什么是循环依赖?
这个情况很简单,即A对象依赖B对象,同时B对象也依赖A对象,让我们来简单看一下。
// A依赖了B
class A{
public B b;
}
// B依赖了A
class B{
public A a;
}
这种循环依赖可能会引发问题吗?
在没有考虑Spring框架的情况下,循环依赖并不会带来问题,因为对象之间相互依赖是非常普遍且正常的现象。
比如
A a = new A();
B b = new B();
a.b = b;
b.a = a;
这样,A,B就依赖上了。
然而,在Spring框架中存在一个令人头疼的问题,即循环依赖,这一问题的根源是什么呢?
在Spring框架中,一个对象的实例化并非简单地通过new关键字完成,而是经历了一系列Bean生命周期的阶段。正是由于这种Bean的生命周期机制,才导致了循环依赖问题的出现。在Spring应用中,循环依赖问题是一个常见现象,有些情况下Spring框架能够自动解决这种问题,但在其他情况下,需要开发人员介入并进行手动解决。接下来将详细探讨这些情况。
要深入理解Spring中的循环依赖,首先需要对Spring中Bean的完整生命周期有所了解。在这里不会深入展开对Bean生命周期的详细描述,因为之前的文章已经单独探讨过这一话题。因此,这里将简要概述Bean生命周期的大致过程。
Spring 管理的对象称为 Bean,通过Spring的扫描机制获取到类的BeanDefinition后,接下来的流程是:
- 解析BeanDefinition以实例化Bean:
a. 推断类的构造方法。
b. 利用反射机制实例化对象(称为原始对象)。 - 填充原始对象的属性,实现依赖注入。
- 如果原始对象中的方法被AOP增强,生成代理对象:
a. 根据原始对象生成代理对象。 - 将生成的代理对象存放到单例池(在源码中称为singletonObjects)中,以便下次直接获取。
这个过程简要描述了Spring容器在实例化Bean并处理AOP时的流程。
在Spring中,Bean的生成过程涉及多个复杂步骤,远不止上述简要提及的7个步骤。除了所列步骤外,还包括诸如Aware回调、初始化等繁琐流程,这些内容涉及的细节繁多,不在本文讨论范围。
在创建B类的Bean时,如果B类包含一个名为a的A类属性,那么在生成B的Bean时,需要确保A类的Bean已经存在。然而,由于B类Bean的创建条件是A类Bean的依赖注入过程,因此可能会导致循环依赖问题。这意味着在容器尝试实例化B类Bean时,它必须首先解决A类Bean的依赖关系,而A类Bean的实例化又依赖于B类Bean。所以这里就出现了循环依赖:
ABean创建-->依赖了B属性-->触发BBean创建--->B依赖了A属性--->需要ABean(但ABean还在创建过程中)
因此,这一系列问题最终导致无法成功创建ABean,进而也无法顺利创建BBean。
在这种循环依赖的情况下,正如前文所述,Spring通过一些机制来协助开发者解决部分循环依赖问题,这便是三级缓存。
三级缓存
在此简要介绍三级缓存的概念,随后在探讨AOP对象如何解决循环依赖问题时,将会对其进行更为详尽的回顾。
- 在Spring框架中,单例对象缓存在
singletonObjects中,其中存储的是已经经历了完整生命周期的bean对象。 earlySingletonObjects中的“early”一词表明其中缓存的是早期的bean对象。这里的“早期”指的是Bean的生命周期尚未完成,但已经将该Bean放入了earlySingletonObjects中。singletonFactories中存储的是ObjectFactory,即对象工厂,用于创建早期bean对象的工厂。
在前文的分析中,我们得知产生循环依赖问题的主要原因是Bean之间相互依赖,导致在创建Bean时出现了循环引用的情况。主要是:
A创建时--->需要B---->B去创建--->需要A,从而产生了循环
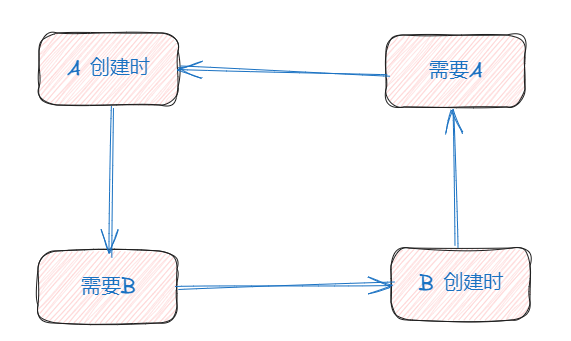
因此,我们现在将深入探讨为何缓存机制能够成功解决这种循环依赖难题。那么,如何打破这一循环呢?我们可以引入一个中间层(缓存)来化解。
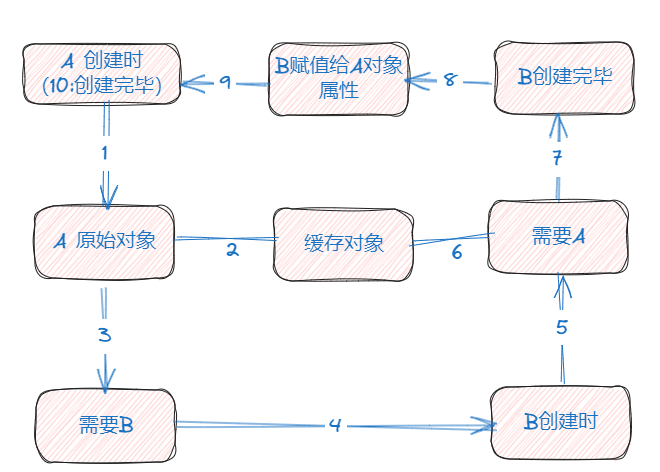
在A的Bean创建过程中,在执行依赖注入之前,首先将A的原始Bean提前放入缓存中,这样一来,其他Bean在需要时可以直接从缓存中获取,随后才进行依赖注入操作。
在这种情况下,当A的Bean依赖于B的Bean时,如果B的Bean尚不存在,则必须启动B的Bean创建流程。这一流程与A的Bean创建过程相似,首先生成B的原始对象,然后将其提前暴露并置入缓存中。
接着,在对B的原始对象执行依赖注入A操作时,此时可以从缓存中检索A的原始对象(尽管这仅为A的原始对象,尚非最终Bean状态)。当B的原始对象完成依赖注入后,B的生命周期随之终结,从而也促使A的生命周期得以顺利结束。
在整个流程中,只存在一个A原始对象,因此对于B而言,即使在属性注入阶段将A原始对象注入,也并不会有任何影响,因为A原始对象在随后的生命周期中保持不变,未在堆中发生任何变化。
总结
在文章中详细探讨了循环依赖问题及其解决思路分析,揭示了Spring所提供的Bean创建过程并非如我们所想象的那样简单。这一过程涉及众多复杂步骤,因此Spring引入了缓存机制,通过在后续阶段逐步维护堆中的初始对象,并逐步进行赋值来逐步完成Bean的创建。这种缓慢而谨慎的方式确保了Bean的正确创建。
然而,这种处理方式仅适用于普通对象的创建。我们了解到,Spring还涉及另一个重要特性,即面向切面编程(AOP)。根据这一逻辑,AOP代理对象可能会遇到一些问题,这将在接下来的章节中进行深入讨论。这也解释了为何Spring需要三级缓存而不仅仅是二级缓存的原因。