-
020—pandas 根据历史高考分段推断当前位次的分数
前言
每年各省都会公布高考「一分一段」表,它是是以「一分」为单位,统计考得该分数的考生人数和累计人数,每一个分数段上有多少人一目了然。考生通过分数分布表可以查询到相关成绩在全市的排名位次,方便对自己进行定位。本例中,我们将通过一个过往年份的「一分一段」表,来推断出当前位次在历史表中的分数。
思路:
假定我们对所有的考试同学从 1 到 n 进行编号,历史表 df_old 的位次,其实是一个排名区间,这个编号区间的同学所考的分数都是这个分数,代表着这个分数从多少到多少人。可以用 pandas 的 pd.Interval 对象来表达这个区间。在当前表 df 中计算时,我个看位次是否在这个区间时,如果在此区间内则取对应的分数。
二、使用步骤
1.引入库
代码如下(示例):
import pandas as pd from io import StringIO- 1
- 2
2.读入数据
代码如下(示例):
data1 = ''' 分数,位次 696,46 695,56 694,65 693,77 692,87 691,95 690,109 689,120 688,136 687,156 686,173 685,206 684,230 683,253 682,286 681,310 680,344 679,383 678,419 677,450 676,501 675,551 674,607 ''' df_old = pd.read_csv(StringIO(data1)) df_old- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29

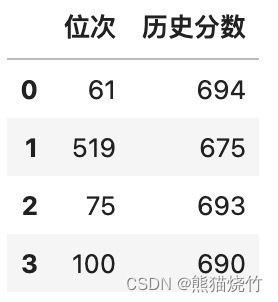
data2 = ''' 位次 61 519 75 100 ''' df = pd.read_csv(StringIO(data2)) df # 这里有有两张表: # 历史表:高考分数及分数对应的位次,位次是上一个分数和下一个分数人数的排名区间 # 当前表:只有排名位次,想看看在历史表中这个位次是多少分 # 所以,需求是: # 在当前表里增加一列表示位次对应的历史成绩- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

#先将历史表位次转为对应的区间对象,形成一个映射表: rng_map = ( # 增加辅助列,前一同学编号 df_old.assign(pre=df_old.位次.shift().add(1).fillna(1)) # 添加一列pre,表示位次的前一个值 .set_index('分数') .apply(lambda x: pd.Interval(x.pre, x.位次, closed='both'), axis=1) # 将pre和位次列的值转换为区间 ) rng_map.head()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

#然后编写一个函数供 df 当前表的位次来调用: def func(val: int): selected = [(val in i) for i in rng_map] # 判断位次值是否在区间范围内 foo = df_old[selected].分数.squeeze() # 获取满足条件的分数值 return foo #selected 为一个布尔序列,为 True 的表示在区间里,用其筛选历史表,得到了所在区间的一行数据,再用 squeeze() 降维转为标量返回。 #调用函数来增加新列: df.assign(历史分数=df.位次.map(func))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
# 其他方法: # 可以通过当前位次与历史位次查询的方法,取到最小的第一个分数值的方法。 # 指定位次小于等于历史位次,并取第一个 # 转为匿名函数调用,根据位次在df_old中查找对应的分数,并将结果赋给"历史分数"列 df.assign(历史分数=df.位次.map(lambda x: df_old[x <= df_old.位次] .head(1).分数.squeeze() ) )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
总结
以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
-
相关阅读:
什么是微网格?微网格规划应考虑哪些因素?
jsp344小区物业管理与疫情防控系统ssm
报表工具使用之FineReport大数据集导出插件
路由懒加载以 及 axios进阶用法
nodejs+vue+elementui医院挂号预约管理系统4n9w0
【万字长文】基于阿里云PAI平台搭建知识库检索增强的大模型对话系统
ArcGIS基础实战:面数据拓扑创建和错误修改全流程
VectorDraw Developer Framework 10.1004 Crack
Ubantu终端常用命令、快捷键和基本操作
Hyper-V 安装 CentOS (二)
- 原文地址:https://blog.csdn.net/2202_76035290/article/details/136282187