-
Bluesky数据采集框架-2
访问保存的数据
到此,自然想到了"我如何访问我保存的数据?"。从bluesky的视角,那真的不是bluesky的关注,但它是一个合理的问题,因此我们将强调一个特定的场景。
注意:本章假设你正在使用databroker。(我们在本教程的较早章节配置了)。你不是必须使用databorker来使用bluesky;它仅是一种捕获由RunEngine产生的元数据和数据的便捷方法。
非常简洁,你可以通过其唯一ID引用这个数据集(一个"run")来访问保存的数据,这个唯一ID是由RunEngine在采集时返回的。
- from bluesky.plans import count
- from ophyd.sim import det
- from databroker import Broker
- db = Broker.named('temp')
- # Insert all metadata/data captured into db.
- RE.subscribe(db.insert)
- uid, = RE(count([det], num=3))
- header = db[uid]
- # 另外,可能更方便,你可以按最近性访问它
- header = db[-1] # meaning '1 run ago', i.e. the most recent run

注意:我们假设以上计划产生一个"run"(数据集),它对像count()的简单计划有代表性。在一般情况中,一个计划可以产生多个runs,返回多个uids,它们接着使得db返回一个headers列表,而止一个。
- uids = RE(some_plan(...))
- headers = db[uids] # list of Headers
大部分有用数据在这个字典中:

数据的"primary"流像这样是可访问的:

从这里,我们参考datadroker教程。
简单的自定义
输入'partial'保存一些
假如我们总是使用相同的探测器(s)并且我们输出count([det])感到疲敝。我们可以使用Python自身提供的内建函数functools.partial()编写一个自定义的count()变体。
- from bluesky import RunEngine
- from functools import partial
- from bluesky.plans import count
- from ophyd.sim import det
- from bluesky.callbacks.best_effort import BestEffortCallback
- from databroker import Broker
- RE = RunEngine({})
- bec = BestEffortCallback()
- db = Broker.named('temp')
- RE.subscribe(bec)
- # Insert all metadata/data captured into db.
- RE.subscribe(db.insert)
- my_count = partial(count, [det])
- RE(my_count()) # equivalent to RE(count([det]))
- # Additional arguments to my_count() are passed through to count().
- RE(my_count(num=3, delay=1))
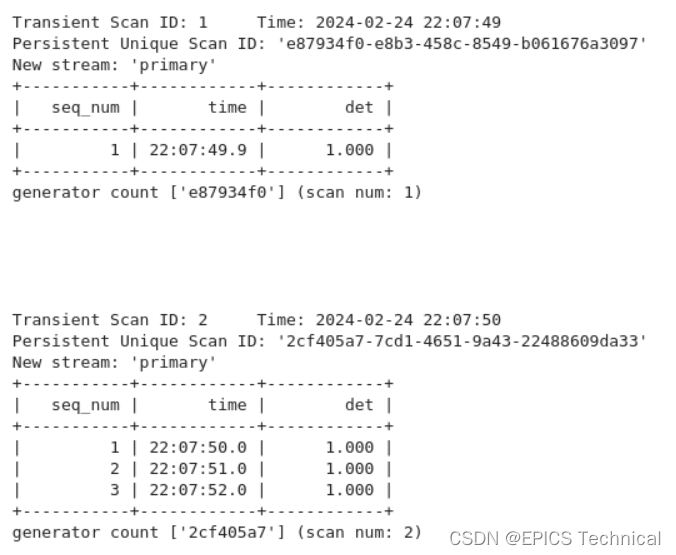
按顺序排列计划
一个自定义计划可以通过使用Python语法yield from派发给其他计划。(如果你想知道为什么,见附录)。示例:
- from bluesky.plans import scan
- from ophyd.sim import det, motor1
- dets=[det]
- def coarse_and_fine(detectors, motor, start, stop):
- "Scan from 'start' to 'stop' in 5 steps and then again in 6 steps."
- yield from scan(detectors, motor, start, stop, 5)
- yield from scan(detectors, motor, start, stop, 6)
- RE(coarse_and_fine(dets, motor1, -1, 1))

到目前为止介绍的我们从bluesky.plans导入的所有计划,产生数据集("run")。在blusesky.plan_stubs模块中的计划做更小的操作。它们可以单独使用或者组合来构建自定义计划。
mv()计划移动一个或多个设备并且等待它们都达到。
- from bluesky.plan_stubs import mv
- from ophyd.sim import motor1, motor2
- # Move motor1 to 1 and motor2 to 10, simultaneously. Wait for both to arrive.
- RE(mv(motor1, 1, motor2, 10))
我们像这样组合mv()和count()到一个计划:
- def move_then_count():
- "Move motor1 and motor2 into position; then count det."
- yield from mv(motor1, 1, motor2, 10)
- yield from count(dets)
- RE(move_then_count())
记住yield from非常重要。以下计划什么也不做!(在它中的计划将被定义,但不被执行)。
- # WRONG EXAMPLE!
- def oops():
- "Forgot 'yield from'!"
- mv(motor1, 1, motor2, 10)
- count(dets)
- RE(oops())

丰富得多的自定义是可能的,但我们留在本教程之后章节中。也见计划stubs的完整列表。
警告:
不要在一个循环或一个函数内放置"RE(...)" 。你应该总是直接调用它,在终端中由用户输入,并且仅一次。
你可能忍不住写一个像这样的脚本:
- from bluesky.plans import scan
- from ophyd.sim import motor, det
- # 不要做这件事!
- for j in [1, 2, 3]:
- print(j, 'steps')
- RE(scan([det], motor, 5, 10, j)))
也不要写这样的函数:
- # 不要做这件事!
- def bad_function():
- for j in [1, 2, 3]:
- print(j, 'steps')
- RE(scan([det], motor, 5, 10, j)))
你应该像这要做:
- from bluesky.plans import scan
- from ophyd.sim import motor, det
- def good_plan():
- for j in [1, 2, 3]:
- print(j, 'steps')
- yield from scan([det], motor, 5, 10, j)
- RE(my_plan())
如果你尝试隐藏RE在宇哥函数中,某人之后可能在另一个函数中使用这个函数,并且现在我们从单个提示进入和退出RunEngine多次。这会导致意外行为,尤其在处理中断和错误时。
打一个音乐比喻,计划是乐谱,硬件是乐队,而RunEngine是指挥。应该只有一个指挥,并且它需要从头到尾运行整个演出。
“Baseline”读取(和其他补充数据)
在实验中主要兴趣除了探测器和电机外,获取其他硬件快照("baseline读取")通常是有用的。这些信息一般用来检查随时间一致性。("样品支架的温度与它上周基本上相同吗?")。我们想要在所有未来实验过程中自动从这些设备捕获读数,每个实验无需任何额外思考或者输入。Bluesky为此提供了一个专用方法。
配置
注意:如果运行bluesky设施的访问用户,你不需要做此配置,并且你可以跳过下面的部分 - 选择"Baseline"设备。
你可以输入sd来检查。如果你获取了像这样的东西:
- In [17]: sd
- Out[17]: SupplementalData(baseline=[], monitors=[], flyers=[])
你应该跳过这个配置。
在我们开始前,我们必须多做一点RunEngine配置,像我们在RunEngine部分用RE.subscribe做的事情。
- from bluesky.preprocessors import SupplementalData
- sd = SupplementalData()
- RE.preprocessors.append(sd)
选择"Baseline"设备
我们将选择我们想要在每个数据集("Run")开始和结束时自动被读取的探测器/电机。如果你正在使用一个共享的配置,这可能已经被做好了,所以你应该在更改它前检查sd.baseline的内容。

假如我们想要从三个探测器和两个电机获取baseline读取。我们将为此目的导入一些仿真硬件,放它们到一个列表,并且分配sd.baseline。
- from ophyd.sim import det1, det2, det3, motor1, motor2
- sd.baseline = [det1, det2, det3, motor1, motor2]
注意:我们在这个礼拜中混合放入了探测器和电机。某些时可移动的而某些时不可移动的,这对于bluesky没有关系,因为它仅打算读取它们,而探测器和电机都是可以被读取的。
使用
现在我们对主要感兴趣的探测器和电机进行一个扫描。RunEngine将在每次run前后获取baseline读取。演示:
- rom ophyd.sim import det, motor
- from bluesky.plans import scan
- RE(scan([det], motor, -1, 1, 5))
我们可以在任何时候清除或更新baseline探测器列表。
sd.baseline = []此外,这是bluesky设计真实付出的地方。通过从指令集(plans)分离执行器(RunEngine),应用全局配置而不需要单独更新每个计划变得简单。
访问baseline数据
如果你从我们的baseline扫描访问数据,你会认为baseline数据丢失了。
- header = db[-1]
- header.table()

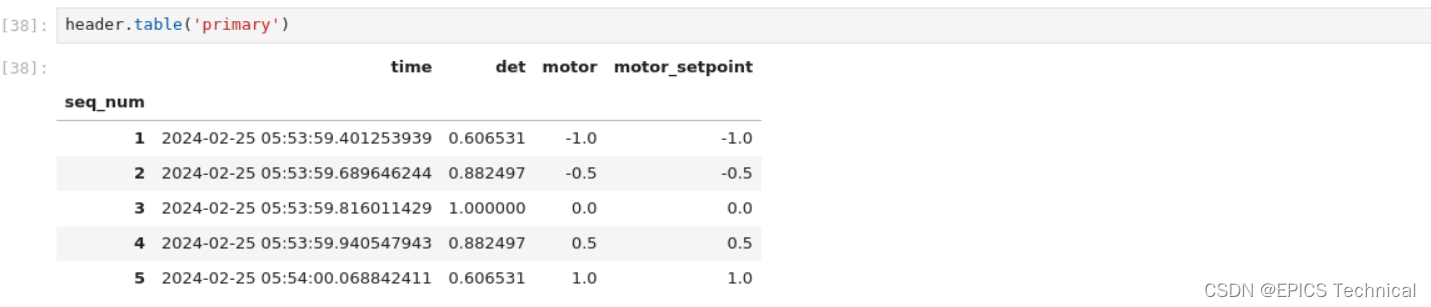
当我们执行这个扫描时,看一下输出,注意这些行:

默认,header.table()给我们"primary"数据流:
我们可以通过名称访问其他数据流:

在指定run中一个流名称的列表可以用header.stream_names获取。从这里,我们参考databroker教程。

其他补充数据
我们使用sd.baseline。也有用于信号的sd.monitors在一个run中异步监视和用于设备的sd.flyers在一个run中"飞行扫描"。详细见补充数据。
-
相关阅读:
Swift 面试题及答案整理,最新面试题
motion planing相关
哭了,我终于熬出头了,Java开发4年,费时8个月,入职阿里,涨薪14K
useState与useEffect
判断DataFrame中是否存在具有相同内容的行将具有相同内容的行进行标记和处理
昔日红极一时,如今重出江湖,这种按键位要怎么设计
在线零售多用户多门店连锁商城系统
Vue3应用API——设置全局属性(app.provide与app.config.globalProperties的区别)
LeetCode 剑指 Offer II 091.粉刷房子 - 原地修改
QT--对象模型(对象树)
- 原文地址:https://blog.csdn.net/yuyuyuliang00/article/details/136277151
