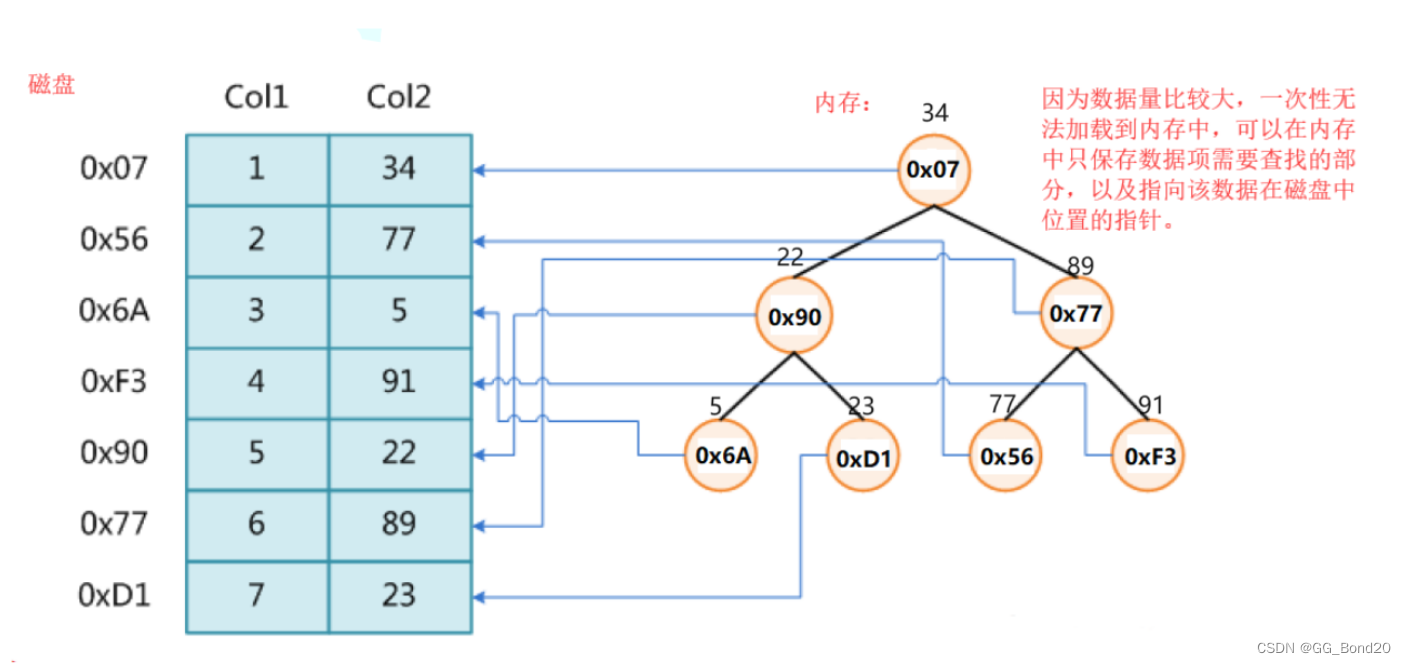
但是这么做依然存在问题
使用二叉平衡树的缺陷
平衡二叉树搜索树的高度是
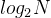 ,这个查找次数在内存中是很快的。但是当数据都在磁盘中时,访问磁盘速度很慢,在数据量很大时,次的磁盘访问,是一个难以接受的结果
,这个查找次数在内存中是很快的。但是当数据都在磁盘中时,访问磁盘速度很慢,在数据量很大时,次的磁盘访问,是一个难以接受的结果注意:一旦读/写磁头正确定位,并且盘片已经旋转到所要页面的开头位置,对磁盘的读写就完全电子化了(除了磁盘的旋转外),磁盘能够快速地读写大量的数据。所以IO次数是影响效率的重要因素
使用哈希表的缺陷
哈希表的效率很高是
,但是一些极端场景下某个位置冲突很多,导致访问次数剧增,也是难以接受的该如何加速对数据的访问呢?
- 提高IO的速度(SSD相比传统机械硬盘快了不少,但是还是没有得到本质性的提升)
- 降低树的高度,从而减少IO次数 —— 多叉树平衡树
二、B-树的概念
2.1 基础概念
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树(有些地方的B树写的的是B-树,注意不要误读成"B减树")
一棵m阶(m>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足以下性质:
- 根结点至少有两个孩子
- 每个分支结点都包含
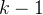 个关键字和
个关键字和 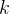 个孩子,其中
个孩子,其中 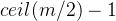 ,
, 是向上取整函数
是向上取整函数 - 每个叶子结点都包含 个关键字,其中
- 所有的叶子结点都在同一层
- 每个结点中的关键字从小到大排列,结点中 个元素正好是 个孩子包含的元素的值域划分
- 每个结点的结构为:
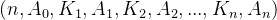 其中,
其中,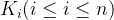 为关键字,且
为关键字,且 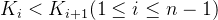 。 为指向子树根结点的指针,且
。 为指向子树根结点的指针,且 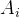 所指子树所有结点中的关键字均小于 。
所指子树所有结点中的关键字均小于 。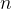 为结点中关键字的个数,满足
为结点中关键字的个数,满足 
2.1 插入过程分析
为了方便讲解,这里B-树的阶数取小一点,即3
即三阶B-树(三叉平衡树),那每个结点最多存储两个关键字,两个关键字可以将区间分割成三个部分,因此节点应该有三个孩子(子树)

为了后续实现简单,关键字和孩子都多给一个空间,结点的结构如下:

下面使用序列{53,139,75,49,145,36,101}分析一下插入的过程
插入53
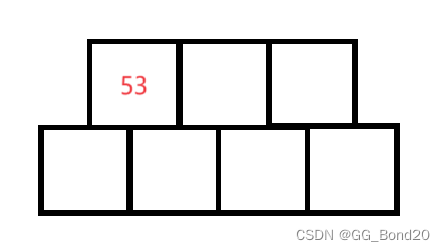
此时满足B-树性质,无需改变
插入139

关键字采用升序排序。此时满足性质
插入75

为什么要多开一个空间?可以在插入之后关键字顺序已经调整好的情况下去分裂,实现会方便很多
分裂结点
- 找到关键字序列的中间数,将关键字序列分成两半
- 新建一个兄弟结点,将右半边的m/2个关键字分给兄弟结点
- 将中间值提给父亲结点,新建结点成为其右孩子(没有父亲就创建新的根)
- 为什么中位数做父亲?——满足搜索树的大小关系(左<根<右)
- 结点指针链接起来

上面的规则中为什么要求除根结点外的所有非叶子结点都包含
个关键字,,即k的最小值是  ,即结点最少包含 个关键字
,即结点最少包含 个关键字
若m是奇数:9,那 是5,5-1是4。9个分裂之后正好两边每个结点都是4个关键字,中间的一个提取给父亲
若是偶数:10,那 是5,5-1是4。10个分裂的话,一边4个(最少的),一边5个,还有一个中间值提取给父亲,所以最少就是 个关键字插入49,145

插入36

此时36插入的这个结点又满了,需要进行分裂

新增一个兄弟结点之后,相当于父亲结点就多了一个孩子,所以也需要增加一个关键字(关键值始终比孩子少一个),就把中间值提给父亲结点。49上提插入到父亲,它比75小,所以75往后移(它的孩子也跟着往后移),然后49插入到前面
插入101
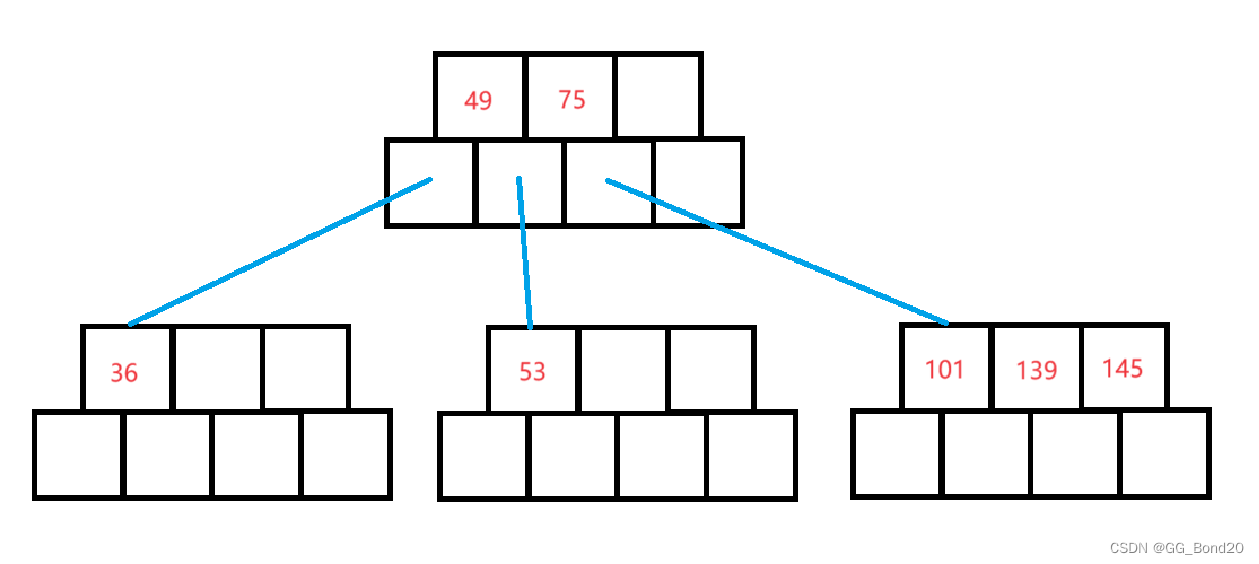
插入后结点的关键字数量大于m-1,进行分裂
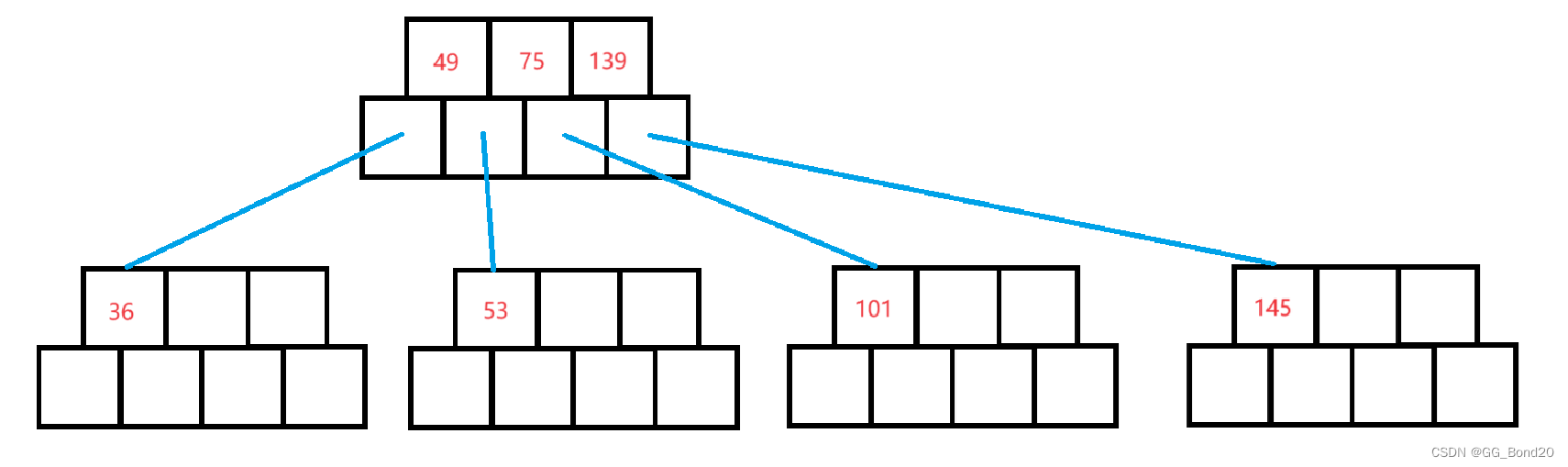
向上插入后,发现父结点也满了,所以还需继续分裂
B-树每一次插入之后都是天然的完全平衡,不像红黑树AVL树那样,插入之后不满足平衡条件了,再去调整。并且B-树的平衡是绝对平衡。每一棵树的左右子树高度之差都是0
为什么他能保持天然的完全平衡呢?
通过上面的插入过程可以发现B-树是向右和向上生成的,只会产生新的兄弟和父亲
2.2 插入过程总结
- 若树为空,直接插入新结点,该结点为树的根结点
- 树非空,找待插入关键字在树中的插入位置(找到的插入结点位置一定是叶子结点)
- 检测是否找到插入位置(假设树中的key唯一,即该元素已经存在时则不插入)
- 按照插入排序的思想将该关键字插入到找到的结点中
- 检测该结点关键字数量是否满足B-树的性质:即该节点中的元素个数是否等于M,若小于则满足,插入结束
- 若插入后结点不满足B树的性质,需要对该结点进行分裂:
申请新的兄弟结点
找到该结点的中间位置
将该结点中间位置右侧的元素以及其孩子搬移到新结点中
将中间位置元素(新建结点成为其右孩子)提取至父亲结点中插入,即继续4 - 若向上已经分裂到根节点的位置,插入结束
三、代码实现
3.1 结点设计
M叉树:即一个节点最多有M个孩子,M-1个数据域
为实现简单期间,数据域与孩子与多增加一个(原因参见上文对插入过程的分析)
- template<class K, size_t M>
- struct BTreeNode
- {
- BTreeNode():_parent(nullptr), _number(0) {
- for (int i = 0; i < M; ++i) {
- _keys[i] = K();
- _childs[i] = nullptr;
- }
- _childs[M] = nullptr;
- }
- //为了方便插入后再进行分裂操作,多给一个空间
- K _keys[M];
- BTreeNode
- BTreeNode
- size_t _number; //记录此时实际存储了多少个关键字
- };
3.2 B-树的查找
在插入之前需先找到,待插入关键字在树中的插入位置
- //Node*指向找到的结点,int为该元素在该结点中的位置
- pair
- {
- Node* parent = nullptr;
- Node* current = _root;
- int index = 0;
- while (current)//若结点存在
- {
- //在结点的值域中查找
- index = 0;
- while (index < current->_number)
- {
- if (key == current->_keys[index])
- return make_pair(current, index);
- else if (key < current->_keys[index])
- break; //该元素可能在i的左孩子结点中
- else ++index;
- }
- //在current中没有找到,到current结点的第index个孩子中查找
- parent = current;
- current = current->_childs[index];
- }
- return make_pair(parent, -1);
- }
3.3 插入key的过程
按照插入排序的思想插入key
- void InsertKey(Node* current, const K& key, Node* child)
- {
- int end = current->_number - 1;
- while (end >= 0)
- {
- if (key < current->_keys[end])
- {
- //挪动key和其右孩子
- current->_keys[end + 1] = current->_keys[end];
- current->_childs[end + 2] = current->_childs[end + 1];
- --end;
- }
- else break;
- }
- current->_keys[end + 1] = key;
- current->_childs[end + 2] = child;
- if(child)//若key的child不为空,则链接child的父指针
- child->_parent = current;
- ++current->_number;
- }
3.4 B-树的插入实现
- bool Insert(const K& key)
- {
- if (nullptr == _root)
- {
- _root = new Node;
- _root->_keys[0] = key;
- ++_root->_number;
- return true;
- }
- //找插入位置,若该元素已经存在,则不插入
- pair
- if (-1 != ret.second) return false;
- Node* current = ret.first;//待插入的叶子结点
- K newKey = key;
- Node* child = nullptr;
- //可能多次分裂,一直向上插入
- while (true)
- {
- InsertKey(current, newKey, child);
- //若没有满则操作结束
- if (current->_number < M) return true;
- //若满了则进行分裂
- Node* brother = new Node;
- size_t mid = (M >> 1);
- size_t i = mid + 1, j = 0;
- for (; i <= M - 1; ++i)
- {
- brother->_keys[j] = current->_keys[i];
- brother->_childs[j++] = current->_childs[i];
- if (current->_childs[i])
- current->_childs[i]->_parent = brother;
- //拷贝完成后进行重置,便于观察
- current->_keys[i] = K();
- current->_childs[i] = nullptr;
- }
- //孩子比关键字多搬移一个
- brother->_childs[j] = current->_childs[i];
- if (current->_childs[i])
- current->_childs[i]->_parent = brother;
- current->_childs[i] = nullptr;
- brother->_number = j;
- current->_number -= (brother->_number + 1);
- K midKey = current->_keys[mid];
- current->_keys[mid] = K();
- //若分裂的节点为根节点,重新申请一个新的根节点
- //将中间位置数据以及分裂出的新节点插入到新的根节点中,插入结束
- if (current == _root)
- {
- _root = new Node;
- _root->_keys[0] = midKey;
- _root->_childs[0] = current;
- _root->_childs[1] = brother;
- _root->_number = 1;
- current->_parent = _root;
- brother->_parent = _root;
- break;
- }
- //若分裂的节点不是根节点,将中间位置数据以及新分裂出的节点继续向current的双亲中进行插入
- else
- {
- newKey = midKey;
- child = brother;
- current = current->_parent;
- }
- }
- return true;
- }
3.5 B-树的简单验证
使用监视窗口查看
对B树进行中序遍历,若能得到一个有序的序列,说明插入正确
- void _InOrder(Node* root)
- {
- if (nullptr == root) return;
- for (int i = 0; i < root->_number; ++i) {
- _InOrder(root->_childs[i]);
- cout << root->_keys[i] << " ";
- }
- _InOrder(root->_childs[root->_number]);
- }
3.6 B-树的高度
含n个关键字的m阶B树,最小高度、最大高度是多少?
最小高度
n个关键字的m阶B树,关键字个数和B-树的阶数已经确定的话,若要让高度最小,就要让每个结点存的关键字最满
那对于m阶的B树来说,每个结点最多m-1个关键字,m个孩子。第一层肯定只有一个根结点(最满即为m-1个关键字,m个孩子),那第二层最多就有m个结点,每个结点最多m-1关键字,那第三层就是m*m个孩子,以此类推…...
假设高度为h,关键字的总个数
就等于: 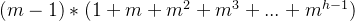
即
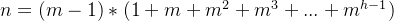 ,解得最小高度
,解得最小高度 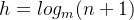
最大高度
要让树变得尽可能高的话,那就要让每个结点得关键字数量尽可能少(分支尽可能少)
第一层只有一个根结点(关键字最少是1,孩子是2),根结点最少两个孩子,所以第二层2个结点。又因为除了根结点之外的结点最少有
个孩子,所以第三层就最少有 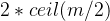 个结点,第四层就是
个结点,第四层就是 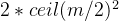 ,以此类推…...第h层就是
,以此类推…...第h层就是 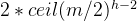 个结点
个结点所以得出:
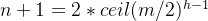 ,解得最大高度
,解得最大高度 ![h=[log_{ceil(m/2)}(n+1) / 2] + 1](https://1000bd.com/contentImg/2024/03/06/093454925.png)
3.7 B-树的性能
B-树的效率是很高的,对于N = 62*1000000000个节点,若度M为1024。查找最坏就是高度次,
![h=[log_{ceil(m/2)}(n+1) / 2] + 1 \approx log_{m/2}N](https://1000bd.com/contentImg/2024/03/06/093454883.png) ,
, 。即在620亿个元素中,若这棵树的度为1024,则需要小于4次即可定位到该节点,然后利用二分查找可以快速定位到该元素,大大减少了读取磁盘的次数
。即在620亿个元素中,若这棵树的度为1024,则需要小于4次即可定位到该节点,然后利用二分查找可以快速定位到该元素,大大减少了读取磁盘的次数四、B+树和B*树
4.1 B+树
B+树是B树的变形,是在B树基础上优化的多路平衡搜索树,B+树的规则跟B树基本类似,但是又在B树的基础上做了一些改进优化。
一棵m阶的B+树需满足下列条件:
- 每个分支结点最多有m棵子树(孩子结点)
- 非叶根结点至少有两棵子树,其他每个分支结点至少有
棵子树(前面这两条其实和B树是一样的)
- 结点的子树个数与关键字个数相等
- 结点的子树指针
![p[i]](https://1000bd.com/contentImg/2024/03/06/093454017.png) 指向关键字值大小在
指向关键字值大小在 ![[k[i], k[i+1])](https://1000bd.com/contentImg/2024/03/06/093454910.png) 区间之间
区间之间 - 所有叶子节点增加一个链接指针链接在一起
- 所有关键字及其映射数据都在叶子节点出现

B+树特性:
- 所有关键字都出现在叶子结点的链表中,且链表中的结点都是有序的
- 不可能在分支结点中命中
- 分支结点相当于叶子结点的索引,叶子结点才是存储数据的数据层
B+树与B树对比
- B+树所有值都在叶子,遍历方便,便于区间查找
- (MySQL中使用B+树)对于没有建立索引的字段,全表扫描的更加方便
- 分支结点只存储key。一个分支结点空间占用更小,可以尽可能的加载到缓存中(或者说:一个分支结点中可存储的key值更多,减少了磁盘IO次数)
- B树不一定要到叶子结点就可以找到所需的值,但B+树必须到叶子,但是B+树的高度足够低,所以差别不大
4.2 B*树
B*树是B+树的变形,在B+树的非根和非叶子结点再增加指向兄弟结点的指针
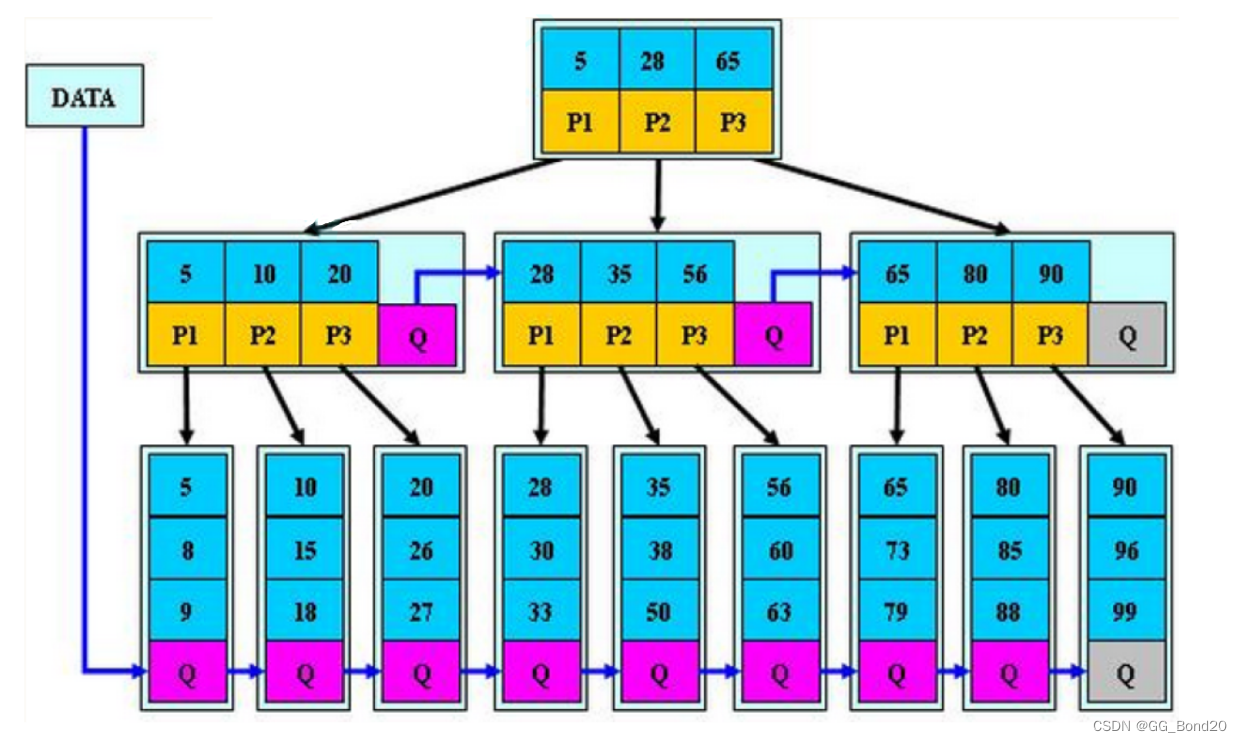
B+树的分裂:
当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以不需要指向兄弟的指针
B*树的分裂:
当一个结点满时,若它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);若兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针
所以B*树分配新结点的概率比B+树要低,空间使用率更高
五、总结
- B树:有序数组 + 平衡多叉树
- B+树:有序数组链表+平衡多叉树;
- B*树:一棵更丰满的,空间利用率更高的B+树
(内查找时)B树系列与哈希、平衡搜索树对比
单论树的高度以及查找效率,B树系列确实不错,但是B树系列也有一些缺点:
- 空间利用率低,消耗高
- 插入和删除数据时,分裂和合并结点,必然需要挪动数据
- 虽然B树系列高度更低,但在内存中与哈希、平衡搜索树还是一个量级
结论:实质上B树系列在内存中体现不出优势,更适合进行外查找
-
相关阅读:
Python之字符串、正则表达式练习
【NOI模拟赛】最大生成树(Brouvka算法,并查集)
前端工程化(vue2)
适配LVGL界面图片和文字显示很虚,色阶明显的解决方法(全志R128适用)
新能源商用车、物流车及末端配送车亮相2024快递物流展
隐式类型转换
Spring WebFlux 实践
HTB Runner
Linux 日志系统、auditd用户审计、kdump故障定位
CSS常用属性(二)
- 原文地址:https://blog.csdn.net/GG_Bruse/article/details/136263772
