-
kafka生产者2

1.数据可靠
• 0:生产者发送过来的数据,不需要等数据落盘应答。

风险:leader挂了之后,follower还没有收到消息。。。。
• 1:生产者发送过来的数据,Leader收到数据后应答。
风险:leader应答完成之后,还没有开始同步副本。。。。

生产者发送过来的数据,Leader和ISR队列里面 的所有节点收齐数据后应答。
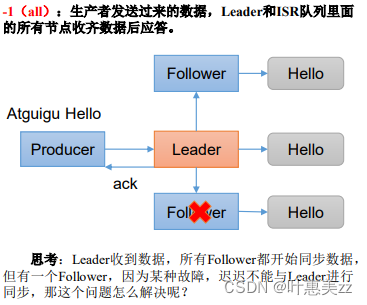

可靠性总结: acks=0,生产者发送过来数据就不管了,可靠性差,效率高; acks=1,生产者发送过来数据Leader应答,可靠性中等,效率中等; acks=-1,生产者发送过来数据Leader和ISR队列里面所有Follwer应答,可靠性高,效率低; 在生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据, 对可靠性要求比较高的场景。
- // 设置 acks
- properties.put(ProducerConfig.ACKS_CONFIG, "all");
- // 重试次数 retries,默认是 int 最大值,2147483647
- properties.put(ProducerConfig.RETRIES_CONFIG, 3);
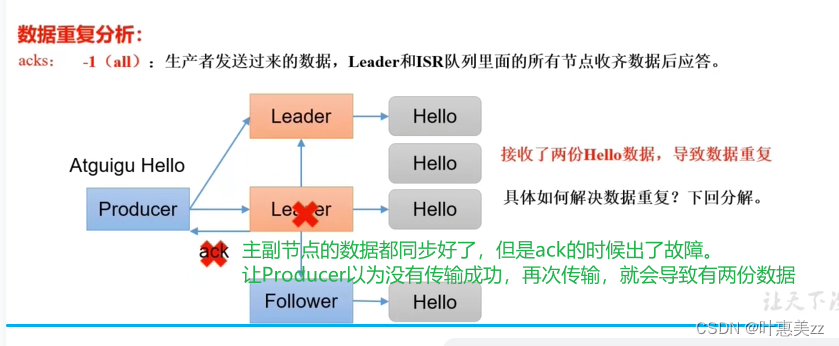
2.数据去重


3.生产者事务
说明:开启事务,必须开启幂等性。

- package com.atguigu.kafka.producer;
- import org.apache.kafka.clients.producer.KafkaProducer;
- import org.apache.kafka.clients.producer.ProducerConfig;
- import org.apache.kafka.clients.producer.ProducerRecord;
- import java.util.Properties;
- public class CustomProducerTransaction {
- public static void main(String[] args) {
- // 1. 创建 kafka 生产者的配置对象
- Properties properties = new Properties();
- // 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
- properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
- "hadoop100:9092");
- // key,value 序列化(必须):key.serializer,value.serializer
- properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
- "org.apache.kafka.common.serialization.StringSerializer");
- properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
- "org.apache.kafka.common.serialization.StringSerializer");
- properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"tranactional_id_01");
- // 3. 创建 kafka 生产者对象
- KafkaProducer
- KafkaProducer
- kafkaProducer.initTransactions();
- kafkaProducer.beginTransaction();
- // 4. 调用 send 方法,发送消息
- try{
- for (int i = 0; i < 5; i++) {
- kafkaProducer.send(new
- ProducerRecord<>("first","atguigu " + i));
- int i1 = 1 / 0;
- }
- kafkaProducer.commitTransaction();
- }catch (Exception e){
- kafkaProducer.abortTransaction();
- }finally {
- // 5. 关闭资源
- kafkaProducer.close();
- }
- }
- }
4.数据乱序


5.副本
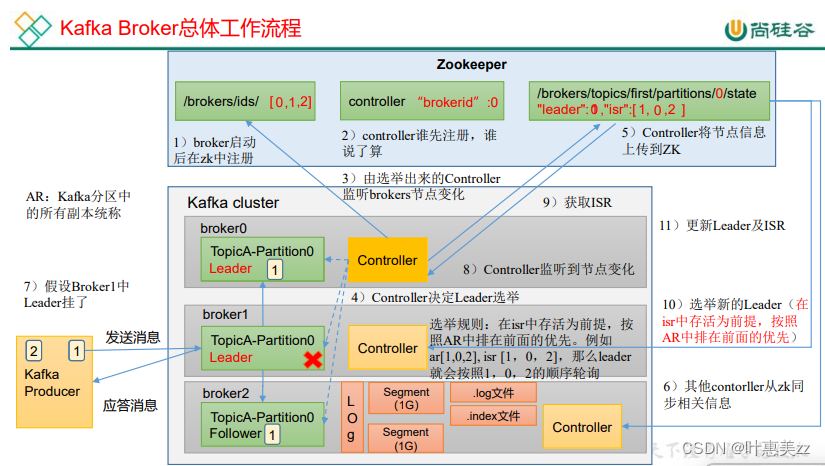
Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader, 然后 Follower 找 Leader 进行同步数据。
Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。
AR = ISR + OSR
ISR表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送 通信请求或同步数据,则该 Follower 将被踢出 ISR,进入OSR。该时间阈值由 replica.lag.time.max.ms 参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
OSR,表示 Follower 与 Leader 副本同步时,延迟过多的副本。
6.leader选举流程

在ISR中存活为前提,按照 AR中排在前面的优先。假设broker1挂了,isr数组中的1会被抹去。按照isr中的存活前提,AR中按照优先顺序来选举新的leader。

7.follow故障处理

8.leader故障处理


9.自动平衡

10.后续增加副本

-
相关阅读:
Cython 笔记 (Python/Jython)
ubuntu安装ffmpeg4.2
APISpace 手机号码归属地API 方便好用
HTML+CSS+JS:实现两张图片相互切换1.0
TCP三次握手和四次挥手
Linux实用操作(固定IP、进程控制、监控、文件解压缩)
工作学习记录
一辆新能源汽车的诞生之旅:比亚迪常州工厂探营
【前端开发】JS Vue React中的通用递归函数
微信小程序开发15 项目实战 基于云开发开发一个在线商城小程序
- 原文地址:https://blog.csdn.net/aaaa1234561/article/details/136268869
